



Introduction
In the digital landscape, where data flows incessantly, managing and processing vast streams of information efficiently has become paramount. Enter Apache Kafka, a distributed streaming platform that has revolutionized the way organizations handle real-time data. In this blog, we’ll embark on a journey into the depths of Apache Kafka, exploring its architecture, key concepts, and practical applications.
Understanding Apache Kafka: Apache Kafka, initially developed by LinkedIn, has gained widespread adoption across industries for its scalability, fault tolerance, and high throughput capabilities. At its core, Kafka enables the building of real-time data pipelines, facilitating the seamless ingestion, storage, processing, and delivery of streaming data.
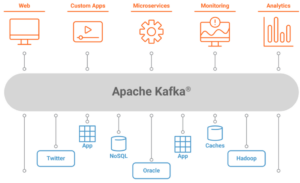
Architecture: Kafka’s architecture is structured around a few fundamental components:
- Producer: Entities responsible for publishing data to Kafka topics.
- Broker: Kafka runs as a cluster of one or more servers, known as brokers, each responsible for storing and managing topic partitions.
- Topic: A category or feed name to which records are published by producers.
- Partition: Each topic is split into one or more partitions, which are ordered, immutable sequences of records.
- Consumer: Entities that subscribe to one or more topics and process the data.
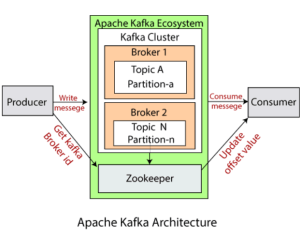
Key Concepts
To navigate Kafka effectively, it’s essential to grasp key concepts:
- Brokers: Kafka clusters consist of multiple brokers, each identified by a numeric ID and responsible for managing topic partitions.
- Topics and Partitions: Topics are divided into partitions for scalability and parallelism. Each partition is an ordered sequence of records.
- Producers and Consumers: Producers publish records to topics, while consumers subscribe to topics to process these records.
- Consumer Groups: Consumers within the same group divide the workload by subscribing to different partitions of a topic, enabling parallel processing.
- Offsets: Each message within a partition is assigned a unique identifier called an offset, indicating its position within the partition.
- Replication: Kafka provides fault tolerance through data replication across multiple brokers, ensuring data durability and availability.
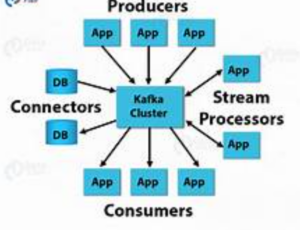
Practical Applications
The versatility of Kafka makes it applicable across various use cases:
- Real-time Data Processing: Kafka powers real-time analytics, monitoring, and alerting systems by enabling the continuous processing of streaming data.
- Event Sourcing: Kafka serves as a foundational component for event sourcing architectures, where all changes to application state are captured as immutable events.
- Log Aggregation: Kafka consolidates logs from multiple sources, providing a centralized platform for log aggregation and analysis.
- Microservices Communication: Kafka facilitates communication between microservices in a distributed system, enabling seamless data exchange.
- IoT Data Management: With its scalability and fault tolerance, Kafka efficiently handles the massive volume of data generated by IoT devices.
.NET Integration
Apache Kafka has robust support for the .NET ecosystem, allowing developers to seamlessly integrate Kafka into their .NET applications. This integration is made possible through various client libraries, including Confluent.Kafka, which provides native bindings to the librdkafka library.
- Confluent Platform for .NET: Confluent offers a .NET client library that simplifies Kafka integration for .NET developers. This library provides high-level abstractions for producing and consuming messages, handling offsets, and managing consumer groups.
- Async Support: The Confluent.Kafka library leverages asynchronous programming patterns, enabling .NET developers to build highly responsive and scalable Kafka applications. Asynchronous operations help mitigate performance bottlenecks by allowing concurrent processing of messages.
- Avro Serialization: Apache Avro, a binary serialization format, is widely used with Kafka for efficient data serialization and schema evolution. .NET developers can leverage Avro serialization/deserialization capabilities through libraries such as Confluent.SchemaRegistry.Serdes.Avro, enabling seamless integration with Kafka’s schema registry.
- Integration with .NET Frameworks: Kafka integration extends beyond standalone .NET applications. Developers can seamlessly integrate Kafka with popular .NET frameworks like ASP.NET Core for building real-time web applications, microservices, and event-driven architectures.
- Monitoring and Management: Kafka’s ecosystem includes tools like Kafka Connect and Kafka Streams for building data pipelines and stream processing applications. .NET developers can interact with these components using RESTful APIs, allowing seamless integration with monitoring, management, and operational tools built on .NET frameworks.
- Security and Authentication: Kafka supports various authentication mechanisms, including SSL/TLS encryption and SASL (Simple Authentication and Security Layer). .NET developers can configure client-side authentication and authorization to ensure secure communication with Kafka clusters, protecting sensitive data and ensuring compliance with security standards.
- Community and Support: The .NET community actively contributes to Kafka’s ecosystem by developing libraries, tools, and extensions tailored for .NET developers. Additionally, forums, documentation, and community-driven resources provide valuable support for .NET developers navigating Kafka integration challenges.
Conclusion
Apache Kafka has emerged as a cornerstone technology for building scalable, real-time data pipelines. Its distributed architecture, coupled with robust features, makes it indispensable for organizations navigating the complexities of modern data management. By understanding Kafka’s architecture, key concepts, and practical applications, businesses can harness the power of streaming data to drive innovation and stay ahead in today’s data-driven world.