



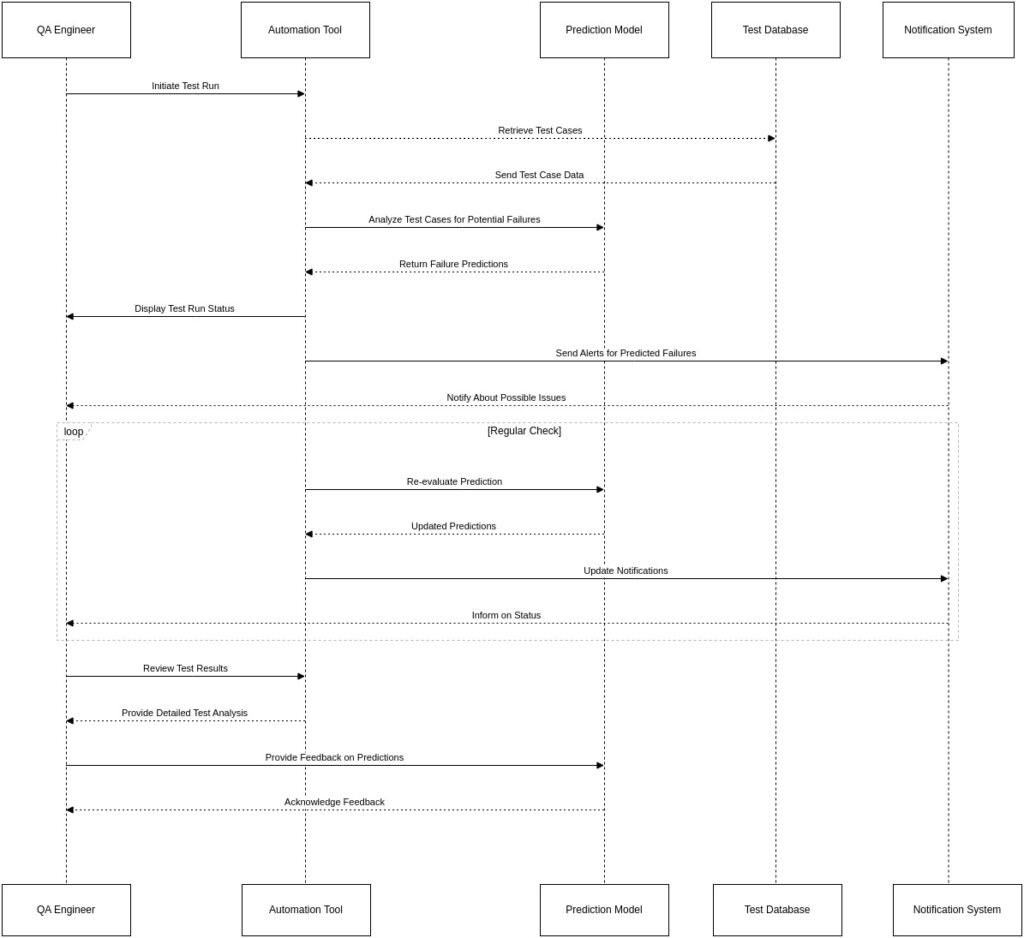
Automatic testing framework with the inclusion of machine learning (ML) in the rapidly changing area of software testing is becoming more intelligent. Before predicting the failures of the test case, they are a significant use for predicting failure in test automation. This method enables teams to maintain strong CI/CD pipelines, saving time and money.
Tools such as Selenium have empowered teams to automate browser-based tests, enabling CI/CD pipelines to quickly detect issues. But what if we can just go beyond the trials that run and predict failures before they happen? This is the place where the failure of failure in test automation enters the platform powered by machine learning (ML). But the quality of a model depends on the quality of the data it is trained on. In this blog, we will detect the required stages involved in labelling and training data to predict failure with a practical lens on selenium-based test automation.
But like any machine learning model, the label and finished training data are important for precise failure prediction. In addition to going over a sample workflow with diagrams, this post will discuss how to properly train the model for future automation and label test failures.
Why Predict Failures in Test Automation
Test failures often make noise. There are some real bugs, other flaky tests, environmental issues, or UI changes that are not properly handled in the script. By estimating which tests are likely to fail, you can:
- Prefer test execution
- Identify flaky tests quickly
- Reduce noise in reporting
- Customise debugging and triage
To build such models, you need to accurately label data and extract meaningful features from your test execution.
Labelling Data
The foundation of supervised machine learning is labelled data. In terms of selenium automation, labelling means tagging historical test execution with results.
Before labelling or modelling, let’s get acquainted with common selenium failure types:
| Failure Type | Description |
| ElementNotFoundException | Locator not found in the DOM — often due to UI changes |
| TimeOutException | Element took too long to appear or page load timed out |
| StableElementReferenceException | DOM refreshed and old element reference is invalid |
| SessionNotCreatedException | Browser launch or driver mismatch issues |
| AssertionError | Business logic mismatch in assertions |
| Network/Backend Failures | API not responding or backend services down |
| Script Errors | Bugs in the test script itself |
Each of these failure types has different implications and requires separate handling. Therefore, it is important for labelling to capture them correctly.
Example Labels:
- PASS
- FAIL – ELEMENT NOT FOUND
- FAIL – TIMEOUT
- FAIL – FLAKY
- FAIL – ASSERTION
- SKIPPED
How To Label Test Failures:
- Parse Test Report: Extract data from tools such as Allure, TestNG, JUnit, or CI platforms (e.g., Jenkins).
- Capture the log and stack mark: These are necessary to identify the root causes.
- Class exceptions: Use pattern matching or log parsing (Regex/ML-based) to map the stack mark for failure categories.
- Tag manually where needed: especially for flaky or unclear failures, some manual tagging is required.

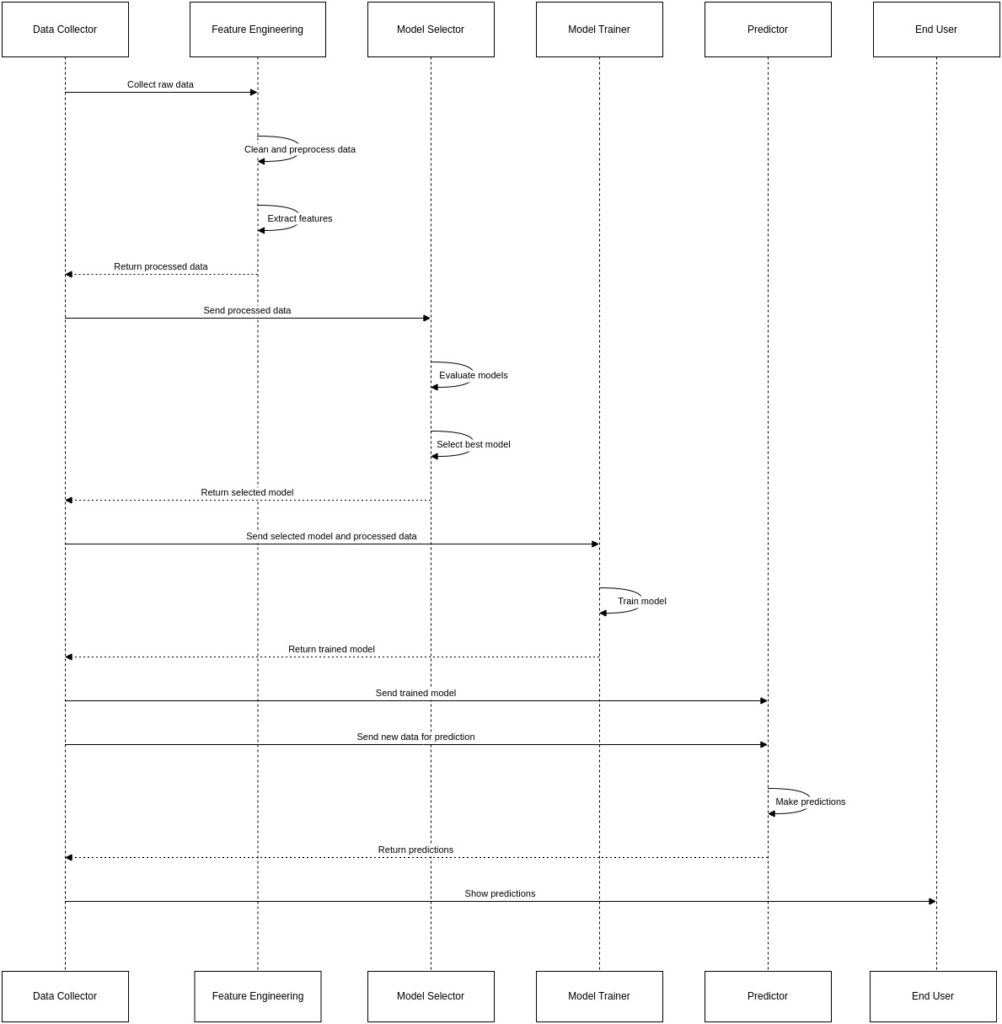
The Machine Learning Pipeline
Once you have enough large and well-labelled datasets of previous test failures, you can start the process of training the machine learning model. There is a simplified observation of the steps involved here:
- Feature Engineering: This is the process of extracting meaningful features from your raw data that can learn from. For predicting test failure, your features may include:
- Specific test case that failed.
- The browser and operating system it was run.
- The type of selenium exception thrown.
- Text of error message.
- Information about recent code commits.
- Historical failure rate of the test case.
- Model Selection: There are various machine learning algorithms suitable for this task. Some popular choices include:
- Naive Bayes: For classification jobs, a straightforward and efficient method.
- Support Vector Machines (SVM): A powerful algorithm that can find complex relationships in the data.
- Random Forest: An ensemble approach that lessens overfitting and increases accuracy by combining several decision trees.
- Neural Networks: For more complex scenarios with large datasets, deep learning models can be highly effective.
- Training and Evaluation: The labelled dataset is divided into a training set and a test set. The model learns from training data and is then evaluated on unseen test data to assess its performance.
- Prediction and Integration: Once the model is trained and performs well, it can be integrated into your CI/CD pipeline. Before a test suite is executed, the model may predict the possibility of failure for each test case based on the current reference (e.g., recent code change).
Challenges and Considerations
While the capacity is immense, it is important to accept challenges. The construction and maintenance of a high-quality label dataset requires a consistent and disciplined effort. The initial setup of a machine learning pipeline also requires specialisation in data science and MLOps. Start small by manually labelling your test failures.
As your dataset increases, you can start experimenting with simple machine learning models. The insight from a basic implementation can also be priceless. By embracing the power of predicting failure, you can transform your test automation into an active force for quality to quality, paving the way for the future of more flexible and reliable software.