


Part 1 of 4 in our Apache Kafka Rebalancing Series
For experienced developers building streaming applications, Kafka’s consumer rebalancing mechanism represents both a critical coordination feature and a potential reliability bottleneck. Understanding the evolution from “stop-the-world” eager rebalancing to incremental cooperative protocols is essential for building resilient production systems that maintain high availability during consumer group changes.
Modern Kafka offers three distinct rebalancing approaches, each addressing different scalability and performance challenges. The choice between these protocols can mean the difference between seconds of processing interruption versus complete system unavailability during routine operations like deployments or scaling events.
What exactly is rebalancing?
Kafka rebalancing occurs when consumer group membership or partition metadata changes, requiring redistribution of partition assignments across active consumers. Every topic partition must have exactly one consumer within a group, making rebalancing essential for maintaining balanced load distribution and ensuring no messages are lost or duplicated.
Rebalancing triggers include consumer joins (new instances starting), consumer leaves (graceful shutdowns), consumer failures (session timeouts), and metadata changes (new partitions added to subscribed topics). In dynamic environments like Kubernetes, these events happen frequently, making rebalancing performance crucial for application reliability.
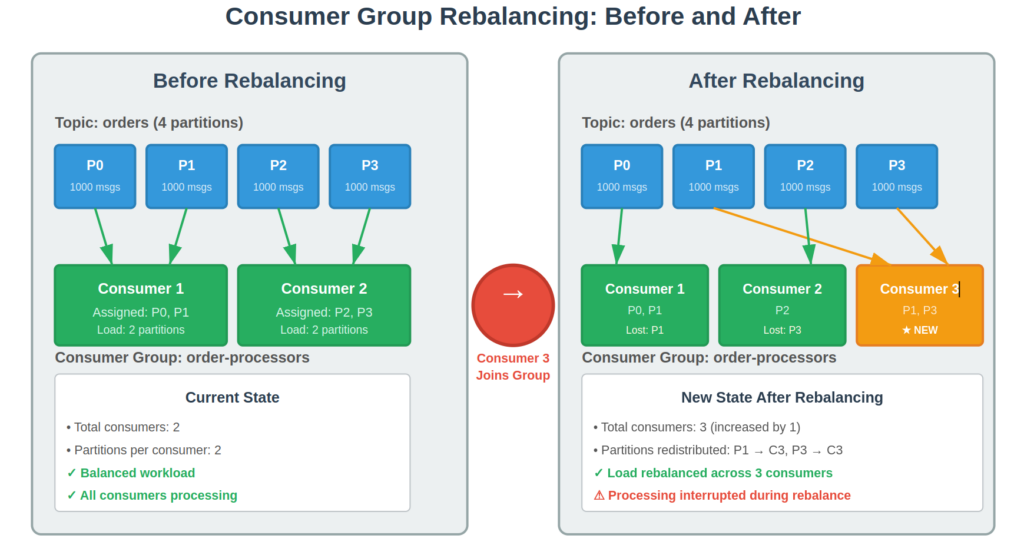
The coordination process involves the group coordinator (a designated Kafka broker) managing consumer group state and orchestrating partition assignment changes. Understanding how different protocols handle this coordination is key to optimizing rebalancing performance.
The evolution: From eager to cooperative
Eager rebalancing: The stop-the-world approach
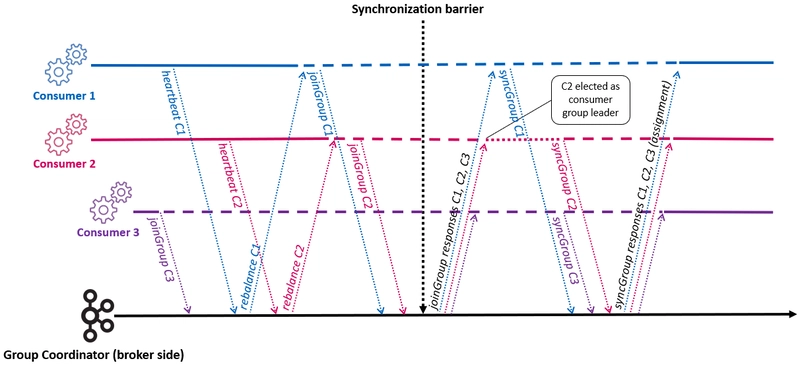
Traditional eager rebalancing follows a two-phase synchronization barrier where all consumers halt processing during reassignment. This approach guarantees consistency but creates complete throughput loss during rebalancing operations.
The process works through precise coordination steps:
- Trigger detection: Coordinator detects membership changes or metadata updates
- Revocation phase: All consumers immediately revoke ALL assigned partitions
- JoinGroup phase: Consumers send join requests; coordinator selects group leader
- Assignment calculation: Leader computes new assignments using configured strategy
- SyncGroup phase: Coordinator distributes new assignments to all members
- Resume processing: Consumers begin processing their newly assigned partitions
// Eager rebalancing behavior - simplified view
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
// ALL partitions revoked, even those staying with same consumer
log.info("Revoking ALL {} partitions - processing STOPS", partitions.size());
commitSync(); // Ensure clean state before rebalancing
}
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
log.info("Assigned {} partitions - processing RESUMES", partitions.size());
// Consumers can now resume processing
}
Performance impact: Confluent benchmarks show eager rebalancing creates 37,138ms total pause time for large consumer groups, with 100% throughput loss during coordination phases.
Cooperative rebalancing: Incremental improvements
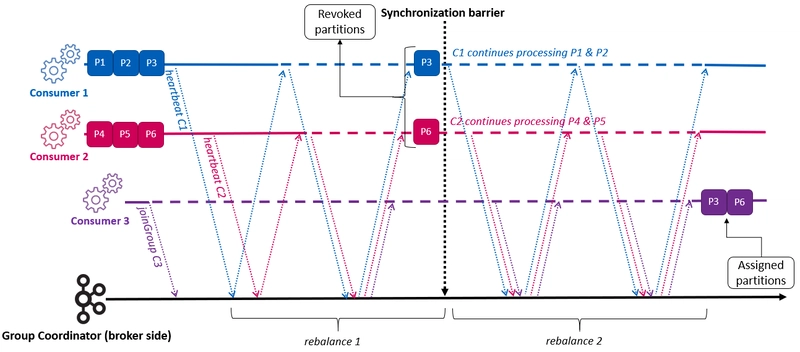
Introduced in Kafka 2.4, incremental cooperative rebalancing eliminates stop-the-world behavior through selective partition transfers. Only partitions requiring reassignment are revoked, allowing unaffected consumers to continue processing throughout the operation.
The cooperative protocol implements a multi-round incremental approach:
- Round 1: Consumers join while retaining current partitions
- Selective revocation: Only partitions needing reassignment are revoked
- Round 2+: Revoked partitions assigned to new owners
- Convergence: Process repeats until optimal assignment achieved
// Cooperative rebalancing behavior
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
// Only partitions being reassigned are revoked
log.info("Revoking {} partitions for reassignment", partitions.size());
// Other partitions continue processing normally
commitSync(partitions); // Only commit revoked partitions
}
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
log.info("Assigned {} new partitions", partitions.size());
// Existing partitions were never interrupted
}
Performance improvement: Cooperative rebalancing delivers 90% or more reduction in processing pause time compared to eager protocols, with minimal impact on unaffected partitions.
Next-generation server-side coordination
Kafka 4.0 introduces revolutionary server-side coordination that moves complexity entirely from clients to brokers. This represents the most significant advancement in consumer group management since Kafka’s inception.
The new architecture uses a three-epoch system for state tracking:
- Group epoch: Overall consumer group generation
- Assignment epoch: Partition assignment version
- Member epoch: Individual consumer state version
Instead of complex client-side leader election and assignment calculation, the group coordinator drives the entire process using server-side assignors and declarative target states. Each member independently reconciles their current assignment against the coordinator’s target assignment, eliminating group-wide synchronization barriers.
// Next-generation protocol - unified API
// Single ConsumerGroupHeartbeat replaces JoinGroup/SyncGroup/Heartbeat
ConsumerGroupHeartbeatRequest request = new ConsumerGroupHeartbeatRequest()
.setGroupId(groupId)
.setMemberEpoch(currentEpoch)
.setCurrentAssignment(currentPartitions);
// Server responds with target assignment
// Client reconciles asynchronously - no coordination delays
Scalability breakthrough: Performance benchmarks show 20x improvement in rebalancing speed – scaling from 100 to 1000 partitions takes 5 seconds versus 103 seconds with classic protocols.
Performance impact comparison
| Protocol | Throughput Impact | Coordination Time | Scalability |
|---|---|---|---|
| Eager | 100% loss during rebalance | 37+ seconds | Poor (100+ consumers) |
| Cooperative | 10-30% impact on reassigned partitions | 3-8 seconds | Good (hundreds) |
| Server-side | 5-10% impact | <5 seconds | Excellent (thousands) |
When to use each protocol
Choose eager rebalancing when:
- Legacy compatibility required with older Kafka versions (<2.4)
- Simple assignment logic with homogeneous consumer processing
- Small consumer groups (<10 consumers) where coordination overhead is minimal
- Infrequent rebalancing in stable environments
Choose cooperative rebalancing when:
- Production systems requiring high availability during deployments
- Large consumer groups (10-100+ consumers) with frequent membership changes
- Stateful processing where partition reassignment is expensive
- Kubernetes/containerized environments with rolling updates
Choose server-side coordination when:
- Kafka 4.0+ available with massive scalability requirements
- Very large consumer groups (100+ consumers, 1000+ partitions)
- Complex assignment strategies requiring server-side optimization
- Multi-tenant environments requiring centralized coordination control
Configuration essentials
// Cooperative rebalancing configuration
Properties props = new Properties();
props.put("group.id", "my-consumer-group");
props.put("partition.assignment.strategy",
"org.apache.kafka.clients.consumer.CooperativeStickyAssignor");
// Migration strategy - supports both protocols during transition
props.put("partition.assignment.strategy",
"cooperative-sticky,sticky,range");
// Next-generation protocol (Kafka 4.0+)
Properties props = new Properties();
props.put("group.protocol", "consumer"); // Enable new protocol
props.put("group.remote.assignor", "server-side-assignor-name");
// Many client-side configs become server-controlled
Key takeaways
Protocol selection fundamentally determines application availability during consumer group changes. Cooperative rebalancing should be the default choice for production systems, providing 90% reduction in processing interruption with minimal configuration changes.
Server-side coordination represents the future of Kafka consumer groups, offering unprecedented scalability for large distributed systems. Early adoption of Kafka 4.0 features positions applications for the next generation of streaming architecture requirements.
Understanding these protocol differences enables informed architectural decisions that prevent the rebalancing storms and cascading failures common in production Kafka deployments.
Next in this series: Part 2: Common Rebalancing Problems and Debugging – We’ll explore systematic approaches to diagnosing and resolving the most frequent rebalancing issues encountered in production environments.
Find this helpful? The complete 4-part series covers protocols, debugging, optimization, and monitoring strategies for mastering Kafka consumer rebalancing.
References
- Rebalancing strategy images: https://dev.to/pierregmn/kafka-rebalancing-impact-on-kafka-streams-consumers-performances-12dn
- Diagrams and illustrations created using Claude AI