



1. Why Test Data Management Matters
In almost every testing project, one recurring blocker is test data. Testers often hear statements like:
- “Data is not ready yet.”
- “We cannot use production data.”
- “This environment doesn’t have enough data.”
- “That data belongs to another system.”
Test data is one of the most common blockers in software testing. Many test cycles don’t fail because of bugs—but because testers are blocked by missing or unusable data. Without the right data, test cases cannot be executed properly, automation becomes unstable, and releases are delayed. A strong Test Data Management (TDM) approach helps testers work independently, reduce risk, and improve test coverage.
2. What Is Test Data Management (TDM)?
Test Data Management is the process of planning, creating, maintaining, and securing test data across test environments. For testers, TDM is not a backend or data team responsibility—it is a critical testing enabler
- Test execution is not blocked by missing data
- Sensitive data is protected
- Data remains consistent across environments
- Automation and performance testing can scale
3. Common Test Data Challenges Testers Face
Many testing issues are actually data problems in disguise:
3.1 Availability Challenges
- Test data not ready on time
- Dependency on external systems or teams
3.2 Compliance Challenges
- Use of production data restricted
- Data privacy and PII regulations
3.3 Stability Challenges
- Automation test failures due to unstable data
- Inconsistent data across environments
To solve these problems, testers need to understand and apply different test data strategies, not rely on a single approach.
4. How to Use Synthetic Data, Data Masking, and Environment Cloning Effectively
Choosing the right test data strategy is essential for effective testing. In practice, testers often need to combine multiple approaches depending on the testing phase, data sensitivity, and system complexity. Below are three commonly used strategies and how to apply them effectively.
4.1 Comparison: Synthetic Data vs Data Masking vs Environment Cloning
| Aspect | Synthetic Data | Data Masking | Environment Cloning |
| Definition | Artificially generated data created based on business rules and data structures, without using real user or production data. | The process of hiding or obfuscating sensitive information in real data while preserving its structure and relationships. | Copying data and configuration from one environment (typically Production or UAT) to another environment (QA or Staging). |
| Data Source | Generated from rules, schemas, or scripts | Real production or UAT data | Production or UAT environment |
| Data Sensitivity | No sensitive data | Sensitive data is protected | Contains sensitive data unless masked |
| Level of Realism | Medium (rule-based, controlled) | High (real data structure and behavior) | Very high (exact copy of real system state) |
| Main Purpose | Enable fast, safe, and repeatable testing | Allow realistic testing while meeting security and compliance requirements | Reproduce real-world issues and ensure environment consistency |
| Typical Methods | • Define business rules (IDs, dates, statuses) • Use data generation tools (Mockaroo, Faker) • Create scripts (SQL, API, Python) • Integrate with automation frameworks | • Identify sensitive fields (PII, financial data) • Apply masking techniques (substitution, tokenization, encryption) • Preserve formats and data relationships • Validate masked data usability | • Clone database and configurations • Apply masking immediately after cloning • Validate data integrity and setup • Refresh environments periodically |
| Best Used For | • Automation testing • Early testing phases • CI/CD pipelines • Performance testing | • UAT testing • Regression testing • Compliance-sensitive projects | • Defect reproduction • End-to-end regression • Production-like validation |
| Advantages | • Fast and safe • No compliance risk • Fully controllable and reusable • Stable for automation | • High realism • Meets security and privacy regulations • Supports complex business scenarios | • Most accurate representation of production • Helps detect environment-related issues |
| Limitations | • May not cover complex real-world scenarios | • Masking must be carefully designed to avoid breaking tests | • High risk if data is not masked • Expensive and time-consuming |
| Case Study | Automation tests failed due to unstable shared data. The team generated synthetic users via APIs and reused them across test runs, making automation stable and CI/CD-ready. | UAT contained real customer data. Masking was applied to personal fields while keeping business logic intact, enabling compliant and uninterrupted testing. | Regression defects could not be reproduced due to inconsistent environments. Cloning UAT into QA and masking data allowed accurate defect reproduction and reduced production leakage. |
4.2 Diagram
Below are diagrams illustrating each test data strategy and how they are commonly combined in real projects.
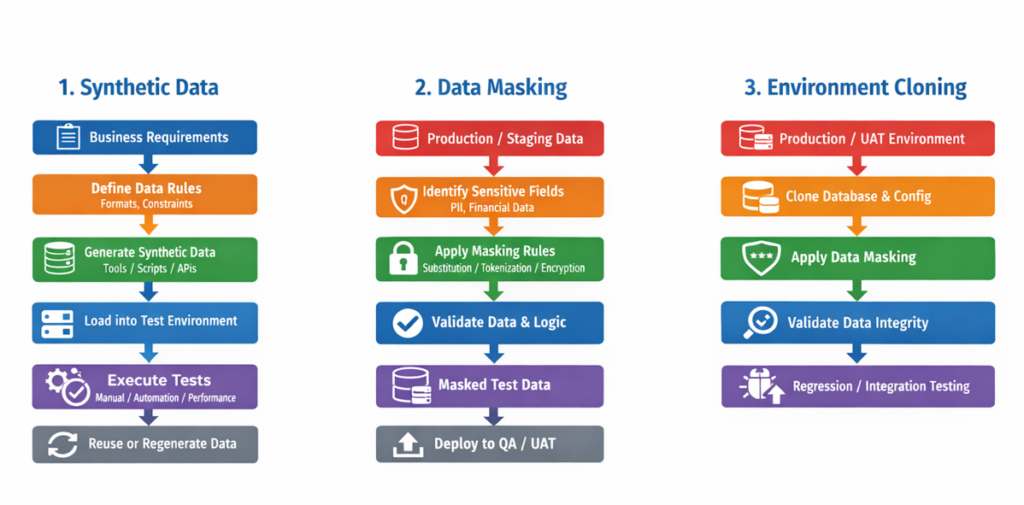
Key points:
- Synthetic data removes dependency on production systems and is ideal for automation and early testing.
- Masked data must remain realistic and usable, not just hidden.
- Never use cloned data for testing without masking.
4.3 How Testers Should Choose the Right Test Data Strategy
| Testing Type | Recommended Data Strategy |
| UI Testing | Synthetic data |
| Regression Testing | Masked production data |
| Automation Testing | Synthetic and reusable datasets |
| Performance Testing | Large-scale synthetic data |
| UAT | Masked cloned data |
5. Do / Don’t Tips for Testers (Quick Guide)
| Aspect | Synthetic Data | Data Masking | Environment Cloning |
| Do | – Define clear business rules before generating data – Automate data creation for repeatable tests – Reuse datasets for automation and CI/CD | – Mask all sensitive fields (PII, financial, credentials) – Keep data formats and relationships valid – Re-mask data after every refresh | – Clone only when realistic data is required – Apply masking immediately after cloning – Use cloning to reproduce production issues |
| Don’t | – Generate meaningless random data – Hardcode test data in scripts | – Break business logic with improper masking – Assume masked data is automatically safe | – Use cloned data without masking – Rely on cloning as the only strategy |
6. Conclusion
Each test data strategy plays a distinct role in effective testing. Synthetic data enables fast execution, automation, and early testing. Data masking allows testers to work with realistic data while maintaining security and compliance. Environment cloning provides accuracy and consistency when reproducing real-world issues.
Applying the right strategy at the right time helps reduce risk, improve test coverage, and deliver higher-quality software.
In summary:
- Synthetic data brings speed
- Masked data provides realism
- Cloned data ensures accuracy
- A balanced approach delivers quality