


In Part 1: The Essential Foundations of Artificial Intelligence, we explored the deep academic roots of AI — spanning philosophy, logic, mathematics, neuroscience, and beyond. These foundational disciplines have shaped how we define intelligence, how we simulate reasoning, and how we build systems that attempt to “think.”
When I first started exploring the world of Artificial Intelligence, I’ll admit it—I struggled a bit. The sheer volume of new terms felt overwhelming! AI, Machine Learning, Deep Learning… They all sounded similar, seemed to overlap in strange ways, and often showed up in the same sentences, making it hard to figure out who was who.
That’s exactly why I wanted to write this piece:
I want to share the simple, friendly way I’ve come to understand these concepts over time. Think of this as my personal perspective—a lightweight mental that truly helped me make sense of everything when I was just starting out. By laying the ideas out more clearly and connecting them in a friendly, approachable way, I hope this gives you the same clarity I was looking for back then.
AI
AI stands for Artificial Intelligence, or Trí tuệ nhân tạo in Vietnamese. Throughout its development, researchers have explored AI from several different angles, and over time these approaches have generally been grouped into four major categories:
- Acting humanly – building systems that behave the way humans would in similar situations.
- Thinking humanly – modeling how humans reason, learn, and process information.
- Thinking rationally – using formal logic and reasoning to make decisions in an optimal way.
- Acting rationally – focusing on intelligent behavior that leads to the best possible outcome.
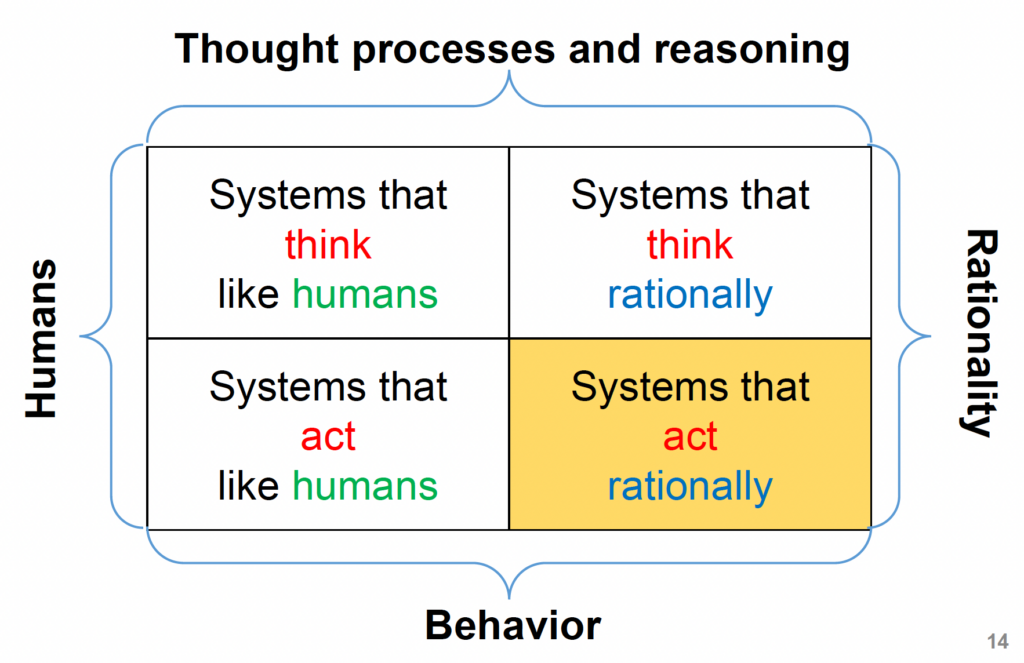
These four perspectives don’t compete with one another — instead, they offer different lenses for understanding what it means for a machine to be “intelligent.”
You’ve probably heard of the Turing Test before. Proposed by Alan Turing in 1950, it set out to answer a profound question: Can a machine demonstrate intelligence indistinguishable from a human?
The setup is straightforward:
There’s a human evaluator asking questions, a human participant answering them, and a machine responding as well. If the evaluator can’t reliably tell which responses come from the machine and which come from the human, the machine is considered “intelligent” under this framework. Over the decades, this human-like behavior approach has led to meaningful progress across several key areas:
- Natural Language Processing (NLP): Machines can now read, interpret, and communicate using natural human language.
- Knowledge Representation: Systems can store and structure knowledge gained through vision, audio, or text.
- Automated Reasoning: Machines can use stored knowledge to answer questions or draw useful conclusions.
- Machine Learning: Algorithms allow machines to adapt to their environment and extract patterns that support better decision-making.
- Computer Vision: Machines can perceive the world visually and recognize objects around them.
- Robotics: Intelligent systems can move through the physical world and interact with real-world objects.
Machine learning
If AI is the big, exciting goal of making machines smart, then Machine Learning (ML) is one of the most powerful tools we use to achieve that goal.
To start, let’s go straight to the source. According to Wikipedia, Machine Learning is the subfield of computer science that “gives computers the ability to learn without being explicitly programmed.” In simpler terms, it’s a branch of computer science that allows machines to learn patterns directly from data instead of relying on manually written rules. This ability to learn and adapt is what makes ML such a powerful building block within the broader landscape of AI.
Machine Learning is a broad and mathematically intensive field, made up of numerous algorithms — each designed for specific types of problems and real-world applications. Some of the major categories include:
- Supervised Learning – used for tasks like classification and regression, where the model learns from labeled examples.
- Unsupervised Learning – focused on discovering structure in unlabeled data, such as clustering or dimensionality reduction.
- Semi-supervised Learning – a hybrid approach that leverages both labeled and unlabeled data to improve accuracy when annotated data is limited.
- Self-supervised Learning – a rapidly growing area where the model generates its own labels by understanding patterns within the data itself.
- Reinforcement Learning – where an agent learns to make decisions through trial and error to maximize long-term rewards.
- Transfer Learning – reusing knowledge learned from one task to boost performance on another related task.
- Neural Networks and Deep Learning – using multi-layer architectures to capture complex, high-dimensional patterns — powering breakthroughs in vision, speech, and language.
The Name Refreshed: – Deep Learning (2010)
Though the idea of neural networks has been around for decades, the term that defines its current era—Deep Learning—was officially coined and gained traction around 2010. This wasn’t just a simple rebranding; it marked a crucial moment of renaissance and breakthrough in the field.
This wasn’t just a simple rebranding; it marked a crucial moment of renaissance and breakthrough in the field. After years of being overshadowed by other machine learning techniques (like Support Vector Machines, which were easier to train), researchers developed new architectural tricks and clever initialization techniques (like pre-training) that finally allowed them to effectively train neural networks with many layers.
This ability to train truly deep networks—networks that could stack multiple levels of abstraction—is what separated this new wave of research from the older, shallower networks.
But that raises a big question: Why has Deep Learning made such a massive splash? Why is everyone—from researchers to engineers to entire companies—pouring time and resources into it?
Why has Deep Learning made such a massive splash?
In recent years, as computing power has reached new heights and tech giants have accumulated massive amounts of data, Machine Learning has taken a huge leap forward.
Deep Learning has enabled machines to do things that would’ve sounded impossible just a decade ago — classifying thousands of objects in images, generating captions automatically, mimicking human voices and handwriting, carrying on conversations, and even creating stories or composing music. What once felt like science fiction is now shaping products we use every day. (You can also check out 8 Inspirational Applications of Deep Learning for more examples.)
Why is everyone — from researchers to engineers to entire companies — pouring time and resources into it?
We’ve established that Machine Learning (ML) is the powerful engine that learns rules from data. So if ML is already so effective, why is everyone—from Google to small startups—rushing to invest heavily in its subset, Deep Learning (DL)?
The answer is simple: Deep Learning is the key to solving the toughest, most human-like problems that traditional ML algorithms simply can’t handle. Here’s why it’s worth the massive investment:
1. The Magic of Automatic Feature Extraction
This is the biggest game-changer.
- Traditional ML: Before feeding raw data (such as images, text) into the model, humans had to perform feature engineering—that is, figure out which features were important. For example, to recognize a cat, you had to manually tell the machine “cats have pointy ears,” “have whiskers,” “have fur.” This was time-consuming, required high expertise
- Deep Learning: DL models, built with many layers (deep neural networks), have the ability to automatically extract and learn features directly from raw data. The first layers might learn simple edges and colors; deeper layers automatically combine those into complex shapes (like eyes, noses, or car wheels)—all without human intervention.
This self-learning capability liberates engineers and accelerates development incredibly fast.
2. Mastering Unstructured Data
Most of the data generated today is Unstructured Data (images, video, audio, text). Traditional ML struggles greatly with this raw, messy data.
- Deep Learning architectures (like CNNs for images and Transformers for text) are built specifically to process this data directly from the source—from pixels and raw characters.
- This power is why DL unlocked huge breakthroughs in fields requiring human-level perception:
- Computer Vision: Self-driving cars, medical image diagnostics.
- Natural Language Processing (NLP): Large Language Models (LLMs) like ChatGPT and Gemini are direct results of Deep Learning innovation.
3. Unbeatable Performance at Scale
Here’s a strategic advantage: While traditional ML models often hit a performance ceiling even with more data, Deep Learning model performance continues to climb when given access to colossal datasets (Big Data).
For major tech companies that generate and process petabytes of data daily, this scalable performance is critical. Deep Learning allows them to constantly improve their products and maintain a competitive edge that smaller firms cannot easily match.
In short, Deep Learning is the investment in solving the most abstract and complex problems in AI, turning what was once science fiction into practical, world-changing applications.
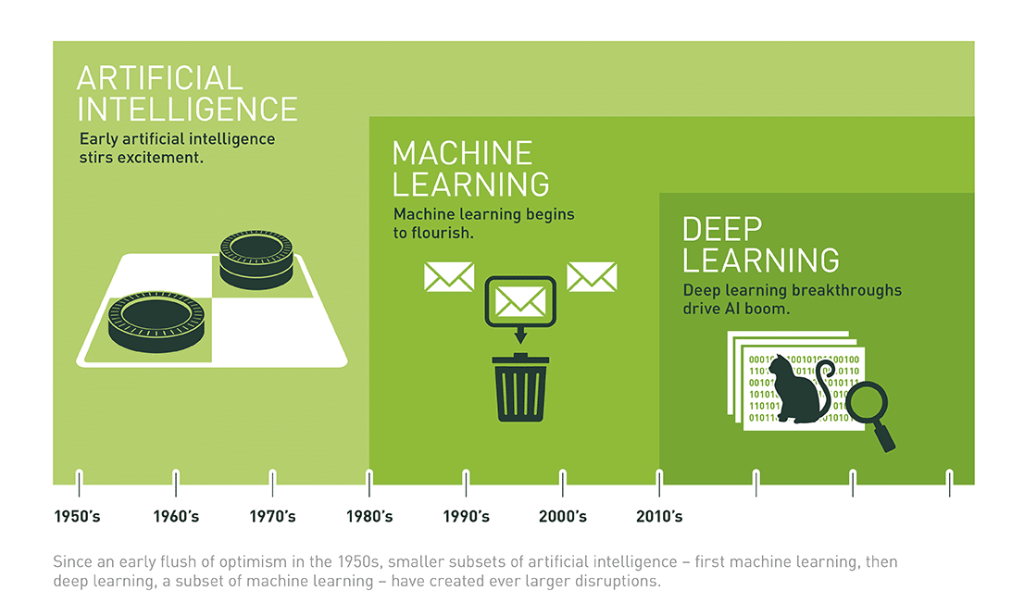
Source: https://www.nvidia.com/en-us/glossary/deep-learning/
⚖️ The Balance: Where Deep Learning Works Well and Where It Struggles
So, Deep Learning sounds like a magical solution, right? It can learn complex features and power world-class AI. But like any technology, it comes with a significant set of trade-offs. It’s crucial to understand when to use this heavy-duty tool and when to stick with something simpler.
✅ Deep Learning’s Superpowers (Where it works well)
When Deep Learning works, it truly dominates. Here’s where it shines:
- State-of-the-Art Performance: Deep Learning is the undisputed champion (the “state-of-the-art” method) in complex fields like Computer Vision (identifying objects in images) and Speech Recognition (transcribing audio). Deep Neural Networks deliver superior performance on massive datasets of raw images, audio, and text.
- Reduced Feature Engineering Cost: This is a huge advantage. The network’s hidden layers automatically handle the laborious task of extracting relevant features from raw data, saving data scientists immense amounts of manual effort.
- Adaptability: The fundamental architecture—the sequence and structure of layers—can often be adapted and applied across many different problem domains, from identifying cancer cells to translating languages.
- Continuous Improvement: Models can be easily updated with new data through methods like batch propagation, allowing systems to get smarter over time without a complete overhaul.
❌ The Deep Learning Weaknesses (Where It Falters)
Deep Learning is powerful, but it’s not a general-purpose solution. These are its major limitations:
- The Hunger for Data: DL is not a general-purpose algorithm because it demands a truly colossal amount of data for effective training. If you have a small dataset, a traditional ML model will often outperform a Deep Learning model significantly.
- Beaten by Basics: For many basic, structured Machine Learning tasks (like predicting credit risk or classifying simple tabular data), DL is often outperformed by simpler, more efficient algorithms like Tree Ensembles (e.g., Random Forest or XGBoost)
- High Resource Consumption: These models require enormous computational power (expensive GPUs/TPUs) and time to train. The cost barrier is substantial, making it inaccessible for small projects or limited budgets.
- The Tuning Challenge: Setting up an effective DL model requires significant expertise. Engineers must spend considerable time tuning hyper-parameters (like the number of layers, the nodes per layer, the learning rate, and the number of iterations) to get the best performance
The takeaway? Deep Learning is revolutionary for big, abstract problems involving unstructured data, but for many everyday tasks, a simpler, less resource-intensive ML tool is often the best and most cost-effective choice!
📚 Conclusion: Choosing the Right Tool Wisely
We’ve successfully demystified the “Big Three”—AI, Machine Learning, and Deep Learning. I hope this simplified model has given you greater clarity on how they connect: AI is the grand goal, Machine Learning is the primary engine to reach that goal, and Deep Learning is the superpower version of that engine, designed for the most complex problems.
The massive investment in Deep Learning is not hype; it’s a strategic move. It unlocks unprecedented possibilities with unstructured data, but it requires significant trade-offs in terms of resources and data volume.
Next Blog: Categorizing Machine Learning Algorithms
In the next blog post, we are going to dive deeper into how Machine Learning models actually learn.
Have you ever wondered how one model learns to classify images (e.g., this is a cat) while another model only tries to group customers together (without knowing the answer beforehand)?