



Image created by Copilot
Introduction
With the raise of Generative AI, currently, there are many applications built on top of Large Language Model, such as Chatbot, conversational agent in customer service, sale …
LLM based app can be a kind of application that use company current data and knowledge to do specific tasks such as interactive guide, education learning application for example Khan Academy can adapt to learner’s level.
Another kinds of LLM apps is chat with data or RAG – retrieval augmented generation. These kinds of app are very popular now. The idea is we get some sort of information retrieval system, and the user can use a LLM to access the information then the system bring the data, by answering the questions. It has the ability to use natural language to interact with data quickly.
One more kind of LLM based application is autonomous agent with multi-step reasoning. It can do complex task with minimal human-decision making involvement.
As Generative AI and Large Language Model are really new and challenges in testing an LLM based application, how can we evaluate its quality is an important question as you can’t release the product without testing. With no industry standard, evaluating the quality of LLM based applications remain difficult problem today.
Some of the challenges in evaluation quality of LLM based application could be:
How can we ensure response are aligned with human grading?
What is the appropriate grade scale?
Across different use case, how can the same evaluation metric, for example accuracy, be reused?
In this post, we will focus on discussion some existing method related to evaluate the functional aspect of LLM based applications and its pitfalls.
How does a quality LLM based application look like?
To break down into quality view, quality aspects that a LLM based application must satisfy:
- Correctness
- Explainability
- Performance
- Security
- Coverage
Note: Coverage is an important aspect in evaluation quality, it can be understood that most data in the production “look like” some of the data in your evaluation data set. The coverage will be discussed deeply in another post.
As in this post we focus on functional evaluation so we will deep dive into correctness aspect. Correctness means that the response from the LLM based application must be:
- Accuracy: the response is precisely and relevant to the question
- Completeness: Response include all necessary and essential content
- Readability: Logically, in a readable format, coherent, understandable
- Usability: suitable tone used, suitable error handling and must awareness on previous interaction which means context relevant.
To quantitatively evaluate this, we must have good metrics to compare.
So, how is a good evaluation metric?
A good evaluation metric must satisfy below criteria:
- Quantitative: Has quality metrics that can predict the outcomes on those test examples and fast to compute a score. This helps organizations set minimum passing threshold to determine how is “good enough” and monitor the number through development life cycle.
- Reliable: as LLM output are unpredictable so our metrics must be reliable to confident evaluate.
- Accurate: the metric has to know if the output is highly aligned with human judgment.
So how can we create reliable and accurate score?
Currently, there are a number of different methods to calculate metric score, some using statistical methods, some are using neural networks as in below image.

Traditional method
The NLP traditional metrics are based on statistical analysis:
- BLEU (Bilingual Evaluation Understudy): a common metric used in machine translation. BLEU evaluates the translated text with a set of high quality references translation. However, it based on the precision of word match, often overlooking the context and semantics so the response has similar meaning but using different words won’t get the high score.
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation) is primary used for evaluation text summary by comparing the overlaps of n-grams between the output with the expectation. It still based on exact match and not take semantic into account.
- …
We will go into an example to illustrate this. In the below example, the first sentence is the reference to evaluate. The second is the output of the LLM based application for the task “Rewrite the sentence to keep the same meaning”. We use the BLUE score in simple form to evaluate the output, in A the score is 7/9 is lower than in B, the score is 9/10. However, the meaning of the response is totally different in B and if we base on this score to evaluate for the quality, it is not meet accurate requirement for a metric.


So, the traditional NLP metrics are hardly to use in evaluating LLM output that are long and complex, they have poor correlation to human judgment.
Embedding-model method
The ideas of embedding-model method is to compare candidate text with reference text by leverage the vector representation of text from the model. Then the similarity of candidate text and reference text is quantified using method such as cosine similarity.
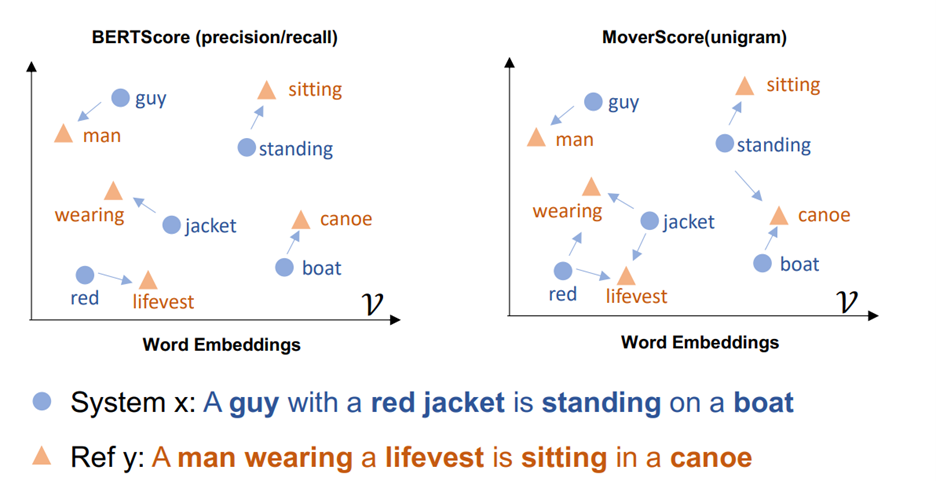
An illustration of MoverScore and BERTScore from https://arxiv.org/pdf/1909.02622
This method has some limitations and bias such as they can be bias toward models that are more similar to its own underlying model. Another problem is that they don’t take into account the syntactic structure of the sentence so when the sentences are different in structure but they have the same meaning then they may give incorrect evaluation.
NLP model method
Another method is model-based score. It uses the NLP models such as NLI using Natural Language Inference model or BLEURT use pre-trained model like BERT to evaluate the response. However, although they are more accurate but the reliability is not high due to probability nature. Besides this, this approach depends on the amount of the data used to train the model while the LLM response are complex.
Below is an example to use NLI to calculate entailment score based on a given premise.
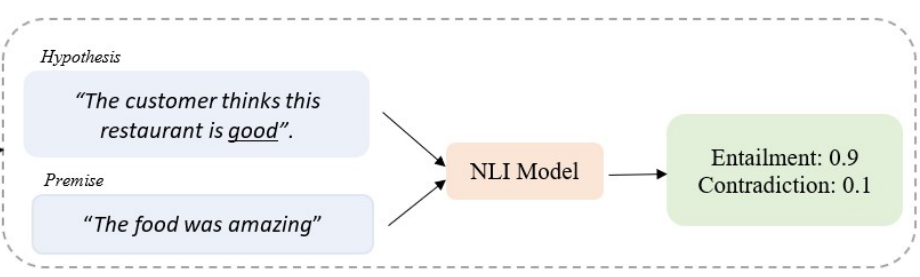
Source: https://addi.ehu.es/bitstream/handle/10810/61832/TFM_David_Romero.pdf?sequence=2&isAllowed=y
LLM-Assisted Evals method
Researchers are using LLMs such as GPT 4 to evaluate the output of similar models or itself. It can be understood as “evaluate the evaluated” or self-assessment. It is based on the idea that to judge is easier than to create. Some of the most popular are GPTScore, G-Evals or SelfCheckGPT.
LLM-Assisted Evals perform better than other methods and high correlate with human judgments, however, it is still unreliable:
- It has position bias: it prefers response in a particular position which means that they prefer the first result when comparing the two outcomes https://arxiv.org/pdf/2306.05685
- Prefer integers when assigning score to candidate response
- Probability issue in nature when it assigns different scores to same output when invoke separately
- They can prefer their own-output to human-written text as in this research https://arxiv.org/abs/2305.17926.
- Another pitfall is they tend to prefer longer response
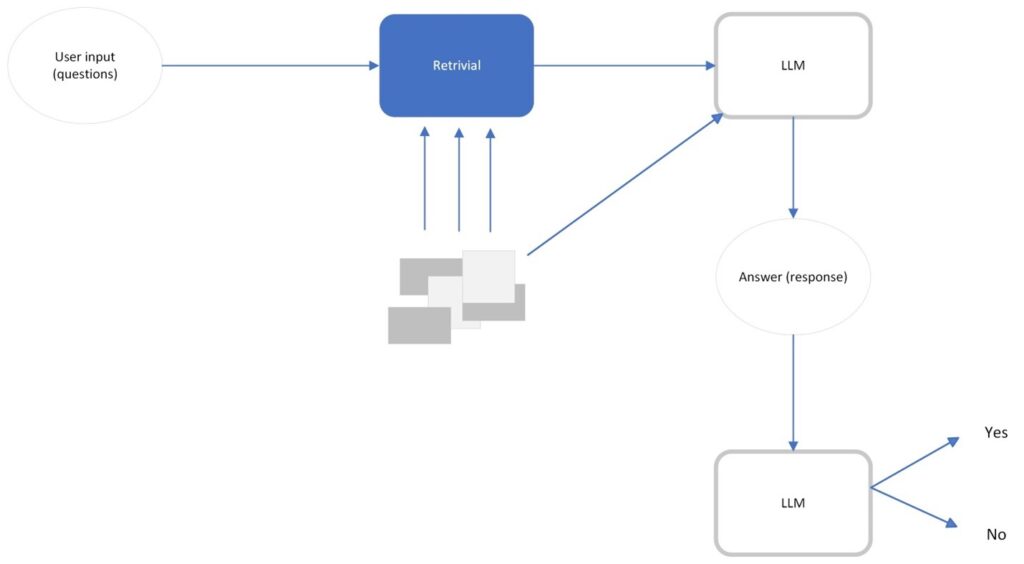
An illustration of using LLM to insist evaluate for RAG.
Depending on the use case and architecture of your LLM application, you can choose suitable evaluation approach and metrics. For example, if you are building a RAG-based chatbot to answer questions related to your company policies, guidelines using OpenAI GPT4 model, then you need to evaluate the chatbot by using many RAG metrics: faithfulness, answer relevant, context precision, … while if you fine-tunning a model then the metrics could be hallucination, toxicity, bias …
There are a lot of libraries equipped with ready-to-use evaluation metrics such as Langchain, RAGAS, DeepEval,.… However, each tool may have different approach on how to calculate for each metrics so we need to understand clearly its methodology to choose the suitable one for your project.
Evaluate the evaluation
Once we have the evaluation strategy, we have to evaluate the evaluation method by using the test set contains human annotation score then compare that score with the score for the test set using your approach. If the correlation is good enough then this can be used.
And besides, we need human evaluation into the loop to evaluate the auto evaluation, such as to use their feedback for building better evaluation dataset or chances to improve models, prompt…
So, the choice is yours
Evaluating LLM based app is still an open research area and how difficult, challenging it is on building accuracy, reliable metric.
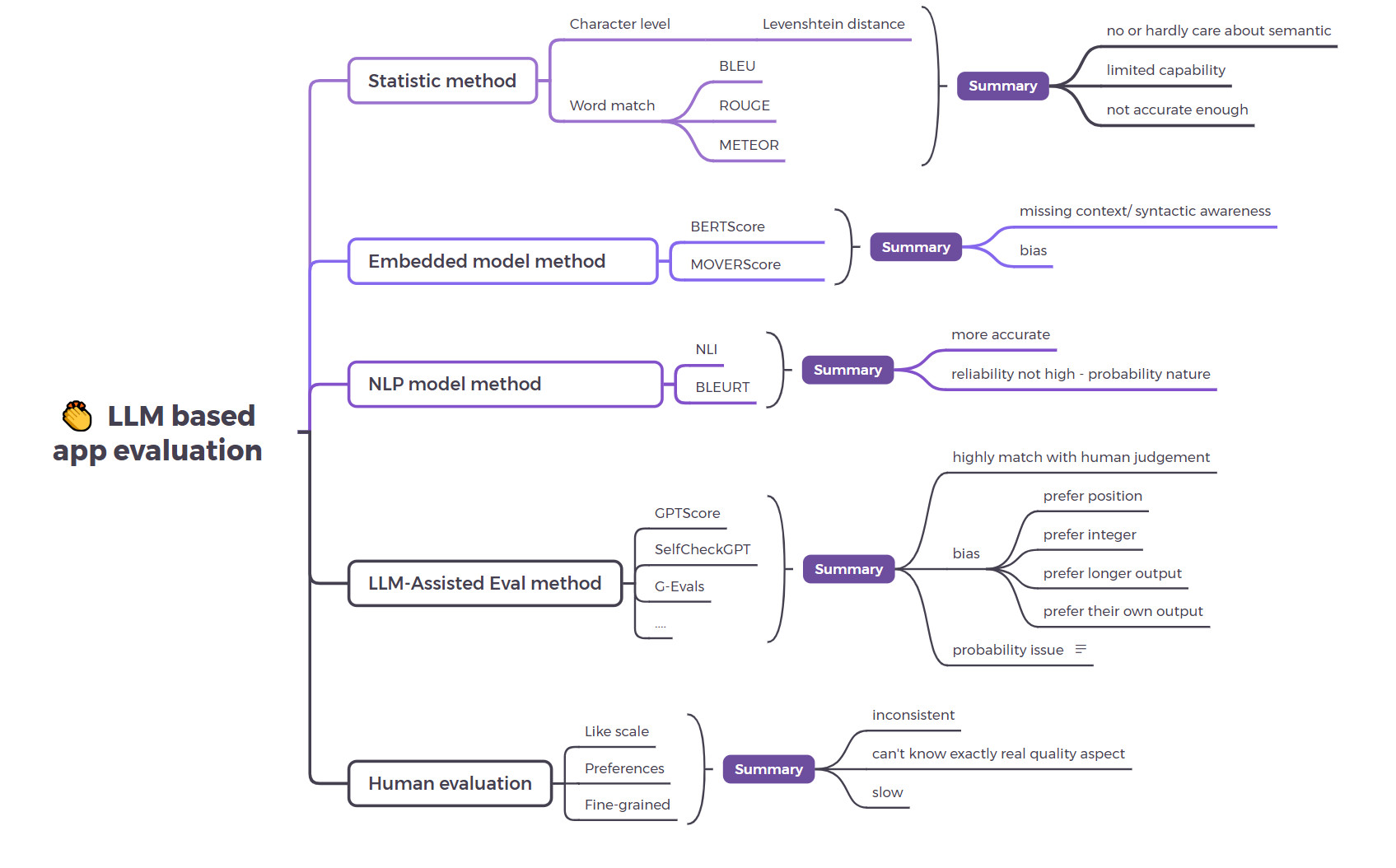
All the current method and advantages/ disadvantages are illustrated in the below image, and you have to choose which one is suitable for your application based on the use case and architecture.
Reference:
Many article, post, video, research on the internet.