


Introduction
Many people think downtime simply means a website or server is completely unavailable.
In reality, downtime is much more complex.
A system may still be “running,” dashboards may look healthy, and servers may still respond — yet users cannot complete the tasks they need. From the user’s perspective, the system is effectively down.
This is especially important in modern SaaS (Software as a Service) products, where users expect systems to work continuously. Even a few minutes of disruption can affect business operations, customer trust, and company revenue.
For testers, downtime is no longer “someone else’s problem.”
It is closely connected to product quality, user experience, monitoring, release processes, and incident recovery.
This article explains:
- What downtime really means
- How downtime happens
- Why testers should care about it
- How teams measure downtime
- Practical ways to reduce downtime
- Real-world examples from production systems
What Is Downtime?
Downtime is the period when a system or service cannot operate normally, preventing users from completing their intended tasks.
Many beginners imagine downtime like this:
- Server crashes
- Website becomes unreachable
- API stops responding
- Entire system is unavailable
That is true — but only partially.
Downtime Is About User Experience
In real systems, downtime is often more subtle.
Sometimes:
- The server is alive
- Monitoring dashboards look normal
- Health checks pass
- APIs still respond
But users still cannot use the product properly.
Example
Imagine an online payment system:
- Users can log in
- Product pages load correctly
- Search still works
But the payment service fails during checkout.
Technically, the system is “up.”
But from the customer’s point of view, the service is unusable.
That is still downtime.
Modern Definition of Downtime
Today, downtime is not only about infrastructure failure.
It is about whether the system can continue delivering the service users expect.
This includes:
- Performance issues
- Partial failures
- Broken workflows
- Slow response times
- External service failures
- Configuration mistakes
- Deployment problems
Common Causes of Downtime
Downtime rarely starts with a dramatic server crash.
In many cases, it begins with small issues that slowly grow into larger problems.
1. Deployment Bugs
A new release may introduce:
- Incorrect business logic
- Database migration problems
- API compatibility issues
- Memory leaks
Real-World Scenario
A new deployment changes authentication logic.
Initially:
- Only a few users experience login failures
- Error rate remains low
- Monitoring does not trigger alerts
After traffic increases:
- More users fail to log in
- Support tickets increase
- Eventually the incident becomes a full outage
2. Configuration Mistakes
A simple configuration error can create major downtime.
Examples include:
- Wrong environment variables
- Incorrect feature flags
- Misconfigured load balancers
- Expired certificates
These problems are surprisingly common in production systems.
3. Third-Party Service Failures
Modern applications depend heavily on external services:
- Payment gateways
- Cloud providers
- Authentication systems
- Email services
- Analytics platforms
If one external service becomes slow or unavailable, your own system may also fail.
Example
An e-commerce platform depends on a payment API.
The payment provider becomes slow.
Result:
- Checkout requests timeout
- Users cannot complete purchases
- Revenue is affected immediately
4. Performance Degradation
Sometimes the system is technically alive but extremely slow.
Users may experience:
- Endless loading screens
- Timeouts
- Delayed responses
This is often treated as downtime because users abandon the system.
Planned vs Unplanned Downtime
Not all downtime is unexpected.
Planned Downtime
Planned downtime happens intentionally.
Examples:
- Database upgrades
- Infrastructure maintenance
- Major migrations
- Security patches
Users usually see messages like:
“Scheduled Maintenance in Progress”
These incidents are easier to manage because teams prepare in advance.
Unplanned Downtime
Unplanned downtime is more dangerous.
It may happen because of:
- Production bugs
- Infrastructure failures
- Traffic spikes
- Security incidents
- Human mistakes
These situations require fast detection and recovery.
How Downtime Usually Happens
Many outages do not happen instantly.
They develop gradually.
Typical Downtime Timeline
Step 1 – Small Symptoms Appear
Examples:
- Increased response time
- Higher error rate
- Lower Apdex score
- Random user complaints
At this stage, the issue may seem harmless.
Step 2 – System Starts Degrading
More services become affected.
Examples:
- Database connections increase
- Queue delays grow
- API retries overload the system
Step 3 – Users Feel the Impact
Now users begin reporting problems:
- Failed transactions
- Login issues
- Missing data
- Slow pages
Step 4 – Incident Detection
The company finally detects the issue through:
- Monitoring alerts
- Synthetic tests
- Customer support tickets
- On-call engineers
Step 5 – Recovery
The team responds by:
- Rolling back deployments
- Restarting services
- Fixing infrastructure
- Disabling broken features
How Downtime Is Measured
In theory, downtime starts at:
TI – Time of Incident
This is when the actual problem begins.
However, this moment is often difficult to identify.
Many incidents happen silently before detection.
Practical Measurement
Most companies use:
- TD = Time Detected
- TF = Time Fully Recovered
Formula
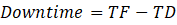
Where:
- TD (Time Detected) = when the incident is discovered
- TF (Time Fully Recovered) = when the system becomes stable again
Why Testers Should Care About Downtime
Traditional Thinking
Many testers focus only on:
- Requirement validation
- Functional correctness
- Pre-release bug detection
Meanwhile:
- DevOps handles infrastructure
- SRE handles monitoring
- Developers fix production issues
But modern software development requires broader thinking.
Testing Is Not Only About Finding Bugs
A tester can help reduce downtime significantly.
Even without directly fixing incidents.
Good Testers Ask Important Questions
Examples:
- What happens if this service fails?
- Can users recover from this error?
- Is rollback possible?
- Are logs sufficient for investigation?
- Do we have monitoring for this feature?
- Will alerts notify the right team?
These questions improve system resilience.
Shift Left AND Shift Right
Many companies focus heavily on Shift Left Testing.
That means testing earlier in development.
But teams also need Shift Right Thinking.
This means considering:
- Production monitoring
- Real-user behavior
- Incident response
- Recovery processes
- Observability
Practical Examples of Tester Contributions
1. Post-Deployment Verification
Some teams run smoke tests immediately after deployment.
These tests verify:
- Login works
- APIs respond
- Critical workflows succeed
This helps detect downtime quickly.
Example Workflow
- Deploy new release
- Run automated UI E2E tests
- Validate critical user journeys
- Trigger rollback if failures appear
2. Synthetic Monitoring
Synthetic tests simulate real users continuously.
Example checks:
- Can users log in?
- Can checkout complete?
- Can files upload successfully?
If these tests fail, teams receive alerts immediately.
3. Improving Observability
Testers can help ensure systems have:
- Useful logs
- Monitoring dashboards
- Alert rules
- Error tracking
Good observability shortens downtime.
Real-World Downtime Scenario
Scenario: Feature Flag Mistake
A company releases a new payment feature behind a feature flag.
What Happens?
- Feature flag accidentally enables for all users
- New payment logic contains a hidden edge-case bug
- Only some users experience failures initially
- Error rate stays below alert threshold
- Support receives customer complaints
- Team investigates logs
- Feature flag disabled
- System recovers
Lessons Learned
- Small mistakes can create large incidents
- Monitoring thresholds matter
- Early detection reduces downtime
- Rollback strategies are critical
How to Reduce Downtime
1. Improve Monitoring
Monitor:
- Response time
- Error rates
- CPU usage
- Database performance
- User behavior
Use tools like:
2. Use Synthetic Tests
Run automated tests continuously in production.
Focus on:
- Login
- Checkout
- Search
- File uploads
- API health
3. Build Better Alerting
Alerts should detect problems early.
Examples:
- Error rate > 5%
- Slow response time for 10 minutes
- Apdex score below threshold
4. Create Rollback Strategies
Every deployment should support safe rollback.
Examples:
- Blue-green deployment
- Canary releases
- Feature flags
5. Improve Logging
Logs should help engineers answer:
- What failed?
- When did it fail?
- Which users were affected?
- What changed recently?
6. Run Incident Drills
Practice incident response regularly.
Teams should know:
- Who responds first
- How communication works
- How recovery decisions are made
7. Perform RCA (Root Cause Analysis)
After incidents, investigate:
- What caused the problem?
- Why was detection delayed?
- How can recurrence be prevented?
This is essential for long-term improvement.
Conclusion
Downtime is not simply a technical failure.
It is the result of many connected factors:
- Monitoring quality
- Incident detection
- Alert systems
- Recovery speed
- Logging
- Deployment strategy
- Team collaboration
A small bug does not always create a major outage.
But poor detection and slow response almost always increase downtime.
Modern testing is no longer only about finding bugs before release.
It is also about helping systems survive real-world production problems more effectively.
That is why testers should care deeply about downtime.
References
- Google SRE Book
- Atlassian Incident Management Guide
- Martin Fowler – Feature Toggles
- Microsoft Reliability Engineering Guide
- Grafana Observability Learning Resources