


In an era where AI is permeating everywhere, you’ve certainly used some AI to serve your work and daily life, most commonly Generative AI, where you use natural language (call prompt) to interact with it and receive very “human-like” responses.
Have you ever asked AI the same question but received different answers each time – sometimes excellent, sometimes nonsensical? The problem isn’t with the AI, but with how we ask questions. And are there ways to help us interact more effectively with these AI systems? Let me walk you through the fundamentals of AI prompting!
How LLMs Work
First, I must emphasize that large language models don’t truly understand what you’ve written and sent them, as a human would. Instead, they use statistical probability algorithms to predict the following string of characters or words based on probability patterns from the massive dataset they were “trained” on.
Instead of “thinking” AI performs mathematical calculations to find the word most likely to appear in a given context.
Additionally, AI models use an attention mechanism that helps them focus on the most essential words in a prompt to understand their relationships, regardless of the distance between them. This is similar to how you learn to “catch keywords” when understanding a foreign language.
LLMs also process the words they receive or output through “tokenization” which means breaking text into many “chunks” each of which is a token (a token can be a word, part of a word, or punctuation). This is why processing languages other than English typically consumes more tokens.
Another equally important factor when working with LLMs is the context window. This is a parameter that limits the amount of information the model can process and “remember” in a single interaction. If the conversation exceeds this limit, the model will start forgetting old information at the beginning of the chat. This is also why, in a very long chat with AI models, you feel like “it” has forgotten some information you provided long ago.
Important Control Parameters For Prompt
There are several technical parameters related to LLMs that you need to grasp to interact with them more effectively:
System Instructions
Global rules that govern a model’s behavior and response format.
For example, you can specify that the model always returns responses in JSON format.
Temperature
This parameter controls the creativity or randomness in an AI model’s response.

The meaning of this parameter is explained as follows:
- Low (near 0): Highly deterministic results, focused on facts, suitable for programming or data analysis.
- High (near one or higher): Diverse, creative results but prone to hallucinations, suitable for artistic writing.
Top-p (Nucleus Sampling)
This parameter limits the model to selecting only from a set of words whose cumulative probability is greater than or equal to p. The Top-p value is a variable that the model computes each time it receives a user’s prompt. The meaning of this value is explicitly explained:
- Low Top-p → focused responses, less rambling
- High Top-p → more natural, diverse responses
In practice, for most use cases, systems will fix one parameter (e.g., top-p = 0.9) and fine-tune only the remaining parameter to control output quality.
Max Tokens
The maximum number of tokens in each model response. This parameter helps the model avoid overly long, rambling responses, while also helping control costs.
There are a few other parameters, but in this post, I’m only listing a few important ones, in my opinion.
Core Prompt Techniques
Zero-shot Prompting
A technique in which you ask an AI to perform a task without providing any examples. AI will rely entirely on the vast knowledge it was trained on to understand and execute the request on its own. This is also commonly how we approach and explore Generative AI when first starting. This prompt style is suitable for simple, everyday tasks like translation, text summarization, or answering general knowledge questions.
Example: “Summarize the content of this article about Software Testing in 10 bullet points: [Article content]”
The disadvantage of Zero-shot is that results heavily depend on wording, and it’s not suitable when a specific format or logic is required.
Few-shot Prompting
The second technique is providing AI models with one or several example samples (input-output pairs) before making the actual request to receive results as desired. This technique helps AI clearly understand format, tone, and complex processing logic that’s difficult to express in words fully. It helps minimize “hallucinations” and increases consistency in returned results.
Few-shot Prompting is especially effective when the output format is more important than the provision of new knowledge.
Example: Customer sentiment classification:
- Product is very good → Positive.
- Delivery too slow → Negative.
- It’s okay → Neutral.
Role-based Prompting
Have AI play a specific role or character to guide response style and level of professional detail in the field where you need AI consultation. When given a role (e.g., a lawyer, data expert, or teacher), AI will use specialized vocabulary and tone appropriate to that role, while also providing more in-depth knowledge and information about the questions and issues you present.
Role-based Prompting is most effective when combined with objectives, target audience, and usage context (audience + context), not just simply “playing a role.”
Example: “You are a cybersecurity expert, please explain to non-IT staff, in simple language, in 3 short paragraphs…”
Advanced Reasoning Techniques and Chaining
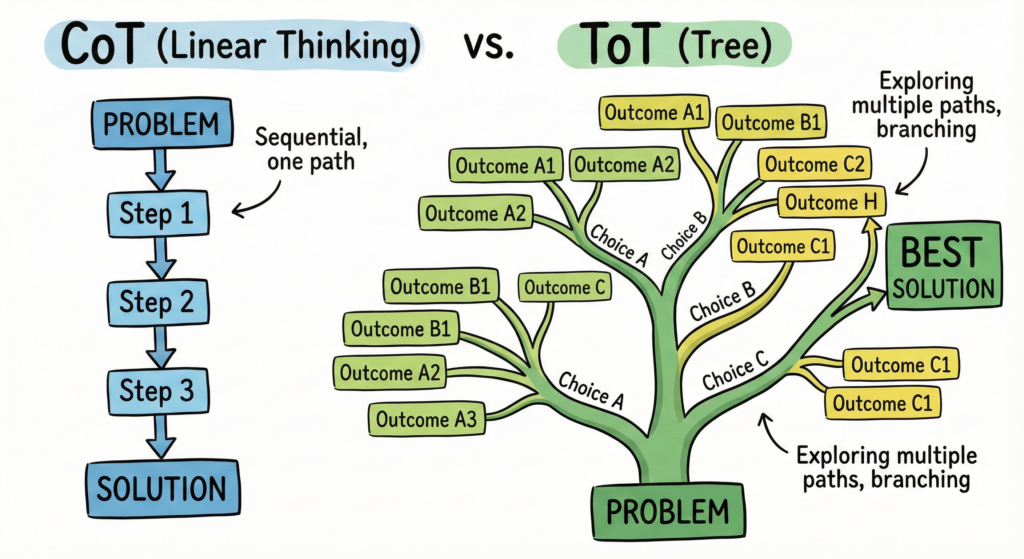
Chain-of-Thought (CoT)
This is a technique that asks AI to present solutions step by step in a structured way, helping users understand the logic that leads to the results. This technique allows the model break down problems into smaller reasoning units, especially useful for issues about mathematics, programming, or analyzing complex regulations.
The simplest way to apply this technique is to use the keyword “Please present the solution step by step, clearly and verifiably” in an appropriate place in your prompt.
This technique will help AI minimize “hallucinations” and make it easier for us to check or debug its logic.
In current practice, instead of asking AI to “present all detailed reasoning” we can ask the model to “think internally and only return the final result with brief reasoning” thereby ensuring quality and avoiding the risk of logical noise.
Tree-of-Thought (ToT)
A more specialized technique inherited from CoT and developed more broadly, in which AI simultaneously explores multiple different reasoning branches like a decision tree. With this technique, the model will generate solution alternatives, analyze the pros and cons of each branch, and select the most logical conclusion.
This technique should be applied to tasks requiring creativity or strategic planning, problems where there isn’t just one correct answer.
Example: building marketing strategies, product planning, or making business decisions with multiple scenarios.
Prompt Chaining
The third technique I’m mentioning is used to divide a complex task into small steps, each executed by a separate prompt, with the result of the previous step serving as input for the next. Sounds like it’s similar to CoT, right? But it’s only comparable in the “chain” nature, while the purpose and meaning of using these two techniques are entirely different.
This technique is like an assembly production line: Prompt 1 creates the frame, Prompt 2 takes the output from Prompt 1 to install internal details, and Prompt n takes the production from Prompt n-1 to complete the product.
The purpose of this technique is to help avoid situations where the model is overloaded with information when using a single overly long prompt (mega-prompt), while also allowing users to control the quality at each “stage.”
Supporting Techniques
Self-Consistency
Request that AI provide multiple reasoning paths for the same problem and choose the result that appears most frequently to ensure reliability. Usually applied to reasoning problems, mathematics, or questions with multiple solution methods.
Reflection
After AI provides an answer, ask it to self-check for logical errors or refine the content to achieve higher quality. Reflection is especially effective when combined with Prompt Chaining or Role-based Prompting to improve final output quality.
Below is a quick summary table so you can understand when to use which prompting technique:
| Goal | Suitable Technique |
|---|---|
| Quick questions, general knowledge | Zero-shot |
| Need correct format, correct type | Few-shot |
| Need expert perspective | Role-based |
| Math, logic, analysis | CoT / Self-Consistency |
| Planning, creativity | ToT |
| Complex multi-step tasks | Prompt Chaining |
| Improve answer quality | Reflection |
Conclusion
Prompting isn’t “quick tips” or a few magic commands, but a thinking skill – where you learn to understand the model’s limitations, restructure problems, and communicate more clearly with AI.
When you understand how LLMs work, know when to use zero-shot, few-shot, or chaining, you’ll realize that the quality of AI’s answers directly reflects the quality of the questions you ask.
Good prompting doesn’t make AI smarter – it helps us work smarter with AI. And that is precisely the first foundation for entering the world of Prompt Engineering seriously.