


What is an ETL?
ELT stands for Extract, Load, Transform. It is a process in which data is first extracted from a source, then loaded into a target system (such as a data warehouse), and finally transformed within that system (e.g., applying calculations, changing data types) to make it ready for analysis or reporting.
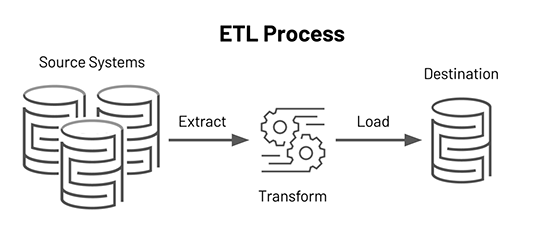
Extract:
Data is pulled from various source systems such as databases, files, APIs, or applications. These sources can be in different formats and from different platforms.
Transform
The raw data is cleaned, standardized, formatted, and calculations or business logic are applied to make it suitable for analysis.
Load
The transformed data is then loaded into a target system like a data warehouse, where it becomes available for querying, reporting, and advanced analytics.
In modern data architecture, ETL plays a crucial role in preparing data for Business Intelligence (BI), Machine Learning, and Data Visualization.
Why Do We Need ETL?
As businesses grow and generate massive amounts of data across various platforms, ETL becomes essential to:
- Combine data from multiple sources: Different departments may store data in different formats and systems. ETL unifies this data into a single source of truth
- Clean and standardize data: Ensures consistency and quality by transforming values, fixing errors, and applying business logic
- Enable better business decisions: Prepares data in a format that is easily usable for dashboards, KPIs, and business analysis
- Improve data security and governance: Provides a safe and controlled environment for moving and storing data while maintaining privacy and compliance
Basic ETL Workflow
Let’s walk through the three main stages of a typical ETL pipeline:
1. Extract
The goal of this phase is to retrieve data from different sources, including:
- Relational databases (e.g., MySQL, SQL Server)
- Cloud services (e.g., AWS, Azure)
- APIs
- CSV, Excel, or flat files
Key actions in this stage:
- Handle multiple data formats (JSON, XML, CSV, etc.)
- Extract data manually, on a schedule, or through automated pipelines/APIs
- Store extracted data temporarily in a staging area, ensuring its completeness, format integrity, and source traceability
2. Transform
In this stage, the raw data undergoes various operations to make it suitable for analysis:
- Data cleansing: Remove duplicates, nulls, and incorrect values
- Standardization: Align different formats, e.g., converting date formats or units
- Business logic: Apply custom rules like tax calculations, currency conversions, or KPI derivations
- Data mapping: Match columns and data types across sources for uniformity
This stage ensures that data is not only consistent but also enriched to support meaningful insights.
3. Load
Finally, the clean and transformed data is:
- Loaded into a data warehouse or data lake (e.g., Snowflake, Redshift, BigQuery)
- Indexed and partitioned for fast querying
- Used for reporting dashboards, analytics tools, or machine learning pipelines
This step may also include error handling, duplicate prevention, and logging to ensure traceability and auditability.
What is ETL testing?
ETL testing ensures that data integrity, quality, and accuracy are maintained throughout the ETL pipeline. It verifies that:
- All data from the source is correctly extracted
- Transformations are accurate and follow business rules
- Loaded data is complete and usable in the target system
Without proper ETL testing, organizations risk making decisions based on incomplete, inconsistent, or incorrect data.
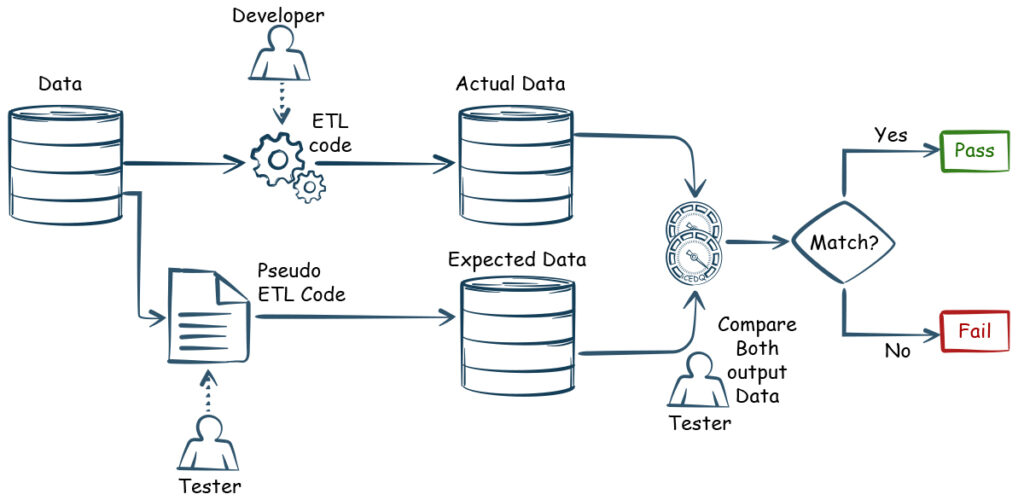
ETL testing process
Here’s how a standard ETL testing process typically unfolds:
1. Identify Business Requirements
Understand what data needs to be processed and how it will be used. Collaborate with stakeholders to define KPIs, transformation rules, and success criteria.
2. Validate Source Data
- The correct data is being pulled from each source
- The number of rows and data types match expectations
- Primary and foreign keys are correctly referenced
3. Design Test Cases
- Create ETL mapping documents
- Define test conditions for each transformation rule
- Write SQL scripts or use ETL testing tools for automation
4. Execute ETL Tests
- Run tests on each step: extract, transform, and load
- Validate row counts before and after transformations
- Check transformation logic is applied correctly
5. Verify Transformation Logic
- Ensure the final data reflects the required business rules
- Check that formatting, unit conversion, and calculations are correct
6. Verify Data Loading
- Confirm that all expected data has reached the destination
- Check for missing records, duplicates, or incorrect field values
- Validate default values are correctly assigned
7. Create Summary Reports
- Report test outcomes, success rates, and any anomalies
- Include screenshots, SQL scripts, and error logs for transparency
8. Test Closure
- Final sign-off from stakeholders
- Archive test artifacts for compliance and audits
- Plan for regression testing during future changes
Best Practice
- Backup data before loading: Ensure that all existing data is backed up before initiating the loading process into the production environment to prevent accidental data loss
- Define test cases for each step of the ETL process (Extract, Load, Transform)
- Understand requirements and prepare the correct test data to reduce challenges: Thoroughly review business and technical requirements to prepare appropriate and comprehensive test data. This reduces the chances of misalignment and minimizes challenges during testing
- Monitor ETL jobs to ensure that the loads are performed as expected
- Integrate incremental data: Only changed records are processed, improving scalability and reducing refresh time
- Validate data mapping: Ensure that data is mapped and transformed accurately, with no data loss. Confirm that the transformed data is correctly loaded into the data warehouse as per the defined schema and business rules
Conclusion
The ETL (Extract, Transform, Load) process is fundamental to ensuring that organizations can harness the full value of their data. By extracting data from diverse sources, transforming it into a consistent and usable format, and loading it into centralized systems, ETL enables reliable reporting, analytics, and decision-making.
Effective ETL processes not only streamline data integration but also uphold data quality, consistency, and governance. ETL testing plays a critical role in this ecosystem by validating every step—from source extraction to final loading—ensuring the data is accurate, complete, and aligned with business goals.
Reference:
https://www.nitorinfotech.com/blog/best-practices-of-etl-testing/
https://www.guru99.com/etl-developer-job-description.html