




A big player in the tech world, making over a billion dollars and being one of the top companies worldwide.
Introduction
Let’s take a trip down memory lane exploring the history of Databricks. It all started in 2003 when big data got a lift with the arrival of Hadoop. Inspired by Google’s File System (GFS) and MapReduce, folks realized they needed a way to handle massive amounts of data. Enter Hadoop, born out of the necessity for more oomph due to challenges with fewer cluster nodes. They tested it on 1000-node clusters, then scaled up to 4000-node clusters—big success!
Next on the scene was Hive, solving issues with storing data. And then, Spark stole the spotlight, diving in to tackle tricky problems like iterative algorithms and real-time data needs for streaming applications. The plot thickened when Netflix threw a challenge into the mix, Databricks came to life.
So, in the history of Databricks, we’ll discover how big data went from Hadoop to Spark, and eventually, how Databricks became the superhero in the world of data processing. Let the journey begin!
Evolution of Hadoop
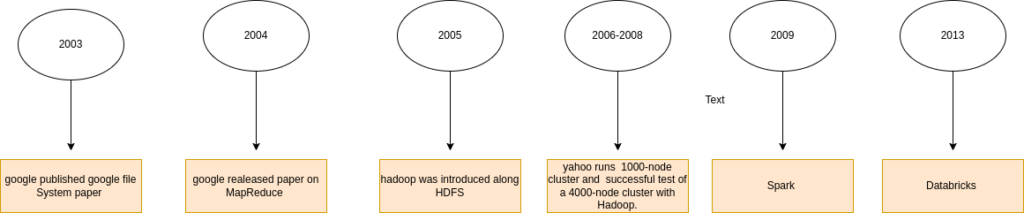
In 2003, Hadoop’s founders, Doug Cutting and Mike Cafarella, stumbled upon a groundbreaking paper detailing the Google File System (GFS). This system, crafted for storing extensive datasets, emerged as a potential solution to challenges in handling large, separated datasets resulting from the web crawling process. However, it was evident that GFS alone constituted only half of the solution.
In 2004, a crucial development occurred with the publication of an article introducing the MapReduce technique—a key solution for processing large datasets. Despite being another essential piece of the puzzle, these solutions remained confined to the realm of theory and were yet to be implemented. To bridge this gap, Doug Cutting and Mike Cafarella took the initiative to implement MapReduce and GFS as open-source components within the Apache Nutch project—a significant step toward realizing Hadoop’s transformative capabilities.
Evolving Hadoop: Unveiling the Challenges in GFS and MapReduce
In 2005, a limitation was discovered in the Hadoop project by Doug Cutting. The system found itself confined to a modest 20 to 40 clusters, posing challenges in managing the increasing number of files and their processing needs. Complicating matters was the fact that only two people were handling this workload. To address the expanding requirements, the imperative need for a more substantial cluster setup and a larger team was recognized.
The Birth of a Scalable Framework “Hadoop”
In 2006, Doug Cutting embarked on a transformative journey when he joined Yahoo, introducing the world to an open-source, reliable, and scalable computing framework. Collaborating with Yahoo, he spearheaded the separation of distributed computing, birthing a groundbreaking project—Hadoop. Under Doug Cutting’s guidance, Hadoop underwent a meticulous transformation, evolving to seamlessly function on thousands of nodes. Utilizing the power of GFS and MapReduce, the team began shaping the future of distributed computing.
The pivotal year of 2007 marked a significant milestone as Yahoo successfully tested Hadoop on a 1000-node cluster, propelling it into practical application within the company. The impact rippled further when, in July of 2008, the Apache Software Foundation achieved a groundbreaking feat—a successful test of a 4000-node cluster with Hadoop. This marked the ascendancy of Hadoop as a robust and scalable framework, laying the foundation for its widespread adoption in the realm of big data processing.
Simplifying Big Data Operations: The Hive Advantage in Hadoop Ecosystem
As Hadoop gained popularity, a common hurdle emerged: the necessity to write Java MapReduce code for every data operation, even for seemingly basic tasks like selecting data with a SQL query. Apache Hive emerged as a solution to this challenge. Serving as both a data warehouse and ETL tool, Hive provides users with an SQL-like interface, seamlessly connecting them with the Hadoop distributed file system (HDFS). Imagine working with HDFS data as if it were in standard relational tables—this is the simplicity Hive brings to data operations. Acting as a compiler, Hive transforms SQL statements into Java MapReduce code, streamlining the complexities of reading, writing, and processing data in the Hadoop ecosystem.
Evolution of Apache Spark

During that period, technology witnessed the emergence of big data as a focal point. Initially, Hadoop MapReduce stood at the forefront, serving as a leading parallel programming engine for clusters. It quickly gained global acceptance for addressing data-parallel processing on extensive clusters. However, its efficiency faced hindrances, especially for multi-pass applications requiring low-latency data sharing and parallel operations. Consequently, the evolving landscape of big data processing generated a growing need for more streamlined solutions.
Several common use cases faced challenges with Hadoop MapReduce:
- Iterative algorithms in machine learning and graph analysis:
- Where data is repeatedly loaded from different memory sources and queried in an iterative manner.
- Streaming applications that require maintaining current state based on the latest data:
- Applications continuously updating data faced obstacles in ensuring the current state due to the limitations of Hadoop Map Reduce.
For instance, in the context of machine learning, a typical algorithm might need to undergo 10 or 20 passes over the data. However, in the MapReduce framework, each pass had to be scripted as an individual Map Reduce job. This necessitated separate launches on the cluster and reloading the data from scratch.
Inception of Spark
Spark introduced a superior programming abstraction, RDD (Resilient Distributed Dataset). RDDs can store in memory between queries and cache for repetitive processes. They represent read-only collections of partitioned objects across various machines and demonstrate fault tolerance, enabling the recreation of an identical copy from scratch in the event of process or node failure.
From Netflix’s Challenge to World Record: The Birth of Databricks in 2013
The inception of Databricks stemmed from a challenge faced by Netflix’s machine learning team. Recognizing the complexity in developing predictive models for movie recommendations based on user readings and preferences, Netflix initiated an open competition to seek solutions.
Seizing this opportunity, Spark presented a solution and achieved a world record for data sorting speed. Consequently, Matei Zaharia’s contributions earned him an award for the best computer science citation of the year.
Following this success, the birth of Databricks ensued. Given the chance to provide software services, the team saw an opportunity to share their technology globally. In response, they conceived the idea of starting a company, ultimately leading to the establishment of Databricks in 2013.
Seven Co-Founders Behind Databricks: Collaborators from UC Berkeley
- Aslam Tabakia – Co-founder & SVP of Field Engineering
- Ion Stoica – Co-founder and Executive Chairman
- Andy Konwinski – Co-founder and VP of Product Management
- Reynold Xin – Co-founder and Chief Architect
- Patrick Wendell – Co-founder
- Ali Ghodsi – CEO and Co-founder
These individuals, many of whom collaborated at UC Berkeley, played key roles in shaping Databricks.
Overcoming Limitations: How Databricks Revolutionized Big Data Challenges
Big companies want strong support when they use new technology. They need professional help for any problems. While community projects help a bit, they don’t have the dedicated support that big companies need. This need led to the creation of Databricks
Code Quality:In the realm of open-source projects like Spark, the quality of contributed code can be inconsistent. Databricks emerged to offer a commercial version of Spark, ensuring a level of quality and reliability for enterprise customers.
Deployment and Management :Deploying and managing Spark, especially on a large scale, poses complexities. Recognizing these challenges, the founders of Spark established Databricks to provide a platform that simplifies Spark deployment and management, particularly at scale.Databricks takes care of setting up and handling your cloud stuff automatically, so you don’t have to do it manually
Conclusion
Started in 2003, Hadoop revolutionized big data. Doug Cutting and Mike Cafarella laid its foundation inspired by Google’s tech. In 2006, at Yahoo, Cutting scaled it up.
Hadoop’s was successfully tested on 1000 and 4000-node clusters faced new challenges. Enter Spark in response, solving Hadoop issues with RDD for faster data processing.From Spark’s success, Databricks was born in 2013, tackling Netflix’s data challenge. Matei Zaharia’s achievements set a world record, giving birth to Databricks.Databricks, shaped by seven UC Berkeley minds, became the link between Hadoop and Spark. It simplified big data operations, connecting cluster management to Spark’s efficient processing. The journey illustrates how collaboration turned an idea into a billion-dollar tech player.
To start with the databricks follow this link :- setting-up-data-bricks-for beginners
External links:-
- https://medium.com/mlearning-ai/databricks-vs-spark-introduction-comparison-pros-and-cons-35958a1bd7e4
- https://www.geeksforgeeks.org/hadoop-an-introduction/
- https://medium.com/@shraddhabag7583/meet-hadoop-d85795c2d587
- https://www.geeksforgeeks.org/hadoop-history-or-evolution/
- https://medium.com/@chuck.connell.3/databricks-a-history-d8dd12fe9695
- https://blog.nashtechglobal.com/getting-started-with-data-bricks-a-step-by-step-guide-for-beginners/