



1. Introduction
Software testing has been a core practice in engineering for decades, ensuring applications behave as expected before reaching production. Traditional testing approaches work extremely well for deterministic systems where the same input always produces the same output.
However, with the rise of AI systems such as large language models (LLMs), chatbots, and AI agents, this assumption no longer holds. The same input can produce multiple valid outputs, making traditional testing approaches insufficient for evaluating quality and reliability.
This shift introduces a new discipline: AI testing or AI evaluation.
2. AI Testing vs Traditional Software Testing
To understand why AI systems require a different approach, let’s compare them with traditional software systems.
Traditional Software Testing
Traditional software testing is built around deterministic behavior:
- Given the same input, the system produces the same output
- Testing is based on predefined test cases
- Assertions are binary (pass/fail)
- Common methods include unit testing, integration testing, and regression testing
Example:
- Input:
2 + 2 - Expected output:
4 - Result: Always deterministic → easy to validate
This approach works well for systems like APIs, databases, and business logic layers.
AI Testing / AI Evaluation
AI systems behave differently:
- Outputs are non-deterministic
- Multiple outputs can all be considered correct
- Quality matters more than exact matching
- Evaluation often requires scoring or judging mechanisms
Instead of pass/fail, we evaluate:
- Relevance
- Accuracy
- Tone
- Completeness
- Safety
This introduces complexity because correctness is no longer binary.
Key Differences
| Dimension | Traditional Software Testing | AI Evaluation |
|---|---|---|
| Objective | Verify that software behaves according to specifications. | Measure the quality and usefulness of AI-generated outputs. |
| Expected Output | Fixed and predefined. | Flexible, with multiple acceptable responses. |
| Validation | Exact comparison with expected results. | Metric-based or model-assisted evaluation. |
| Key Quality Attributes | Correctness, reliability, and functionality. | Accuracy, relevance, coherence, safety, and factual consistency. |
| Evaluation Process | Automated assertions and regression tests. | Benchmark datasets, LLM-as-a-Judge, human evaluation, and automated metrics. |
| Typical Examples | Unit testing, integration testing, system testing. | Prompt evaluation, hallucination detection, RAG evaluation, agent evaluation. |
3. Integrating AI Testing with Traditional Software Testing
Rather than viewing AI testing and traditional software testing as competing methodologies, organizations increasingly adopt a hybrid testing strategy. Each approach addresses different challenges within the software development lifecycle, and combining them leads to a more effective and resilient quality assurance process.
Leveraging the strengths of both approaches
Traditional software testing remains the foundation for validating deterministic functionality such as business logic, APIs, security rules, and regulatory requirements. These tests provide predictable, repeatable results that are essential for verifying critical system behavior.
AI testing, in contrast, excels at tasks that benefit from automation and adaptability. It can identify unusual behaviors, generate additional test scenarios, prioritize high-risk areas, and reduce manual effort in maintaining automated test suites.
Increasing testing efficiency
As applications evolve, maintaining large collections of automated test scripts can become costly. AI-powered testing tools can automatically adjust to certain application changes, reducing maintenance overhead and allowing QA teams to focus on designing higher-value test scenarios rather than updating existing scripts.
Enabling faster software delivery
Modern development practices such as Continuous Integration and Continuous Delivery (CI/CD) require rapid feedback after every code change. AI testing accelerates this process by optimizing test execution, identifying the most relevant tests to run, and highlighting potential risks early. Traditional regression tests then provide confidence that critical functionality continues to operate correctly before deployment.
Expanding test coverage
Traditional testing validates predefined requirements and expected behaviors. AI testing complements this by exploring additional execution paths, analyzing production usage patterns, and uncovering edge cases that may not have been anticipated during test design. This combination results in broader and more comprehensive test coverage.
Summary
A hybrid testing strategy combines the reliability of traditional software testing with the adaptability and efficiency of AI-powered testing. Rather than replacing conventional testing practices, AI serves as an intelligent assistant that enhances automation, improves coverage, and helps QA teams deliver higher-quality software more efficiently.
4. Why Traditional Testing Fails for AI
As highlighted in industry discussions on AI testing vs traditional testing, conventional QA methods assume predictable outputs and fixed expected results.
In AI systems, this assumption breaks down.
For example, consider a chatbot response:
Prompt: “Explain what testing is”
Possible valid outputs:
- A short definition
- A detailed explanation
- A structured bullet list
- A simplified analogy
All of these may be correct, but traditional assertions would incorrectly mark most of them as failures.
This is the core gap: We cannot evaluate AI using strict expected outputs anymore.
Instead, we need evaluation systems that can measure quality, not just correctness.
5. The Shift Toward AI Evaluation
Because of this limitation, modern AI development introduces a new workflow:
- Define evaluation criteria (rubrics)
- Run model outputs against test sets
- Score responses based on quality dimensions
- Track performance across model versions
This is no longer “testing” in the traditional sense — it is evaluation engineering.
But manually doing this is slow and inconsistent. That’s where specialized tools come in.
6. Introducing Harbor
To address this gap, we use Harbor, an AI evaluation framework designed to help teams systematically test and measure LLM outputs.
Harbor allows you to:
- Define evaluation tasks
- Run LLM-based tests consistently
- Score outputs using structured rubrics
- Track evaluation results across versions
In short, Harbor brings structure to AI evaluation workflows.
7. Prerequisites
Before installing Harbor, make sure your development environment is ready:
| Requirement | Purpose |
|---|---|
| Python 3.10+ | Required to run Harbor |
| pip | Used to install Python packages |
| VS Code (optional) | Recommended IDE for editing evaluation projects |
| Docker Desktop/WSL | Required if running Harbor services in containers |
| OpenAI API Key | Needed for OpenAI-powered evaluations |
Check your Python version:
python --versionCheck pip:
pip --versionVerify Docker is running:
docker --version
docker psConfigure your OpenAI API key:
export OPENAI_API_KEY="your-api-key"For Windows PowerShell:
$env:OPENAI_API_KEY="your-api-key"8. Harbor Project Structure
For this demo, we will use a simple Harbor evaluation project:
my-first-eval/
├── math-task/
│ ├── instruction.md
│ ├── summary.txt
│ ├── task.toml
│ └── tests/
│ └── test_outputs.py9. Harbor Installation
Step 1: Install Harbor
pip install harbor(or your actual installation method depending on project setup)
Step 2: Initialize a project
harbor init ai-eval-demo
cd ai-eval-demoThis creates a basic evaluation project structure.
10. Creating Your First Evaluation
Instead of defining assertions against a fixed output, Harbor allows us to define evaluation requirements and validate whether the generated response satisfies them.
Example: Summary Evaluation Task
Our task is defined in instruction.md:
Write a summary about software testing.
Requirements:
- Maximum 50 words
- Must mention "testing"
- Save output to summary.txtThe generated response is stored in summary.txt:
Software testing helps ensure quality, reliability, and correctness of applications. Testing identifies defects early, reduces risks, and improves user confidence throughout the software development lifecycle.Unlike traditional testing, we are not checking for an exact sentence match. Instead, we evaluate whether the output satisfies the required conditions.
11. Running the Demo
Content of the test_outputs.py:
from pathlib import Path
def test_outputs():
summary = Path("summary.txt")
assert summary.exists(), "summary.txt does not exist"
content = summary.read_text().strip()
assert "testing" in content.lower(), \
"Output must contain the word 'testing'"
assert len(content.split()) <= 50, \
"Output must be 50 words or fewer"To run the evaluation:
pytest tests/test_outputs.py -vHarbor will:
- Read the generated output from
summary.txt - Validate it against the task requirements
- Execute the evaluation tests
- Return a PASS or FAIL result
PASS Example
============================================================================= test session starts ==============================================================================
platform linux -- Python 3.14.4, pytest-9.1.0, pluggy-1.6.0 -- /home/bindangvan/harbor-demo/my-first-eval/.venv/bin/python3
cachedir: .pytest_cache
rootdir: /home/bindangvan/harbor-demo/my-first-eval/math-task
plugins: anyio-4.14.0
collected 1 item
tests/test_outputs.py::test_outputs PASSED [100%]
============================================================================== 1 passed in 0.02s ===============================================================================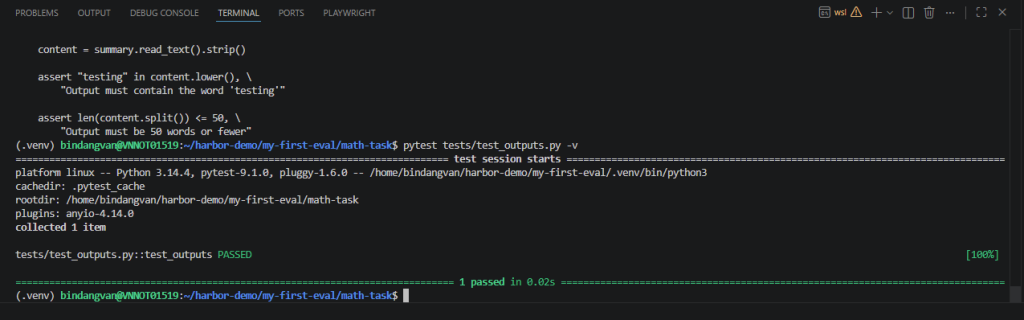
This indicates that the generated summary satisfies all evaluation requirements.
FAIL Example
If the generated output violates one of the requirements, the evaluation fails.
For example:
Software quality improves application reliability and user experience throughout development.Running the evaluation again may produce:
============================================================================= test session starts ==============================================================================
platform linux -- Python 3.14.4, pytest-9.1.0, pluggy-1.6.0 -- /home/bindangvan/harbor-demo/my-first-eval/.venv/bin/python3
cachedir: .pytest_cache
rootdir: /home/bindangvan/harbor-demo/my-first-eval/math-task
plugins: anyio-4.14.0
collected 1 item
tests/test_outputs.py::test_outputs FAILED [100%]
=================================================================================== FAILURES ===================================================================================
_________________________________________________________________________________ test_outputs _________________________________________________________________________________
def test_outputs():
summary = Path("summary.txt")
assert summary.exists(), "summary.txt does not exist"
content = summary.read_text().strip()
> assert "testing" in content.lower(), \
"Output must contain the word 'testing'"
E AssertionError: Output must contain the word 'testing'
E assert 'testing' in 'software quality improves application reliability and user experience throughout development.'
E + where 'software quality improves application reliability and user experience throughout development.' = <built-in method lower of str object at 0x760bbbb27900>()
E + where <built-in method lower of str object at 0x760bbbb27900> = 'Software quality improves application reliability and user experience throughout development.'.lower
tests/test_outputs.py:10: AssertionError
=========================================================================== short test summary info ============================================================================
FAILED tests/test_outputs.py::test_outputs - AssertionError: Output must contain the word 'testing'
============================================================================== 1 failed in 0.06s ===============================================================================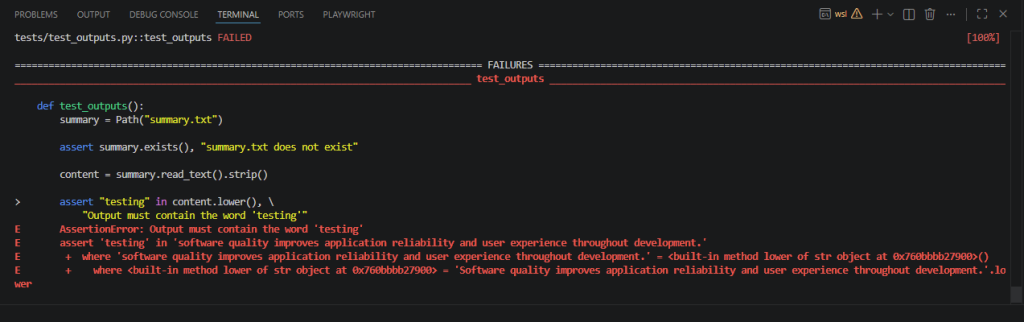
This demonstrates how Harbor can automatically detect outputs that do not comply with the defined evaluation criteria.
12. What This Demonstrates
This simple demo highlights an important shift:
- We are no longer validating exact outputs
- We are measuring quality dimensions
- Evaluation is now structured and repeatable
This is fundamentally different from traditional testing workflows.
13. Connecting Back to the Testing Gap
If we revisit the earlier comparison:
Traditional testing fails in AI systems because it assumes:
- One correct answer
- Stable output behavior
- Binary validation
AI evaluation instead assumes:
- Multiple acceptable answers
- Probabilistic outputs
- Quality-based scoring
Harbor helps bridge this gap by providing a structured evaluation framework.
14. Conclusion
The transition from traditional software testing to AI evaluation is not just a tooling change. It is a mindset shift.
- Traditional testing ensures correctness.
- AI evaluation ensures quality.
As AI systems become more complex, tools like Harbor become essential for building reliable evaluation pipelines.