


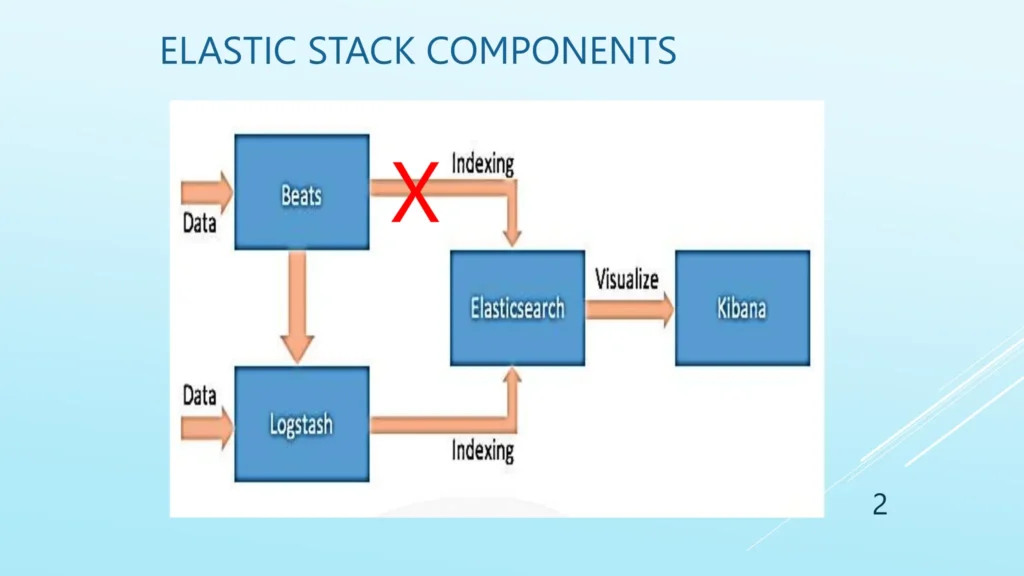
- Elasticsearch : It is the backbone that indexes and stores massive volumes of structured and unstructured data, enabling ultra-fast search and analytics.
- Logstash : It is used to collects, parses, transforms, and forwards data from various sources, providing a flexible data processing pipeline.
- Kibana : It is used for the data visualization and dashboarding.
- Beats : These are lightweight agents that collect and ship data (logs, metrics, events, etc.) from servers and endpoints to Logstash or Elasticsearch.


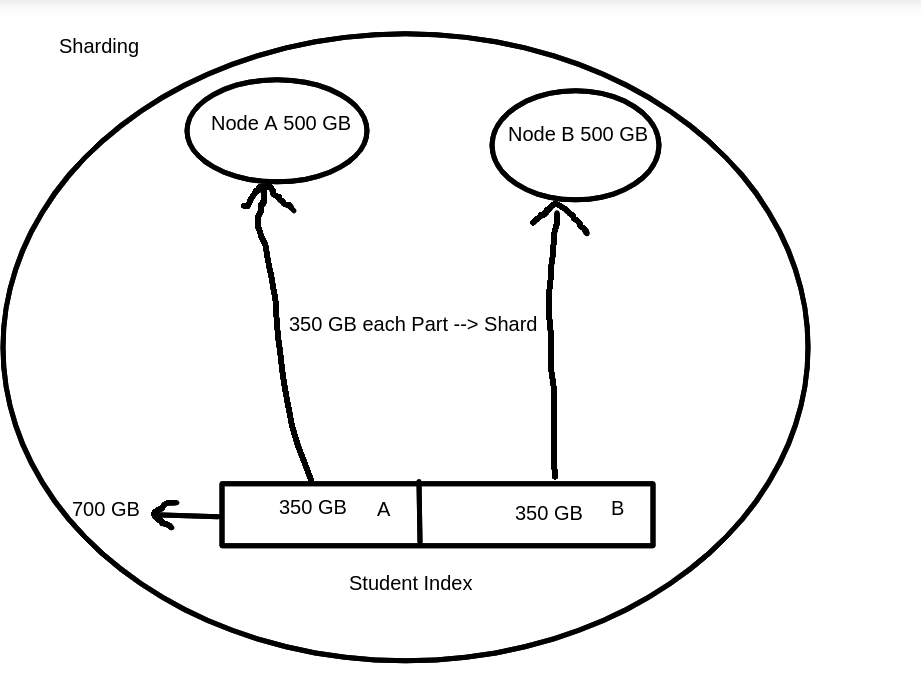
Shard : Sharding is a way to divide indices into smaller pieces. Each piece is called as Shard. Sharding is done on index levels.
Example :
You have a Student index with 700GB of data. You want to store this across two new nodes, each with 500GB storage.
1. Create/Plan Your Nodes
You set up 2 nodes in your Elasticsearch cluster (Node A and Node B).
Each node has enough space (500GB each).
2. Split Data into Shards
Instead of storing all 700GB on one node, you break the index into shards.
In this scenario, you could split the Student index into 2 shards:
Shard 1: ~350GB
Shard 2: ~350GB
3. Allocate Shards to Nodes
Store Shard 1 on Node A, Shard 2 on Node B.
Elasticsearch will automatically balance the shards, making sure the data and queries are spread across available nodes.
There is two types of Shards :
- Primary Shard : It will contains the original data Segements.
- Replica Shard : A copy of a primary shard, providing redundancy and improving query performance.
Note : Replica shards must be located on a different node than their corresponding primary shards. The reason is: if both the primary and its replica are stored on the same node and that node goes down (due to hardware failure, maintenance, network issues, etc.), you would lose both copies of the data for that shard. This results in data loss and defeats the entire purpose of replication for fault tolerance and high availability.