



Idempotency in Modern Software Systems: Why It Matters and How We Apply It in Real Projects
Summary:
Idempotency ensures that repeated operations do not create unintended side effects. This principle is widely adopted in APIs, backend systems, integration pipelines, and distributed systems. This article explains the concept, gives detailed industry practices, and highlights how we apply it in internal projects.
1. General Introduction: What Is Idempotency?
Modern systems often face issues like repeated requests due to:
- Network instability
- User double-clicking buttons
- Frontend retries
- Timeouts from API Gateway or Load Balancers
- Background job retries
Without safeguards, these can cause double inserts, duplicated records, and corrupted business data.
Idempotency ensures:
“Executing the same action multiple times will always produce the same end state.”
This idea is widely used in:
- Payment APIs
- Document upload systems
- Microservice communication
- Message queues and event-driven systems
- Database transactions
2. Why It Matters for Non-Technical Teams
Idempotency helps the organization by:
- Preventing duplicated business data
- Ensuring stable reporting and KPI dashboards
- Making customer-facing interactions more reliable
- Minimizing high-severity production defects
- Supporting predictable workflows
Although technical, the benefits impact everyone—from sales to operations to finance.
3. Common Solutions Programmers Use (Industry Practices)
This section dives deeper into widely used techniques, when to use them, their benefits, and limitations.
✔ 1. Idempotency Key (Client-Generated or Server-Generated)
Concept:
The client attaches a unique key (GUID) to the request.
If the same key is submitted again, the server returns the previous result.
Example:
POST /payments
Idempotency-Key: 7f2a-91cd-44a1Pros:
- Highly reliable for POST operations
- Prevents duplicate inserts
- Good for API Gateway and microservices
Cons:
- Requires database or distributed cache to store keys
- Client must generate and manage the key
Best used when: payment submission, file uploads, checkout processes, or long-running API calls.
✔ 2. Database-Level Unique Constraints (Strongest Guarantee)
Concept:
Use constraints like:
PRIMARY KEYUNIQUE INDEXUNIQUE(CONSTRAINT)
The database itself rejects duplicate data.
Pros:
- Strongest protection
- No backend logic needed
- Works even under heavy concurrency
Cons:
- Requires well-defined business keys
- Error messages need to be handled gracefully
Best used when: customer codes, item codes, invoice numbers, transaction IDs, or unique reference numbers.
✔ 3. UPSERT / MERGE Pattern (Insert or Update)
Concept:
If a record exists → update
Else → insert
Example SQL:
MERGE INTO Orders AS T
USING (SELECT @OrderID AS OrderID) AS S
ON T.OrderID = S.OrderID
WHEN MATCHED THEN UPDATE SET ...
WHEN NOT MATCHED THEN INSERT (...)Pros:
- Eliminates duplicated INSERT logic
- Good for sync jobs or batch imports
Cons:
- Not suitable for operations that must only INSERT
Best used when: syncing external data, upserting configuration tables.
✔ 4. Background Job & Worker Deduplication
Concept:
Jobs store a hash or job key in Redis/Memcached to avoid reprocessing.
Pros:
- Works well in distributed job runners
- Simple and fast
Cons:
- Requires cache expiration strategy
Best used when: scheduled sync jobs, queue message handlers.
✔ 5. Message Queue Acknowledgement and Offset Tracking
Concept:
Systems like Kafka or RabbitMQ track:
- ACK (success)
- NACK (retry allowed)
- Offset (last processed message)
Pros:
- Built-in fault tolerance
- Automatic retry without duplication
Cons:
- Requires infrastructure support
Best used when: event-driven systems, notifications, data pipelines.
✔ 6. Optimistic Concurrency Control (Version Control)
Concept:
Row includes Version or Timestamp.
When updating, compare the version to avoid conflicts.
Pros:
- Prevents overwriting by repeated updates
- Great for high-concurrency systems
Cons:
- Not an INSERT guard—only protects UPDATE operations
✔ 7. Stored Procedure Business Key Checking
Concept:
The stored procedure checks if a record exists before inserting.
Example:
IF NOT EXISTS (SELECT 1 FROM Orders WHERE OrderNo = @OrderNo)
BEGIN
INSERT ...
ENDPros:
- Simple and easy to apply in legacy systems
Cons:
- Race conditions can still happen without a unique index
4. Applying Idempotency in Our Project
In our modernization project, even though not everyone in the company interacts with it directly, idempotency plays an important role in stabilizing legacy modules.
We encountered issues such as:
- Document uploads being retried → duplicate inserts
- APIs executed twice due to user behavior
- Double execution of stored procedures during sync jobs
We mitigated these by applying
- Idempotency keys for important POST APIs
- Unique database constraints
- Business key validations inside stored procedures
- Refactoring handlers to detect repeated requests
5. Simple Diagram
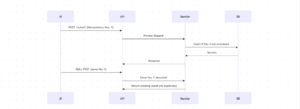
6. Sample Code Example
public async Task<Result> Handle(SubmitCommand request)
{
var exists = await _db.IdempotentRequests
.AnyAsync(x => x.Key == request.IdempotencyKey);
if (exists)
return Result.Success("Already processed");
await _db.DataTable.AddAsync(new DataItem { ... });
await _db.IdempotentRequests.AddAsync(
new IdempotentRequest { Key = request.IdempotencyKey });
await _db.SaveChangesAsync();
return Result.Success("Completed successfully");
}
7. Conclusion
Idempotency is a core concept that improves reliability across APIs, background jobs, data pipelines, and legacy systems.
By applying techniques like idempotency keys, unique database constraints, upserts, message offsets, and concurrency control, we ensure predictable and stable system behavior.
This principle has significantly improved quality and reduced defect rates in our modernization effort—and it remains a valuable practice for any development team.