


What is Retrieval-Augmented Generation (RAG)
- Retrieval-Augmented Generation (RAG) is an essential AI framework that integrates retrieval mechanisms with generative models (LLMs). This combination is crucial for overcoming the limitations of the LLM’s static training data cutoff, ensuring responses are not only fluent but also highly accurate, verifiable, and grounded in current, external context.
- The entire history of RAG is essentially the effort to transform static LLMs into reliable, enterprise-ready tools by making them:
- Factual: Minimizing the risk of hallucination.
- Up-to-date: Accessing information beyond their fixed training cutoff.
- Verifiable: Providing explicit sources for their claims.
- The RAG paradigm represents a significant shift in problem-solving methodology: we have advanced from simple “Open-Book QA” (the act of looking up an answer) to sophisticated “Agentic Reasoning” (the complex process of planning multi-step actions to solve a problem using external, dynamically accessed knowledge).
- Since its introduction in 2020, RAG has undergone a radical transformation, moving toward highly advanced, “Agentic RAG” or “Reasoning-RAG” forms by 2025. This rapid evolution has introduced crucial capabilities designed to overcome the limitations of static LLMs, including:
- Self-Evaluation and Error Correction: The system can assess the quality of retrieved data and the generated output.
- Adaptive Retrieval: The model dynamically adjusts its search strategy based on the current step of the query.
- Structured Knowledge Integration: The ability to query and integrate data from structured sources (like databases) alongside unstructured documents.
- Agent-Like Reasoning: Employing techniques like ReAct to interleave thought, planning, and external tool use.
The sections below outline the typical evolutionary path of RAG from its initial phase in 2020 through the advanced architectures emerging by the end of 2025.
1. Original RAG / Naive RAG – 2020
- The original RAG framework follows a sequential, four-step process to leverage external knowledge:
- Chunking and Indexing: Source documents are segmented into smaller text chunks, and each is mapped to a vector embedding for efficient semantic search.
- Retrieval: Given a user query, the system performs a vector search to identify and extract the top k most relevant chunks based on similarity.
- Augmentation: The retrieved chunks are packaged with the original query to form a comprehensive prompt.
- Generation: The Large Language Model (LLM) consumes this augmented prompt to synthesize a grounded and factual response.
- This approach is commonly used in basic Q&A systems, chatbots, and FAQ automation, where questions have relatively direct answers.
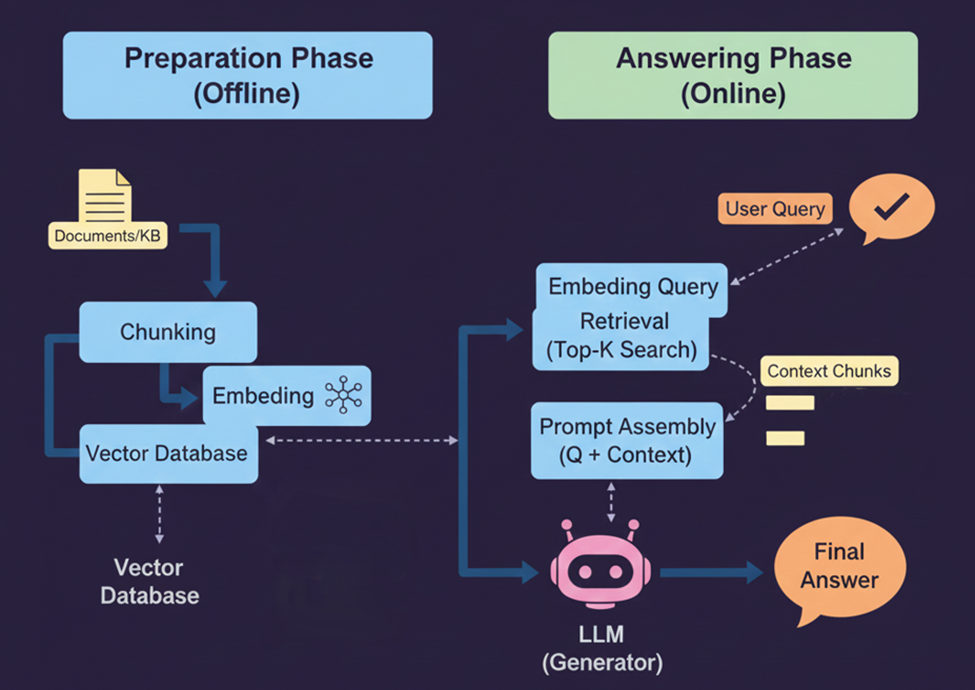
- Introduction by: Lewis et al. (Meta AI)
- Pros:
- RAG demonstrated that augmenting LMs with retrieval can greatly improve factual accuracy and reduce hallucinations
- Easy and cheap to implement.
- Low latency.
- Cons:
- “Middle-of-the-road” phenomenon: Misses context if the answer is buried in the middle of a document.
- Low Precision: Retrieves irrelevant chunks that confuse the LLM (Hallucination).
- Struggles with questions requiring multiple sources.
2.ReAct (Reason + Act Framework) – Late 2022
- ReAct is a seminal prompting paradigm that fundamentally enabled “agentic” behavior in Large Language Models (LLMs). While not a Retrieval-Augmented Generation (RAG) method itself, ReAct provides the architectural foundation for advanced, multi-step RAG systems.
- ReAct combines Reasoning (using Chain-of-Thought style prompts) with Acting (executing external actions like API calls or web searches) in a deliberately interleaved sequence:
- Thought: The LLM generates a reflective thought, such as, “I need to find the current stock price of Company X.”
- Action: The LLM then issues a specific tool call, such as a search query or an API request.
- Observation: The external tool returns a result (e.g., the stock price).
- Re-Reasoning: The LLM processes the observation, generating a new thought to guide the next step.
- Impact on Agentic RAG
- The key insight of ReAct is that models prompted to “think and act” significantly outperform those that only reason or only act, while also producing more interpretable and traceable decision paths.
- By integrating external retrieval and tool-use actions directly into the model’s self-generated flow, ReAct provided the blueprint for:
- Tool Use: Turning LLMs into capable agents that can dynamically utilize tools.
- Multi-Step Reasoning: Establishing the foundation for Agentic RAG designs, where the LLM can plan a series of retrieval and reasoning steps to tackle complex, multi-hop queries.
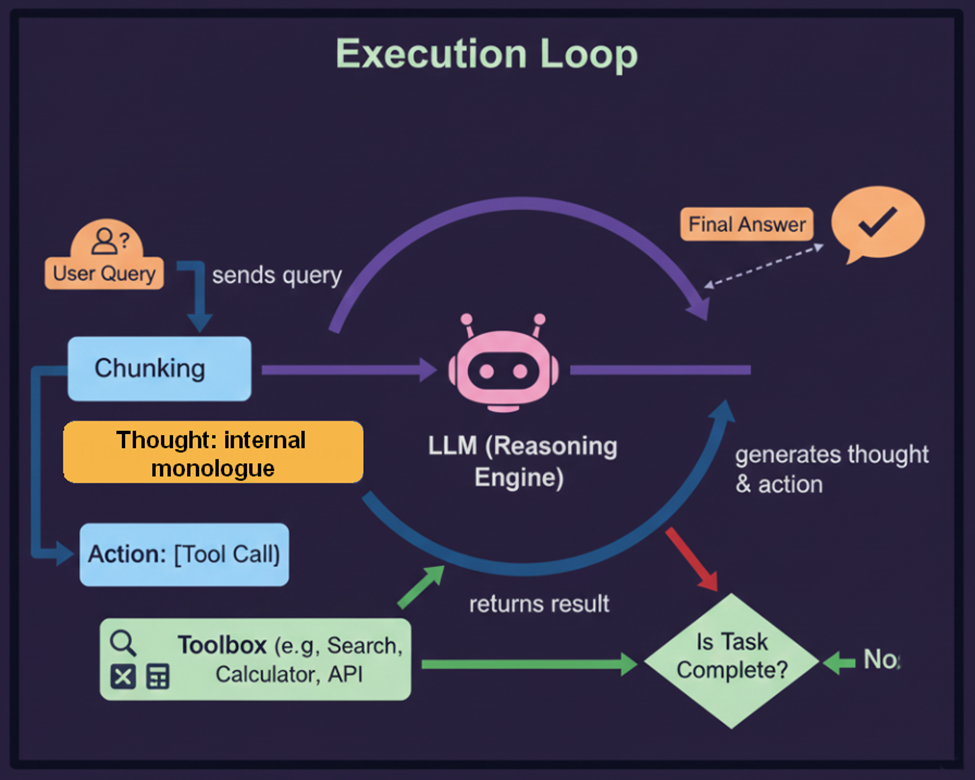
- Introduction by: Yao et al.
- Pros:
- Supports multi-step retrieval: Model can retrieve → think → retrieve again, allowing deeper queries than simple vector search.
- Reduces hallucination (compared to plain LLM)
- Easy to extend with more tools: ReAct framework can add web search, code execution, SQL, knowledge graphs
- Cons:
- Slow and expensive.
- Hard to control: LLMs sometimes call irrelevant actions, loop infinitely, over-retrieve, under-retrieve, create noisy chain-of-thought.
- Retrieval quality depends heavily on prompt design.
- Hard to ensure safety & robustness: Chain-of-thought is generated in real time → unpredictable, unsafe reasoning steps, leaking sensitive info, generating undesirable tool calls.
3. RAG Fusion (Added as Missing Link) – Late 2023
- RAG Fusion addresses a fundamental limitation in standard RAG: User queries are often imperfect. Humans frequently ask ambiguous, overly simple, or conceptually misaligned questions that fail to match the specific phrasing in the vector database.
- RAG Fusion bridges this gap through a three-step process:
- Multi-Query Generation: The LLM generates multiple variations (typically 4–5) of the original user query to capture different perspectives and potential meanings.
- Parallel Retrieval: The system performs vector searches for all generated queries simultaneously.
- Reciprocal Rank Fusion (RRF): The retrieved results are aggregated using Reciprocal Rank Fusion, an algorithm that re-ranks documents based on their prevalence and position across the multiple search lists.
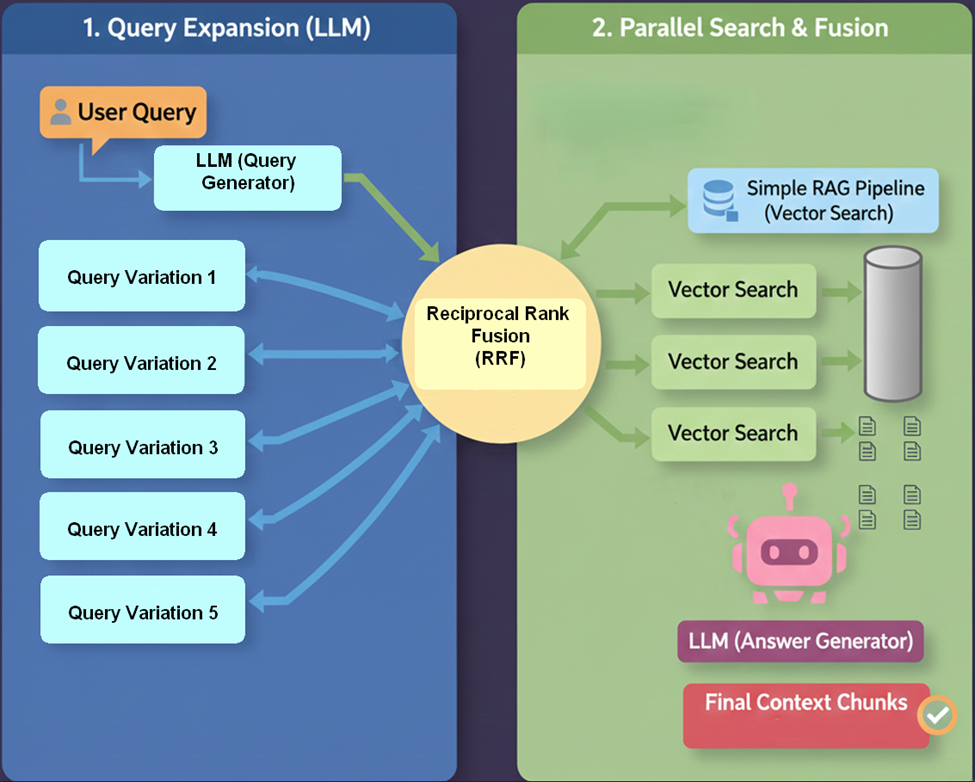
- Introduction by: Adrian Raudaschl
- Pros:
- By generating diverse query variations, the system casts a “wider net,” retrieving relevant documents that might not share the exact keywords or vector space of the original query.
- It compensates for poorly phrased, vague, or overly brief user questions. The LLM acts as an “interpreter,” expanding the user’s intent into fully formed search queries.
- The different query variations often tackle the problem from multiple angles leading to a more comprehensive answer.
- Cons:
- Increased Latency and higher cost
- If the LLM generates a query variation that drifts off-topic (a “hallucinated” intent), it may retrieve irrelevant documents that confuse the final generation.
4. Modular RAG – Late 2023
- Modular RAG is an architectural paradigm that treats the Retrieval-Augmented Generation (RAG) system as a toolkit composed of distinct, interchangeable components. Rather than a fixed pipeline, Modular RAG enables developers to select and combine different modules to create highly optimized, use-case-specific workflows.
- This architecture is widely adopted in domain-specific research environments and complex production AI applications requiring flexible performance tuning.
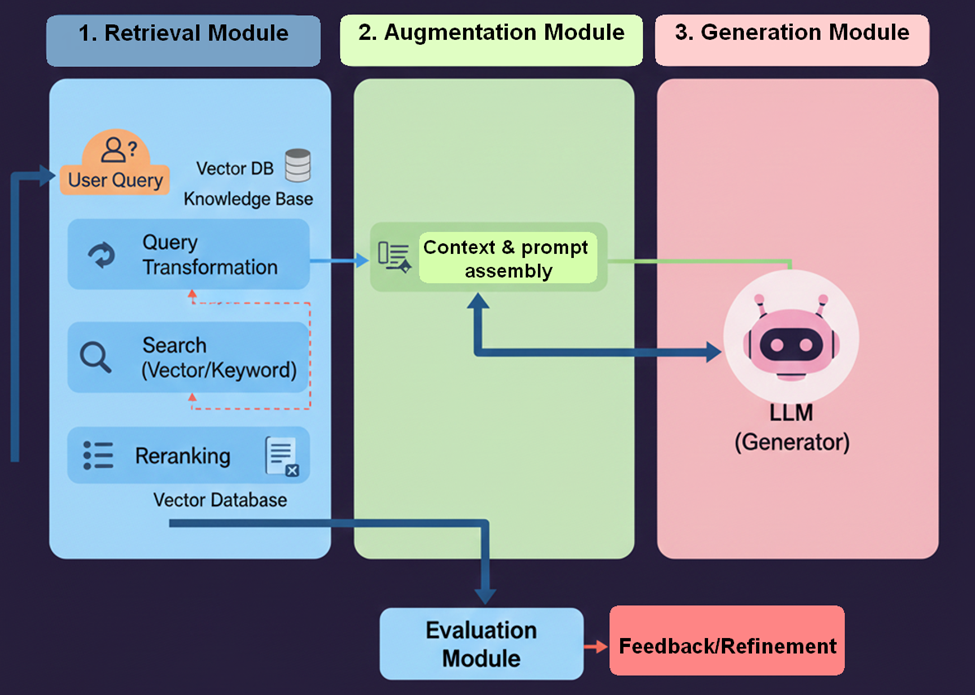
- Introduction by: Gao et al.
- Pros:
- Highly flexible; you can upgrade one part without breaking the whole system.
- Allows for specialized flows for different departments.
- Cons:
- Complex engineering overhead to orchestrate modules.
- Debugging Difficulty: Tracing errors or performance bottlenecks can be challenging across multiple, separate components.
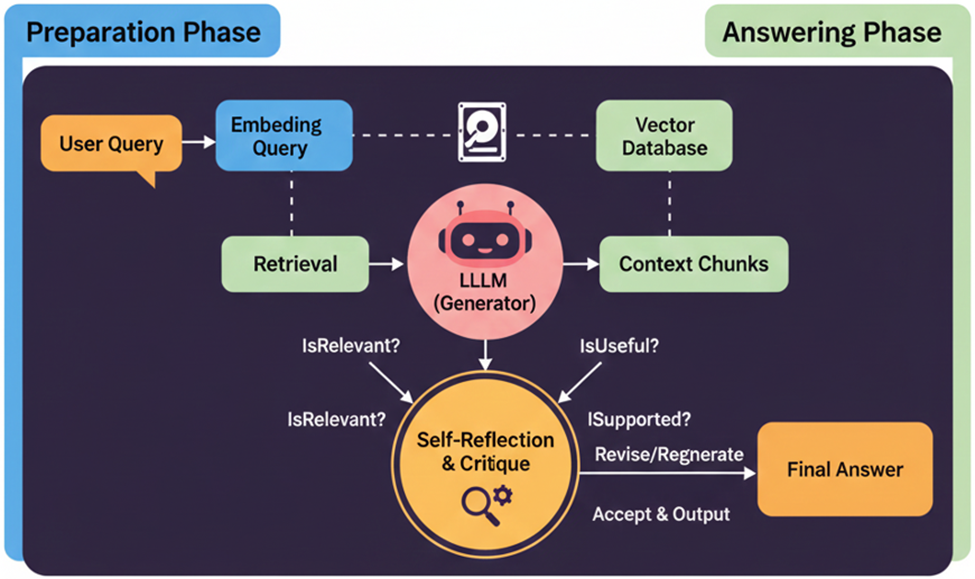
5. Self-RAG (Self-Reflective RAG) – Late 2023
- Self-RAG is an advanced framework where the Large Language Model (LLM) is trained to perform self-critique during the retrieval and generation process. It achieves this by outputting specialized “Reflection Tokens” (e.g., Is this relevant? or Is this supported?).
- The primary benefit is a massive reduction in hallucination by enabling the system to self-filter and discard poor-quality or irrelevant retrieved documents before synthesizing the final answer.
- Introduction by: Akari Asai et al.
- Pros:
- Drastically reduces hallucinations.
- The model can decide not to answer if data is missing.
- Cons:
- Higher costs to run extra checks
- Slower generation speed due to evaluation tokens.
6. Multimodal RAG – 2023/2024
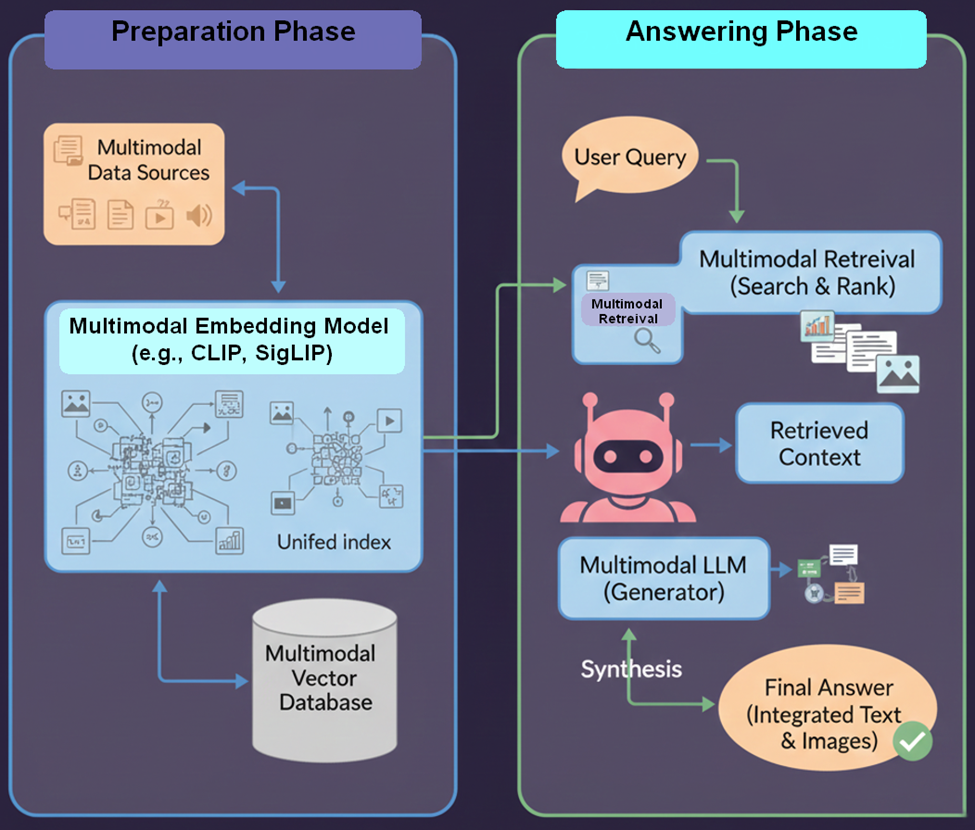
- Multimodal RAG is an advanced evolution of RAG designed to answer complex user queries by simultaneously utilizing and synthesizing information from diverse media sources, including text, images, videos, audio files, charts, and documents.
- The key function of Multimodal RAG is to achieve a unified understanding across different data types:
- Multi-Modal Embedding: The system converts all forms of content—whether it’s an image, a video clip, an audio segment, or a standard document—into a shared vector representation (embedding). This allows the system to semantically search and link concepts regardless of their source format.
- Cross-Modal Retrieval: When a question is asked, the system searches through this unified index, retrieving relevant information across all available media types.
- Synthesis: The Large Language Model (LLM) then consumes and combines this diverse textual and non-textual context to provide a complete, accurate, and grounded response.
- Multimodal RAG is essential for applications that analyze files or domains where information is inherently presented across multiple forms of media.
- Introduction by: Enabled by GPT-4V, Gemini, and LLaVA.
- Pros:
- Comprehensive Context: Provides more complete and nuanced answers by aggregating evidence from any type of content (text, visual, auditory).
- Rich Information Access: Great for complex and visual topics (e.g., medical imaging, engineering diagrams) that require multiple perspectives for verification.
- Cons:
- Interpretation Difficulty: The quality of the output heavily depends on the system’s ability to accurately interpret and align various data formats.
- Resource Intensive: Requires significantly more storage for vector indexes and greater processing power for the complex multimodal embedding and retrieval steps.
- System Complexity: More complex to build, train, and maintain due to the specialized encoder models required for generating accurate multimodal embeddings.
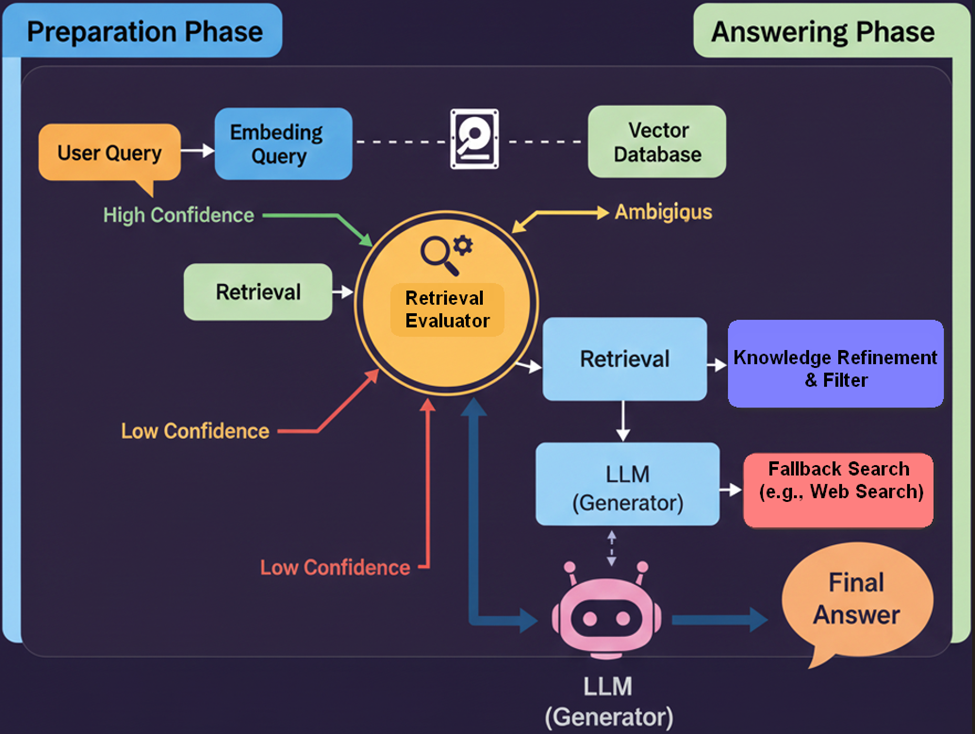
7. Corrective RAG (CRAG) – Early 2024
- CRAG enhances retrieval reliability by integrating a dedicated Retrieval Evaluator (a lightweight model or classifier) to swiftly assess the quality and relevance of retrieved context.
- Correction Mechanism: If the initial retrieval is judged as ambiguous, insufficient, or incorrect, CRAG activates a fallback mechanism (typically a web search or a query to an external knowledge source) to procure superior supporting evidence.
- CRAG’s ability to self-verify and correct retrieval failures makes it ideal for high-stakes scenarios where accuracy is paramount, such as legal research, compliance review, and academic writing.
- Introduction by: Yan et al.
- Pros:
- Self-correcting mechanism prevents answering with bad data.
- Incorporates real-time web knowledge when the database fails.
- Cons:
- Dependence on external web search APIs.
- Might need multiple search attempts leading to longer response and consuming more resources.
8. Adaptive RAG – Mid 2024
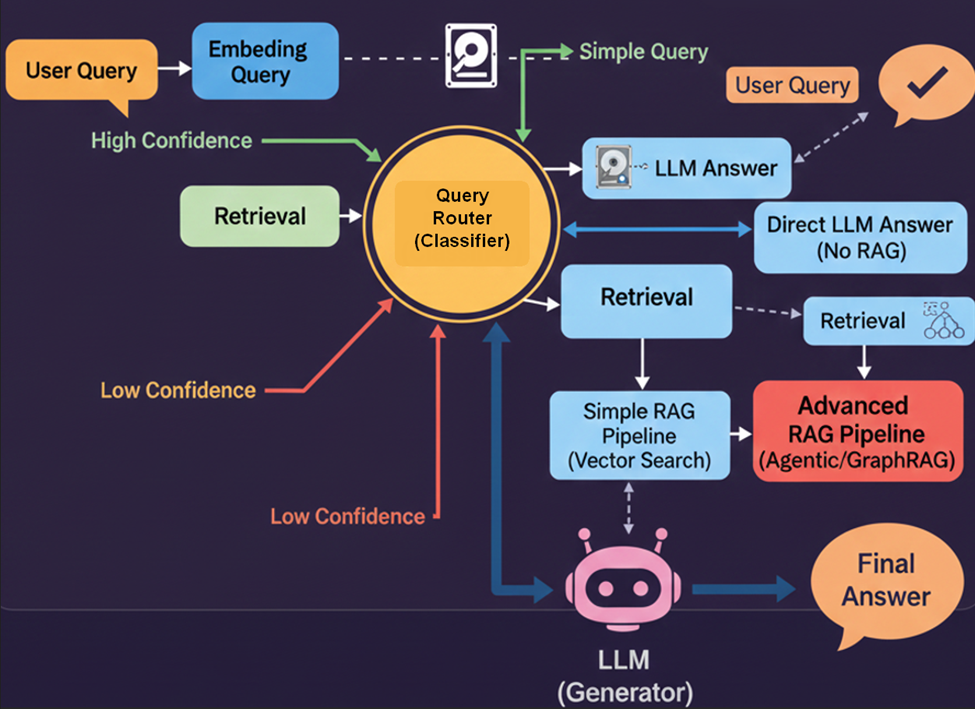
- Adaptive RAG enhances the efficiency and effectiveness of RAG systems by dynamically adjusting the retrieval strategy based on the complexity of the user’s query. It uses a Router to classify the query and choose the optimal approach, ranging from no retrieval to complex multi-step retrieval.
- The central component is a Router, typically a smaller, specialized Language Model (LM) or classifier, which determines the appropriate course of action for each incoming query. This classifier is trained using automatically labeled data that indicates whether a single retrieval step is sufficient (Simple/Medium) or if multi-step reasoning is required (Hard).
- The Router classifies queries into three main categories:
- Simple: No retrieval needed. The system answers directly based on the large language model’s (LLM’s) internal knowledge base.
- Medium: Use standard (naive) RAG. The system performs a single-step retrieval to fetch relevant documents and augment the LLM’s answer.
- Hard: Apply multi-step or advanced RAG. The system applies complex strategies, such as multi-hop reasoning or breaking the query into sub-questions, requiring multiple retrieval steps.
- Adaptive RAG is commonly used in systems that must handle a wide variety of queries, such as customer support agents, research assistants, and AI-powered digital assistants.
- Introduction by: Jeong et al.
- Pros:
- Cost & Speed Efficient: Doesn’t waste resources on simple questions.
- Cons:
- If the router makes a mistake (classifies a hard question as simple), the answer fails completely.
- It takes time to learn and improve, so early results might be inconsistent
9. Graph RAG – Mid 2024
- GraphRAG is an advanced approach to Retrieval-Augmented Generation (RAG) that structures external knowledge as a knowledge graph—a network of entities (nodes) connected by relationships (edges). This representation enables more systematic and complex multi-hop reasoning than traditional text-based RAG.
- GraphRAG methods introduce three primary innovations that enhance reasoning and generation quality:
- Knowledge Representation: Transforming unstructured text into a graph structure to explicitly capture complex relationships between entities.
- Graph-Based Retrieval: Employing specialized retrieval algorithms that traverse the graph’s edges. This allows the retriever to efficiently follow connections, gather multiple relevant, connected pieces of information (subgraphs), and preserve the crucial context needed for reasoning.
- Structure-Aware Generation: Using the retrieved subgraph as a structured context for the language model. This context guides the generator to produce more logically coherent, accurate, and non-contradictory outputs by directly referencing the established relationships.
- By converting unstructured text into a rich, graph-based context, GraphRAG is considered a vital bridge toward structured reasoning in RAG systems. It provides a robust backbone for advanced agentic systems that require the ability to understand and reason over complex relationships rather than relying on the retrieval of isolated facts.
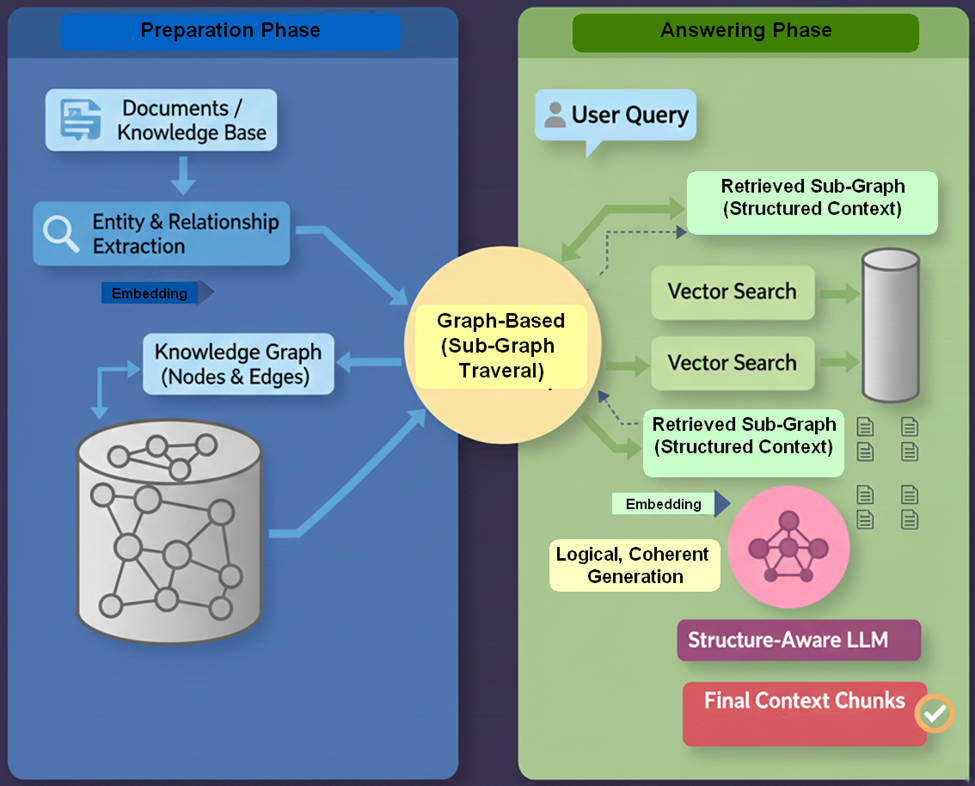
- Introduction by: Microsoft Research / Edge et al.
- Pros:
- Excells at Multi-hop reasoning (connecting distant dots). Helps prevent scattered answers.
- Provides holistic dataset understanding, not just local snippets.
- Cons:
- Very Expensive: Building the graph (Entity Extraction) consumes massive tokens.
- Hard to update the graph incrementally.
10. Agentic RAG – Late 2024
- Agentic RAG is an advanced architectural paradigm where an “Agent” plans a sequence of actions. It can query, read, re-query, use tools (Calculator, SQL, …), and self-correct until the task is done.
- This is enabled by integrating agentic capabilities into the LLM’s flow:
- Reflection: Using Chain-of-Thought to critique intermediate results and refine the approach.
- Planning: Breaking down complex queries into sequential sub-goals and retrieval steps.
- Tool Use: Autonomously selecting and utilizing external resources, such as search engines, calculators, or APIs.
- Collaboration: Coordinating specialized sub-agents for different tasks or knowledge domains.
- Ultimately, Agentic RAG signifies the key industry shift from relatively static retrieval augmentation to autonomous, self-directed retrieval and reasoning, though it necessitates addressing new challenges in reliability, evaluation, and ethical governance.
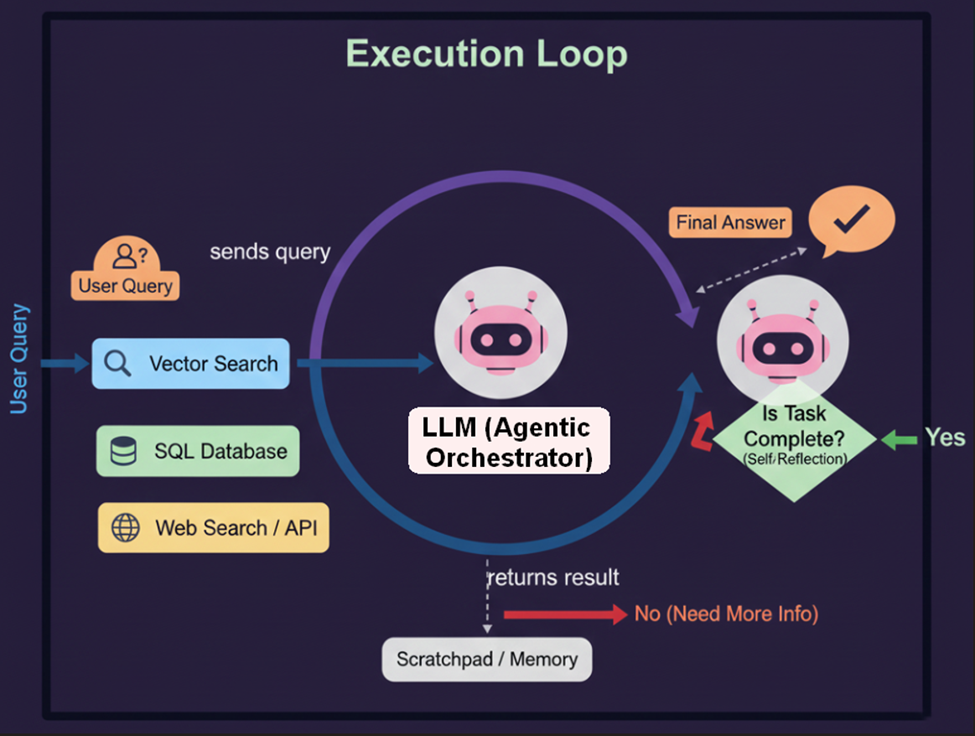
- Introduction by: Popularized by LangGraph / LlamaIndex. (Evolved from ReAct, 2022)
- Pros:
- Can solve highly complex, multi-step problems that linear RAG cannot.
- Intelligent decision-making about information gathering.
- Cons:
- High Latency and cost: Can take a long time to “think” and perform multiple tool calls (actions) in sequence significantly increases latency and leads to higher operational costs due to elevated token consumption.
- Difficult to build and manage: Since the agent’s path is decided dynamically by the LLM, the output can be less predictable compared to deterministic, fixed RAG pipelines, making testing and quality assurance more challenging.
11. Reasoning-RAG (System 1 & System 2 Hybrid) – 2025
- Reasoning-RAG represents the latest evolution in RAG architectures, drawing inspiration from psychologist Daniel Kahneman’s dual-process theory of human cognition—System 1 (fast, intuitive) and System 2 (slow, deliberative). This approach integrates dual-process reasoning into RAG systems to achieve both reliability and flexibility.
- The ultimate goal of Reasoning-RAG is to achieve the best of both worlds:
- the reliability offered by structured, predefined logic
- and the flexibility of dynamic, agentic behavior
- This approach completes the transition of RAG from a passive retrieval utility to an integrated, intelligent agent. Solving complex math, coding, or legal analysis problems where simple summarization is insufficient.
- By 2025, RAG systems no longer merely fetch documents; they think, check, adapt, and act as a seamless part of the generation process, moving the technology from reactive Q&A toward genuinely self-directed, reasoning agents.
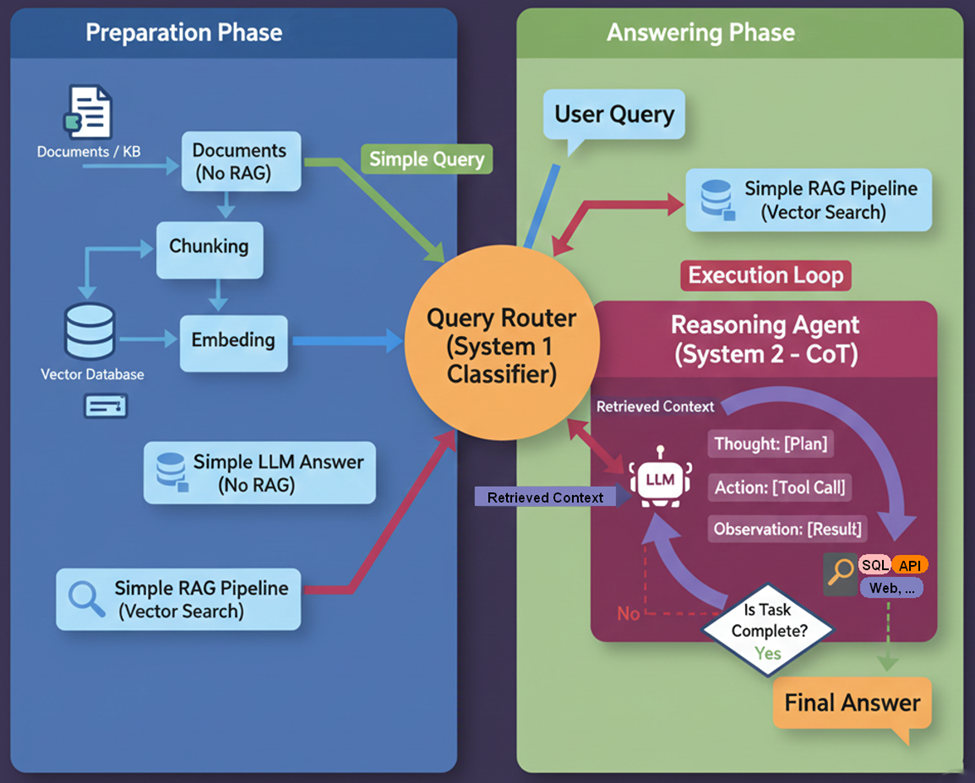
- Introduction by: DeepSeek-R1 / OpenAI o1 style
- Pros:
- Solves “Distractor” Problems (Higher Precision)
- Detail: Standard RAG often gets confused if it retrieves 5 documents, where 3 are relevant and 2 are irrelevant but share keywords.
- Benefit: A Reasoning model (System 2) reads the retrieved context and explicitly thinks: “Document A mentions X, but Document B contradicts it. Since Document B is newer, I will prioritize B.” It filters noise logically, not just statistically.
- Handles “Implicit” and Multi-hop Queries
- Superior Math and Analytical Capabilities
- Detail: LLMs are historically bad at math.
- Benefit: By forcing a “Chain of Thought” (CoT) process, the model can extract numbers from financial reports (retrieved via RAG) and perform accurate calculations step-by-step before outputting the final answer.
- Cons:
- High Latency and Costs
- “Overthinking” Simple Queries. If not routed correctly, the model might try to deeply analyze a simple greeting or factual question.
- Implementation Complexity (The “Black Box” Issue).
- Debugging is harder.
- When the model fails, did it fail because the Retrieval (System 1) missed the document, or because the Reasoning (System 2) made a logic error in its thought chain? Tracing the error requires inspecting the hidden chain-of-thought, which adds engineering overhead.
While other RAG variations exist, the examples above represent the typical evolutionary path of the framework.
Please note: The content and analysis within this blog post are based on knowledge available as of December 2025.