



Let’s understand microservices:
Imagine Netflix, which uses a modern software design called microservices. Instead of one big component, they break their app into small pieces just like pieces of cake, independent parts, like building blocks. These parts, or microservices, interact with each other using a special set of rules called APIs (Application Programming Interface).
Developers can use the most suitable tools for each component. They deploy different tools for various tasks, but they all seamlessly integrate. Additionally, if one-part experiences an issue, it does not affect the entire system. It is similar to having multiple small safety nets rather than a single large one.
Due to a monolithic architecture and proprietary data centers, Netflix experienced a significant downtime. This occurrence was a turning moment, prompting Netflix to implement continuous deployment and separate their applications to avoid future problems. Microservices were critical in preventing single-stack breakdowns and encouraging experimentation. This transition improved agility, allowing for practices such as Chaos Engineering and contributing to Netflix’s rapid expansion. Each program now oversees a distinct aspect of Netflix’s operations, resulting in the company’s current status as a powerhouse.
The monolithic architecture was historically used by developers for a long time — and for a long time, it worked. Unfortunately, these architectures use fewer parts that are larger, thus meaning they were more likely to fail in entirety if a single part failed. Often, these applications ran as a singular process, which only exacerbated the issue.
Microservices solve these specific issues by having each microservice run as a separate process. If one cog goes down, it doesn’t necessarily mean the whole machine stops running. Plus, diagnosing and fixing defects in smaller, highly cohesive services is often easier than in larger monolithic ones.
Microservices design patterns provide tried-and-true fundamental building blocks that can help write code for microservices. By utilizing patterns during the development process, you save time and ensure a higher level of accuracy versus writing code for your microservices app from scratch.
Liked Object Oriented Design Patterns, Microservice Patterns are also tried and tested solution of common problems people have encountered while developing, deploying and scaling their Microservices.
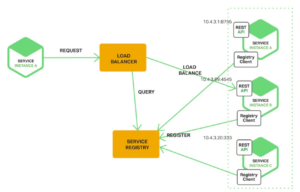
What is Microservices Design Patterns
Microservices design patterns are established solutions and architectural strategies used in the development of microservices-based systems. They encapsulate best practices and guidelines for designing individual services and orchestrating interactions between them within a distributed environment. These patterns address various concerns such as communication protocols, data consistency, fault tolerance, and scalability, allowing developers to create modular, resilient, and scalable architectures. By applying these patterns, development teams can efficiently navigate the complexities of microservices design and implementation, leading to more manageable, adaptable, and robust software systems.
Key benefits of using microservices design patterns
Knowing the key benefits of microservices will help you understand the design patterns. The exact benefits may vary based on the microservices being used and the applications they’re being used for. However, developers and software engineers can generally expect the following advantages when using microservices design patterns:
- Developing an application architecture that is autonomously deployable and distributed.
- Massive scalability when and if needed.
- New versions of microservices that can be rolled out incrementally, thus reducing downtime.
- Identifying undesirable behaviour prior to fully replacing an older version of an application.
- Employing various coding languages Avoiding systemic failures stemming from a single.
- Root cause within an isolated component Implementing real-time load balancing.
Microservices Design Patterns:
1. Database per service pattern
The database is one of the most important components of microservices architecture, but it isn’t uncommon for developers to overlook the database per service pattern when building their services. Database organization will affect the efficiency and complexity of the application. The most common options that a developer can use when determining the organizational architecture of an application are:
Dedicated database for each service:
A database dedicated to one service can’t be accessed by other services. This is one of the reasons that makes it much easier to scale and understand from a whole end-to-end business aspect.
Picture a scenario where your databases have different needs or access requirements. The data owned by one service may be largely relational, while a second service might be better served by a NoSQL solution and a third service may require a vector database. In this scenario, using dedicated services for each database could help you manage them more easily.
This structure also reduces coupling as one service can’t tie itself to the tables of another. Services are forced to communicate via published interfaces. The downside is that dedicated databases require a failure protection mechanism for events where communication fails.
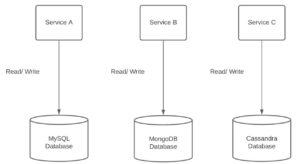
Single database shared by all services:
A single shared database isn’t the standard for microservices architecture but bears mentioning as an alternative nonetheless. Here, the issue is that microservices using a single shared database lose many of the key benefits developers rely on, including scalability, robustness and independence.
Still, sharing a physical database may be appropriate in some situations. When a single database is shared by all services, though, it’s very important to enforce logical boundaries within it. For example, each service should own its have schema and read/write access should be restricted to ensure that services can’t poke around where they don’t belong.
// Entity class representing a User
public class User
{
}
// DbContext for accessing User data
public class UserDbContext : DbContext
{
public DbSet<User> Users {get; set;}
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
optionsBuilder.UseSqlServer(“connection_string_to_shared_database”);
}
}
In this example, we define a User entity class and a UserDbContext class for managing user-related data. This approach represents a Database per Service pattern where all microservices share a single database.
2. Saga pattern
A saga is a series of local transactions. In microservices applications, a saga patterncan help maintain data consistency during distributed transactions.
The saga pattern is an alternative solution to other design patterns that allows for multiple transactions by giving rollback opportunities.
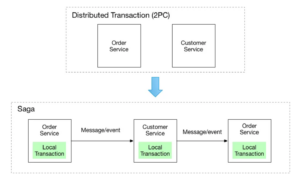
A common scenario is an e-commerce application that allows customers to purchase products using credit. Data may be stored in two different databases: One for orders and one for customers. The purchase amount can’t exceed the credit limit. To implement the Saga pattern, developers can choose between two common approaches.
1. Choreography:
Using the choreography approach, a service will perform a transaction and then publish an event. In some instances, other services will respond to those published events and perform tasks according to their coded instructions. These secondary tasks may or may not also publish events, according to presets. In the example above, you could use a choreography approach so that each local e-commerce transaction publishes an event that triggers a local transaction in the credit service.
Choreography Example:
// OrderPlacedEvent class
public class OrderPlacedEvent
{
public int OrderId {get; set;}
}
// OrderPlacedEventHandler
public class OrderPlacedEventHandler : IHandleMessages<OrderPlacedEvent>
{
public async Task Handle(OrderPlacedEvent message)
{
// Logic to handle OrderPlacedEvent
}
}
example, when an order is placed, the OrderPlacedEvent is published by the Order Service. The OrderPlacedEventHandler in another service listens to this event and performs the necessary actions.
2. Orchestration:
An orchestration approach will perform transactions and publish events using an object to orchestrate the events, triggering other services to respond by completing their tasks. The orchestrator tells the participants what local transactions to execute.
Saga is a complex design pattern that requires a high level of skill to successfully implement. However, the benefit of proper implementation is maintained data consistency across multiple services without tight coupling
Orchestration Example:
// OrderSagaOrchestrator class
public class OrderSagaOrchestrator : Saga<OrderSagaData>,
IAmStartedByMessages<PlaceOrderCommand>,
IHandleMessages<OrderBilledEvent>,
IHandleMessages<OrderShippedEvent>
{
public async Task Handle(PlaceOrderCommand message)
{
// Logic to handle PlaceOrderCommand and initiate saga
}
public async Task Handle(OrderBilledEvent message)
{
// Logic to handle OrderBilledEvent
}
public async Task Handle(OrderShippedEvent message)
{
// Logic to handle OrderShippedEvent
}
}
Example, the OrderSagaOrchestrator class acts as the central orchestrator managing the saga. It handles messages like PlaceOrderCommand, OrderBilledEvent, and OrderShippedEvent, orchestrating the flow of the saga.
3. API gateway pattern
The API gateway pattern offers a streamlined solution for managing large applications with multiple clients. Acting as a reverse proxy, it shields clients from service partitioning complexities and enables independent evolution of service boundaries. With a single entry point, clients navigate fewer services, enhancing ergonomics and reducing roundtrips for data retrieval.. Moreover, the pattern handles critical tasks like authentication and caching, fortifying app security and user experience. By minimizing the attack surface area and decoupling internal microservices, it ensures resilience against partial failures. Utilizing caching, it efficiently manages responses, ensuring uninterrupted service even in the face of microservice.
API Gateway Example:
// ApiGateway class
public class ApiGateway
{
private readonly IBus bus;
public ApiGateway(IBus bus)
{
this.bus = bus;
}
public async Task PlaceOrder(string orderId)
{
// Logic to forward the request to the appropriate microservice
}
}
Example, the ApiGateway class is responsible for handling API gateway functionality. It forwards requests to the appropriate microservice.
4. Aggregator design pattern
An aggregator design pattern is used to collect pieces of data from various microservices and returns an aggregate for processing. Although similar to the backend-for-frontend (BFF) design pattern, an aggregator is more generic and not explicitly used for UI.
Aggregator example:
// Define an aggregator class
public class OrderAggregator
{
private readonly List<Order> orders = new List<Order>();
// Method to add an order to the aggregator
public void AddOrder(Order order)
{
orders.Add(order);
}
// Method to get aggregated orders
public List<Order> GetAggregatedOrders()
{
return orders;
}
}
// Define an Order class
public class Order
{
public int OrderId { get; set; }
public string CustomerName { get; set; }
public decimal TotalAmount { get; set; }
// Other order properties...
}
In this example:
- We define an
Orderclass to represent an order with properties likeOrderId,CustomerName, andTotalAmount. - We define an
OrderAggregatorclass to aggregate orders. It maintains a list of orders and provides methods to add orders (AddOrder) and retrieve aggregated orders (GetAggregatedOrders).
This example illustrates the Aggregator pattern, where the OrderAggregator class aggregates individual orders into a single collection, simplifying the process of working with multiple orders.
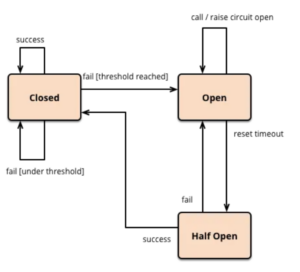
5. Circuit breaker design pattern
The circuit breaker pattern acts as a safety net between synchronously communicating services. When a service experiences high latency or becomes unresponsive, the circuit breaker steps in to prevent cascading failures across multiple systems. By diverting calls away from the problematic service, it prevents resource overload and potential app slowdowns or failures. This pattern works by monitoring failure conditions, and when triggered, it stops all calls to the failing service, redirecting them elsewhere or returning a default error message.
To complete tasks, the aggregator pattern receives a request and sends requests to multiple services based on the tasks assigned to it. Once every service has answered the requests, this design pattern combines the results and initiates a response to the original request.
- Open: A circuit breaker pattern is open when the number of failures has exceeded the threshold. When in this state, the microservice gives errors for the calls without executing the desired function.
- Closed: When a circuit breaker is closed, it’s in the default state and all calls are responded to normally. This is the ideal state developers want a circuit breaker microservice to remain in — in a perfect world, of course.
- Half-open: When a circuit breaker is checking for underlying problems, it remains in a half-open state. Some calls may be responded to normally, but some may not be. It depends on why the circuit breaker switched to this state initially.

6. Event sourcing
The event sourcing pattern is handy in microservices when you want to record every change in an entity’s state. By using event stores like Kafka, you can track these changes effectively, almost like keeping a log of events. These stores also serve as message brokers, ensuring smooth communication between microservices by managing messages. With event sourcing, each state-changing event is stored, allowing you to reconstruct the entity’s current state by replaying these events. It’s particularly useful when transactions are crucial and you want to avoid tinkering with the existing data layer codebase.
9. Strangler
Developers mostly use the strangler design pattern to incrementally transform a monolith application to microservices. To achieve this successful transfer from monolith to microservices, developers use a facade interface to expose individual services and functions. They break free the targeted functions from the monolith so they can be “strangled” and replaced. This involves replacing old functionality with a new service, thus earning the pattern its name. Once developers have the new service ready for execution, they “strangle” the old service to allow the new one to take over.
10. Decomposition patterns
Decomposition design patterns break a monolithic application into smaller, more manageable microservices. A developer can achieve this in one of three ways:
1. Decomposition by business capability:
Many businesses have more than one business capability. For example, an e-commerce store is likely to have capabilities that include managing product catalogs, inventory, orders, and delivery. In the past, businesses might have used a single monolithic application for every service, but if, for instance, the business decides to create a microservices application to manage these services moving forward, they might choose to use decomposition by business capability in this common scenario.
This may be used when an application has a large number of interrelated functions or processes. Developers may also use it when functions or processes are likely to change frequently. The benefit is that having more focused, smaller services allows for faster iterations and experimentation.
2. Decomposition by subdomain:
This approach is well suited for exceptionally large and complex applications that employ a lot of business logic. For example, you might use this if an application uses multiple workflows, data models and independent models. Breaking the application into subdomains helps make managing the codebase easier while facilitating faster development and deployment. An easy-to-grasp example includes hosting a blog on a separate subdomain (for instance, blog.companyname.com). This approach can separate the blog from the root domain’s business logic.
3. Decomposition by transaction:
This is an appropriate pattern for many transactional operations across multiple components or services. Developers could choose this option when there are strict consistency requirements. For example, consider cases in which someone submits an insurance claim. The claim request might interact with both a Customers application and Claims microservices at the same time.
Utilizing design patterns to make organization more manageable
Setting up the proper architecture and process tooling will help you create a successful microservice workflow. Learn more about microservices in my upcoming related Nash-Blog.