



Nearly all software changes, this creates a requirement for regression testing to provide confidence that the changes made to the system have not adversely affected existing functionality. As more functionality is added, the regression test suite also tends to grow and there is often insufficient time to run all the tests every time a change is made.
With iterative development where small increments to the code are made continuously and immediately regression tested, it is especially important that regression testing is as time efficient as possible. Ideally, we aim to a way to optimise the regression test suite so that fewer tests are run, but defects are still detected.
This maintenance of the regression test suite requires the removal of out-of-date test cases and the optimisation of the remaining test cases to leave those most likely to find important regression defects.
Coverage-based optimisation
We will use AI to automatically perform coverage-based optimisation activity to leave only the most important regression tests and ideally in priority order in case regression testing ever gets cut short.
One way of optimising the test suite is to identify the coverage achieved by the regression tests and remove those tests that achieve the least coverage. On the below picture, we can see seven regression test cases: TC1to TC7.
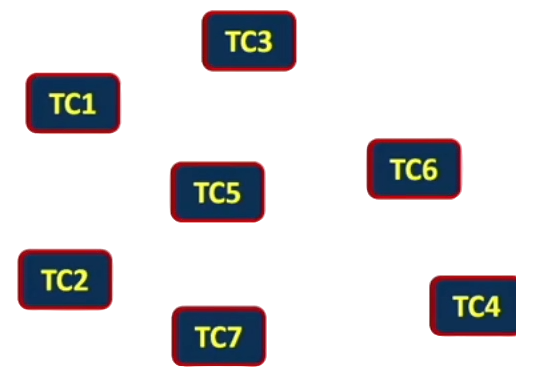
For this example, we are limiting the regression test suite to just seven test cases so that it is easier for us to reason about. In a real world situation, we may be faced with thousands or even tens of thousands of regression test cases which may take weeks or months to execute when an update to the system is available.
Let’s imagine we are interested in the code coverage achieved by running each test as we know that there is a link between higher coverage and fewer regression defects deployed to live operation. Let’s also assume that we have decided that branch coverage provides a good measure of code coverage for our system. Therefore, we want to know which regression tests give us the highest level of branch coverage. We can now see how each regression test provides coverage of different branches in the code.
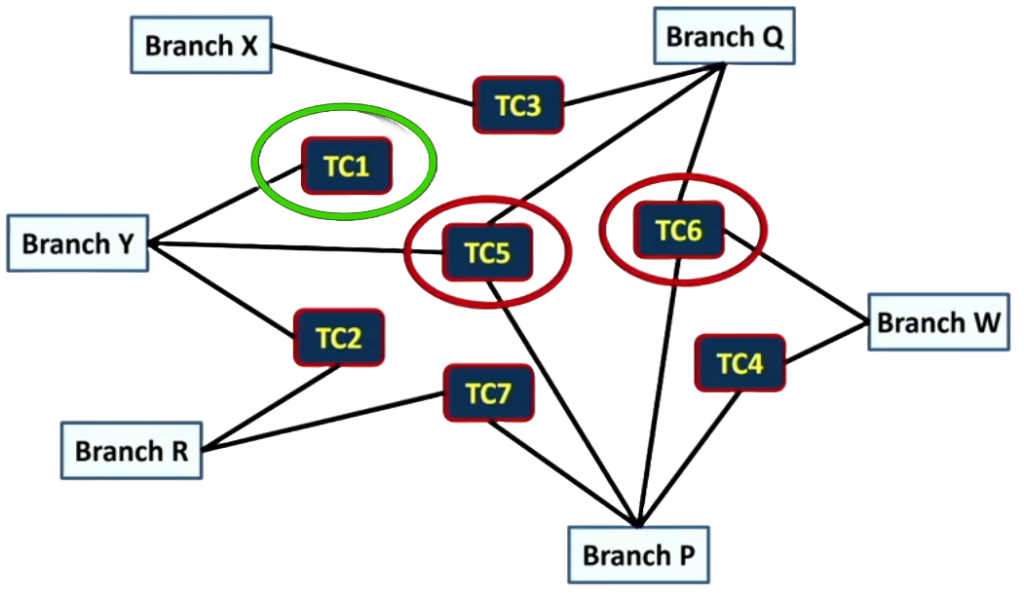
In the above picture we can see that using TC5 or TC6 looks attractive as they each cover three branches. Meanwhile, TC1 looks less attractive due to it only covering a single branch. In fact, we can see that we could cover all six branches with just three test cases TC2, TC3 and TC6.
Life is rarely so simple that we only want to optimise based on a single factor such as branch coverage. We may also want to optimise our regression test set based on the risks the tests mitigate. So now we also consider risk coverage.
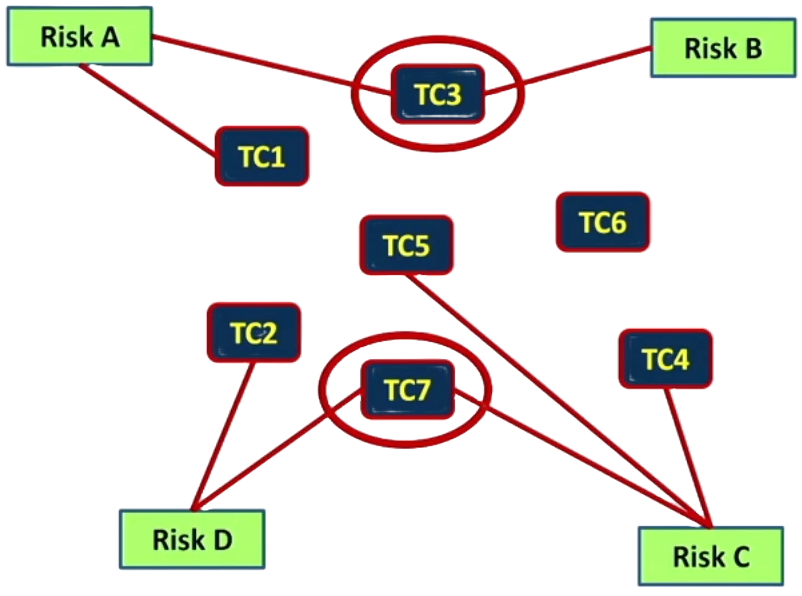
Let’s say we have four identified risks are A, B, C, and D as in the above picture. We can also see which test cases cover which risks by the red line between each risk and its corresponding test case(s). Similar to branch coverage, it is not a simple 1 to 1 mapping. In the picture, TC6 covers no specific risk. However, if we recall the previous section, TC6 does exercise several branches. In fact, just two of the seven test cases TC3 and TC7 can be used to cover all four identified risks.
We should also remember that as we make changes to the system, we also create new risks.
Defect-based optimisation
Risks and code coverage are not all we need to consider when optimising the regression suite. To a large extent, it depends on the information we have available. It’s always useful to know which test cases found defects in the past.
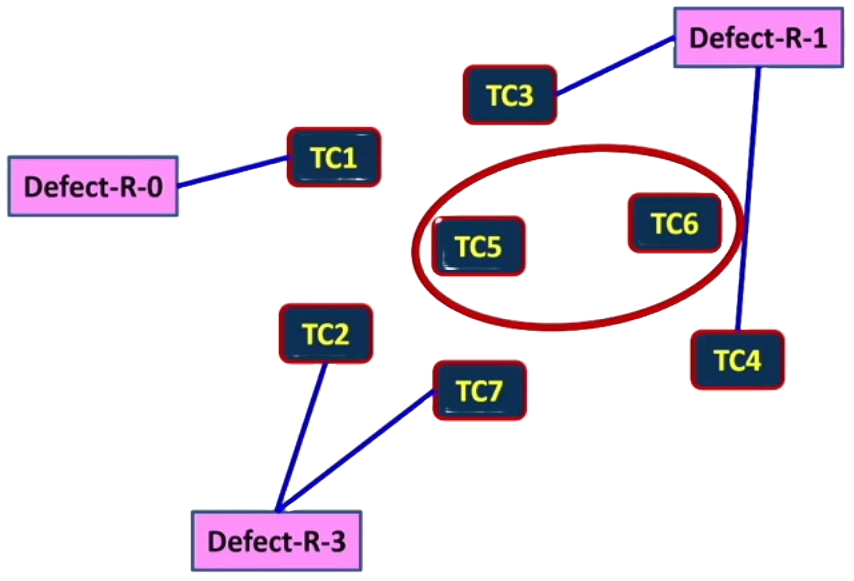
The above picture depicts that there are three defects found by regression testing. Defect-R-0 on the left is a defect that was found in the latest release, the ‘0’ corresponding to the age of the defect in terms of releases. At the top right we see Defect-R-1 corresponding to a defect found one release ago. And at the bottom we see Defect-R-3 which corresponds to a defect found three releases ago.
Similar to the previous examples, we can see which test cases found defects in previous regression tests by the blue line which points from each defect to the related test case(s). So for TC1, we see that it found a defect in the latest release, which presumably makes it at this point a very useful regression test.
Whereas we can also see that TC3 and TC4 found defects one release ago. TC2 and TC7 found defects three releases ago. And TC5 and TC6 have never found a defect.
This might suggest that we can get rid of TC5 and TC6 because they have not found a defect yet. However, that would be true of the majority of tests in most regression test suites, but it does not mean we can just discard them. These test cases may well be providing part of the safety net that tests core functionality on each release that ensures this core functionality still works.
The below picture shows us the test cases along with all three factors we previously considered: The branches covered, the risks covered and the defects found in previous releases. Of course, with only three factors, we can actually optimise a regression test suite by discarding some tests manually with some consideration. However, in practice, the great benefit of using a machine learning approach is that we can train a model to do this for us based on far more factors which would not be possible for a person to do.
We can also easily re-train the model each time we do a release so that it is always trained on the latest available data.
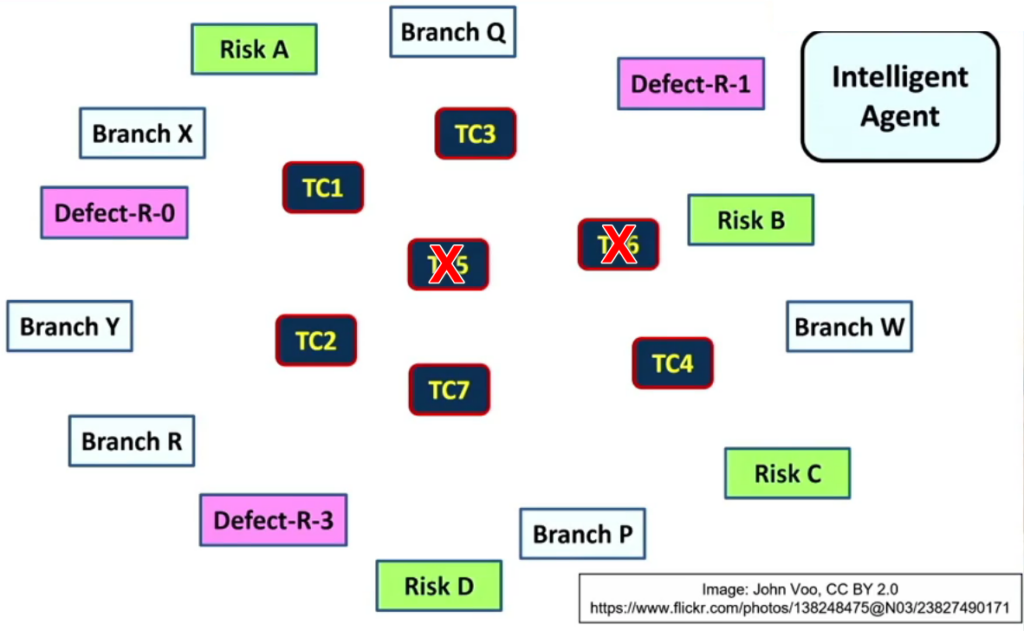
The intelligent agent that will perform the optimisation is represented in the top right of the picture. It appears as if the intelligent engine optimising the regression test suite has decided to keep five of the test cases and discard two test cases TC5 and TC6. Now that we have the five most important regression test cases.
Next, the intelligent agent can prioritise these test cases so that the most valuable test cases are always run first.

The result is that the intelligent agent recommends that TC1 is run first, then TC3, then TC4, then TC7, and finally TC2. This prioritisation is useful in case regression testing is ever cut short by circumstances such as a problem with the time or money available to fully execute all of the regression tests.
Result of Regression Test Optimised by AI
So far, we explored on how AI contribute its part in the optimisation and prioritisation process. Does regression test optimised by AI actually work in practice? The following section introduces two example results from where AI systems have been used to optimise regression test suites.
In the first example, we look at research in Norway on testing video conferencing systems and industrial mobile apps. In both projects, an Agile approach was followed with continuous integration testing.
The time to perform optimisation of the regression test suite was constrained due to it having to fit into the continuous integration and testing process. The AI-based approach uses test coverage and historical test results to identify and remove, duplicate or near duplicate test cases for both application areas: video conferencing and industrial mobile. The results were successful:
An average reduction in the time spent regression testing of 31% was achieved and a 30 to 39% reduction in the size of the regression test suite was realised with no reduction in test effectiveness.
In the second example, the ‘Honeybee Mating Optimisation Algorithm’, which used as the basis of an AI-based system for optimising a regression test suite. Algorithms inspired by nature are used in several AI areas and provide workable solutions for several practical problems.
Insect swarms are one area where search algorithms are successfully used for optimisation, and the ‘Honeybee Mating Optimization Algorithm’ is inspired by the mating strategy of honey bees. Honey bees may in a unique way, when ready to mate, the queens fly out of the hive and a swarm of drones follow them and attempt to mate with them in flight. The strongest drones succeed, drop out of the sky and then die.
Each meeting adds to a queen store of spermatozoa, and after up to 24 meetings and perhaps two flights, the queen returns to the nest with a lifetime supply for her egg laying.The most successful queen becomes the new queen for the hive while the rest are killed.

In this research, the algorithm works by trying to find a ‘queen bee’ with the maximum fault coverage in the minimum time by discarding test cases from the existing test set while maintaining the test set’s ability to identify defects. The results from 2014 showed that the test set could be optimised by 50% while still covering all the known defects and working within set time constraints.
Factors that can be used as a basis for the regression test optimisation
Previous test results provide several measures that can be used as input to the optimisation. For instance, those based on coverage, risks and fault detection as used in the example optimisation and prioritisation process we considered earlier. As time is important, especially on projects with continuous integration, execution time should also be considered and tests covering new or changed code are often valuable.
In addition to previous test results. Consideration of the defects found by previous tests gives an insight into what future defects are more likely.
The latest updates to the system also need to be covered by the regression test suite on the next update.
Finally, if we have information on which system features are broken most often, then we should also include this as a factor.
Wrap-up
From the inception of this series of blog, we delved into the transformative influence of AI on traditional testing methodologies. The spotlight on regression test optimisation showcased how intelligent algorithms can swiftly adapt to the ever-evolving demands of software development, ensuring not just speed but a heightened level of precision in identifying and addressing potential issues.
As we bid farewell to this exploration, let’s carry forward the understanding that the synergy between AI and testing is not just a trend but a paradigm shift. Embracing AI’s role in regression test optimisation opens doors to continuous improvement, adaptability, and a future where software reliability and innovation go hand in hand.