



Testing, a cornerstone of software development, has long relied on the diligence of human. Nowadays, when it comes to AI era, we find ourselves at a crossroads — a moment of quiet revolution. How do we integrate these intelligent systems without losing the essence of our craft? Can technology truly enhance the precision and efficiency of testing without overshadowing the nuanced understanding that human testers bring to the table?
In this series of blog, we’ll introduce the concept of using AI to support different testing activities. We will specifically look at using AI to support defect analysis and automated test case generation. Up until now, there are quite a lot of information out there on the Internet which is looking at how to test AI-based systems. But what we cover in this blog is completely different in that we are now looking at using AI to test any form of system, either AI-based or conventional.
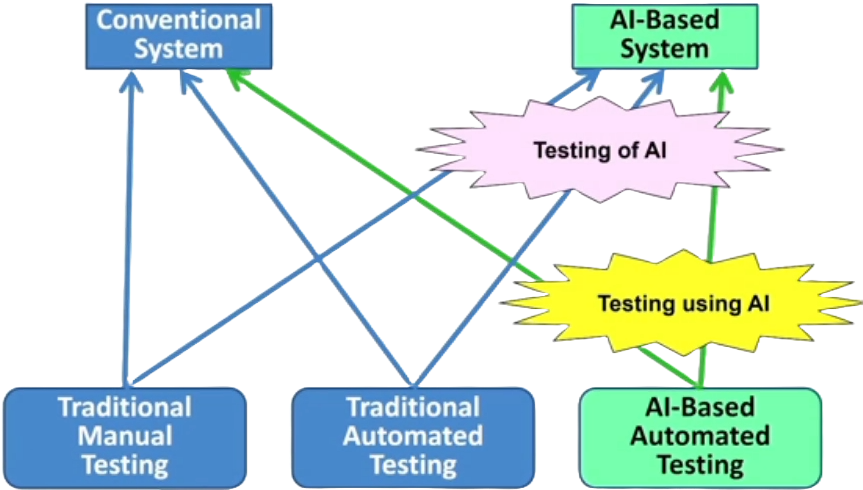
In other articles of NashTech’s quality assurance blog, we have concentrated on the testing of AI-based systems represented by the arrows going into the AI based system box in the top right of the above picture and covered by the ‘Testing of AI’ purple star. As you may be aware, both manual and automated testing can be used to test an AI-based systems. Certainly, manual and automated testing are also used to test conventional systems. This series of blog is focusing on using AI to support testing, which will therefore be automated – the green box in the lower-right corner in the picture.
This AI based automated testing can be used to test any sort of system, either conventional or AI-based systems. This means that we now have an arrow going into the AI-based system box representing the use of AI itself to test AI-based systems. This would be covered by the ‘Testing using AI’ yellow star in the picture.
AI Technologies for testing
Software testing is such a wide topic with many different aspects that practically all forms of AI can be used to support it in some way. Following are the categorisation of AI technologies used to support different testing activities:
- Classification, Learning and Prediction: usually implemented by machine learning:
- Prediction of project costs
- Defect management, defect prediction
- User interface testing.
- Computational Search and Optimisation Techniques: AI can solve optimisation problems using computational search of large and complex search spaces:
- Test cases generation
- Identification of minimal test sets to achieve a given coverage level.
- Regresion test suite optimisation.
Classification, Learning and Prediction
Classification, learning and prediction will usually be implemented by machine learning systems. These systems are often well suited to problems where the solution can be found by the analysis of patterns in large sets of historical data. Problems such as the prediction of project costs and the occurrence of defects are often suitable for machine learning implementations such as deep neural nets.
User interface testing also includes areas where the use of machine learning has been found to be useful.
Computational Search and Optimisation Techniques
AI-based search algorithms are excellent at finding potential solutions to problems, and optimisation is then used to identify the best of these solutions. Test case generation to meet various coverage requirements is a common use of such technology, and we will be covering this topic in some detail later in this series of blog.
Similarly, the optimisation of rapidly growing regression test suites to a manageable size is also covered by these technologies. The categorisations here are necessarily broad, as there is considerable overlap between the testing tasks that can be implemented by the different AI technologies.
Testing areas which are supported by AI
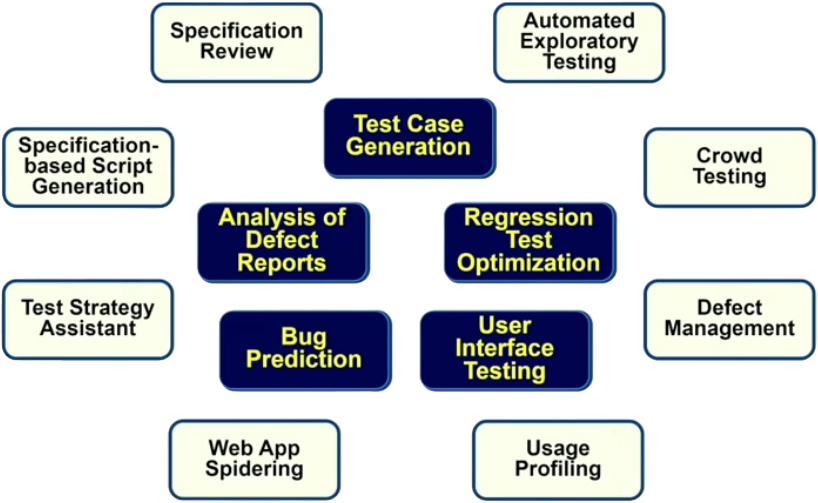
This section shows areas of software testing that are already supported by using AI. Some of these areas are better covered than others. For instance, test case generation, bug prediction and regression test optimisation are the dominant areas.
Some areas are only supported by AI partially. For instance, Specification Reviews and Specification based Script Generation are often dependent on AI based natural language processing (NLP). But other parts of these tasks are normally implemented using conventional techniques.
In this series of blog, those areas which are in the center, in dark blue of the above picture are covered in more depth.
Analysis of Defect Reports
This activity is an early part of defect management and takes place immediately after a new defect report is created. Sometimes it is called ‘defect triage’. The analysis of defect reports involves the categorisation of defects, the prioritisation of defects, and the identification of duplicate defect reports. Of course, defect management is normally considered more of a supporting process than a test process, but it is closely related to testing. After all, testers are one of the main reporters of defects, and testers should also be involved in the defect prioritisation activity.
We are now looking at the categorisation, prioritisation and assignment of defects using AI more closely. Several different AI technologies can be useful in the categorisation of defects from an analysis of defect reports. For instance, Natural Language Processing (NLP) can be used to analyse the defect description to determine which parts of the system are affected by the reported defect. Clustering algorithms can be used to group different reported defects into groups which can then be used to define the defect category that a new defect belongs to. Then AI-based text similarity metrics such as Cosine similarity matrix will be used to identify similar descriptions, which can often indicate duplicate defect reports.
The automated categorisation of defects is especially useful for systems that are widely used and include automated defect reporting such as Microsoft Windows or Mozilla Firefox. For instance, with a Firefox browser, about 50,000 bugs are reported each year and they now use a machine learning tool known as Bug Bug in replace of manual defect triaging that used to take about two days per bug. Bug Bug uses inbuilt NLP and feature extraction for bug triage.
Defect prioritisation, which determines the criticality of a reported defect, can be a time consuming activity. AI based defect prioritisation can be used on automatically reported defects to identify those defects that occur most often and so are most often reported. Using machine learning, it is possible to identify those defect reports which correspond to what are known as the top crashes.
There are usually 10 to 20 top crashes account for the large majority of crash reports. By assigning them the highest criticality and addressing them early, it is possible to reduce the number of operational crashes, therefore leading to an improved user experience and a better allocation of maintenance effort.
Following is a machine learning workflow from a research paper on the above approach. The workflow goes from left to right.
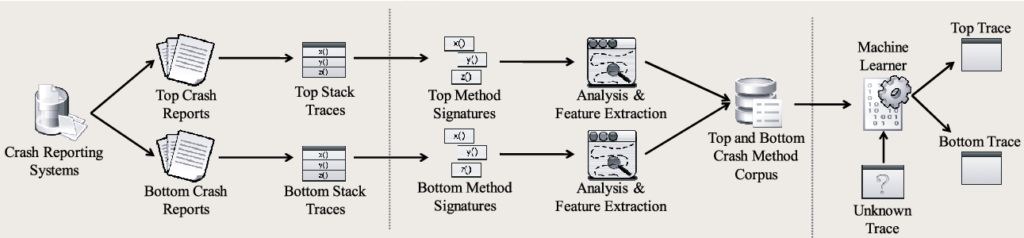
(Source: “Which Crashes Should I Fix First?: Predicting Top Crashes at an Early Stage to Prioritize Debugging Efforts” – Dongsun Kim; Xinming Wang; Sunghun Kim; Andreas Zeller; S.C. Cheung; Sooyong Park)
Initially, a database of historic defect reports is created with each defect report in it labelled as either a top crash or a bottom crash.
Top crashes are defects which occur more often, and so ideally need to be fixed quickly.
Next, features (in machine learning, a feature is an individual measurable property or characteristic of a phenomenon) are extracted from the defect reports as part of data preparation and stored along with the labels in a database for subsequent machine learning. Using the stored features and labels of top or bottom crashes, the machine learning algorithm creates a classifier that can predict if defects reported in the future correspond to either top or bottom crashes.
Once the most urgent defects have been identified, it is important that they are assigned to the best suited developer for fixing. AI based defect assignment uses machine learning to decide which developer should be assigned to a given defect based on information in the report and the success of previous bug fixing activities performed by that developer.
Automated test case generation
The next area will consider where AI is used for testing is in the area of automated test generation and execution.
Traditionally, test inputs are generated by monitoring low-level system behaviour and log files and pass them into the system under test. The system is monitored and if it crashes or returns an ‘application not responding message’, then we know there has been a failure and that there is a defect in the software. These non-AI tools are not very sophisticated in terms of the test oracle. ‘Test oracle’ is a source of information about whether the output of a program (or function or method) is correct or not. These tools do not determine if an actual result matches the expected result as they do not know the value of the expected result. All they know is that the system should not crash and should not stop responding. If that happens, then they know the system has failed and this simplicity removes the need for any human test for involvement in checking if tests have passed or failed. Non-AI based test automation tools follow this approach, but they generate the test inputs nearly randomly.
An example of this traditional tool is Google’s very popular Android Monkey for testing Android mobile apps, which uses a basic knowledge of the Android user interface to generate test inputs. This can lead to many test inputs that are obviously wrong and unlike anything a real user might attempt.
The difference with AI-based automated test generation tools is that they attempt to satisfy more goals than simply causing a failure. One reason for this is that otherwise a test case can comprise many, many thousands of steps before a failure. In this situation, too many test steps make debugging especially difficult, as the developer may not be able to identify what was the cause of the failure. So a savvier test automation tool will look for failures, but will also attempt to optimize the test chosen based on minimizing the number of steps until the failure occurs to improve debugging.
Another goal is to achieve higher code coverage. It is possible that a new test case contributes very little to increasing code coverage as it executes the same code as has been covered before. So a smarter test generation tool will optimise the test suite by selecting test cases that also increase code coverage. Obviously, such tools will need to include some instrumentation capability so that they can measure the coverage achieved by each test.
With that said, the test generation tools need to be smarter by trying to satisfy all the goals we have mentioned: Causing a failure while using a smaller number of test steps, and increasing code coverage.
Such tools are considered to be multi-objective as they try to achieve a balance of several different factors when they generate tests. It is possible to create test inputs for multi-objective test generation tools by randomly creating test inputs using a fuzz testing approach.
Moreover, more sophisticated tools also use AI to help decide which test inputs are most likely to achieve their goals, such as increasing code coverage or exercising more aspects of the user interface. By also attempting to increase coverage of the user interface, we are adding a further objective to our multi-objective problem. Some of these tools will also perform a static analysis of the code prior to generating test inputs so that the structure of the code or system states can help inform the test generation.
To give some comparison, there are two of the most well-known and free automated test generation and execution tools. The first is previously mentioned Google Monkey, which is provided as part of the Android development kit. Hence, it is used by many Android developers and testers. It’s based on fuzz testing which uses pseudo random test input generation. This is not an AI-based tool.
The other tool is Sapienz, which is also aimed at testing Android apps but is multi-objective and uses search-based AI. It has had amazing success in finding bugs in the top thousand Google Play store apps by finding 558 unique previously unknown defects. Originally developed by a team from University College London, it is now owned by Facebook.
Here we can see three comparisons between the Google Monkey Fuzz testing tool and the AI based Sapienz tool.
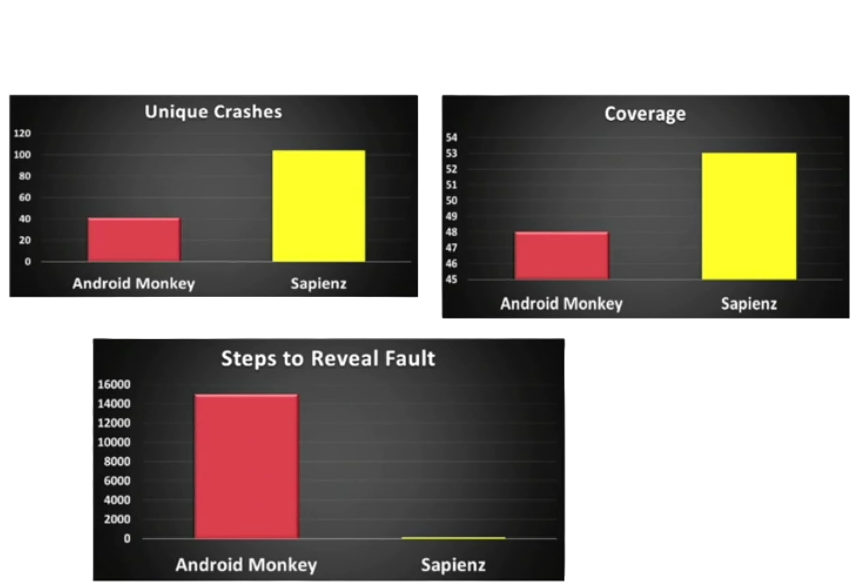
The graph in the top left shows that Sapienz caused apps to crash 104 times compared to 40 by Google Monkey. With each of these unique crashes having been caused by a separate defect.
The graph in the top right shows that Sapienz managed to achieve a slightly higher code coverage than Google Monkey with 53% compared to 48%, note that the scale on the graph does not start at zero.
The final graph shows how each tool creates test cases that cause failures that will be easier to debug – the less step required is the better one. As showed in the graph, the average number of steps until a failure is about 100 steps for Sapienz, while for Google Monkey it is about 15,000 steps. Imagine if you were the developer and had to trace back through 15,000 steps to determine which one caused a failure. Chance that a defect so well hidden could probably be left in the code.
Wrap-up
In this blog, we introduced the concept of using AI to support various testing activities, shedding light on its applications in the analysis of defects and automated test case generation. The exploration of AI in testing represents not just a technological leap but a paradigm shift in the way we approach quality assurance.
In the subsequence blogs of this series, we’ll delve into other areas which AI plays the role as a strong assistance such as Regression Test Optimisation, Bug Prediction and User Interface Testing.