



1. Introduction
Automated testing is essential for building reliable and high-quality software applications in today’s fast-paced software development. Selenium automates web application testing, while Cucumber lets testers write tests in plain, easy-to-understand language using the behaviour-driven development (BDD) approach. Managing test data for these tools can often present significant challenges hence, AI-based test data management solves this problem by automatically creating and organizing test data, making automated testing more efficient and effective.
2. Challenges of Traditional Test Data Management
Traditional methods of managing test data require manual creation, maintenance, and updates, leading to inefficiencies. Some of the main challenges include:
- Data Inconsistency: When managed manually, test data can become inconsistent, which may result in unreliable outcomes and frequent test failures.
- Scalability Problems: As applications grow more complex, handling larger test data sets becomes increasingly challenging.
- Time-Consuming: The manual process of creating and updating test data is time-intensive and can slow down the entire testing process.
- Lack of Realistic Data: Manually generated data often lacks authenticity, making it less representative of real-world scenarios and reducing the overall effectiveness of the tests.
3. Key Elements of AI-Powered Test Data Management
- Data Generation: AI generates test data by analysing the app’s domain, user behaviour, and data patterns.
- Data Masking and Anonymization: It can hide or anonymize sensitive data, making it safe to use without exposing private information.
- Data Optimization: AI removes duplicate data, focuses on critical test cases, and eliminates unnecessary information for better efficiency.
- Data Validation and Integrity: It ensures that test data is valid, correctly formatted, and aligned with system rules, leading to reliable test results.
4. Implementing AI-Based Test Data Management in Selenium and Cucumber
To demonstrate a generic implementation here’s a sample code structure that can be adapted to work with various AI tools for data generation and management.
4.1 Maven Dependencies
Add the necessary dependencies to your pom.xml file, including the AI data generation and management libraries:
- spark-core_2.13: This is the main component of Apache Spark and is used for large-scale data processing and transformation.
- spark-sql_2.13: It supports SQL queries in Apache Spark, making it easier to work with structured data.
- weka-stable: A machine learning library that provides tools for data preprocessing, as well as for classification, clustering, and regression tasks.
4.2 AI Data Generation using Weka Library
In this example, we’ll use Weka Library for Data Generation and Apache Spark for Data Management. Create classes for data generation and management using the respective AI libraries:
Weka Library: is an open-source library. It serves as a comprehensive data mining platform that incorporates a variety of machine learning and deep learning algorithms.
- Create a new DenseInstance object
DenseInstance: Represents a single data point where the attribute values are stored in a dense array.
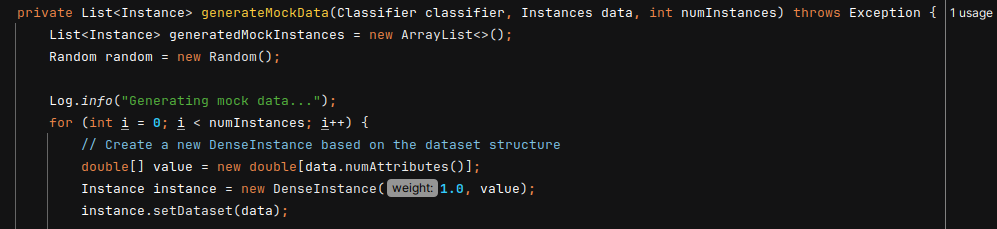
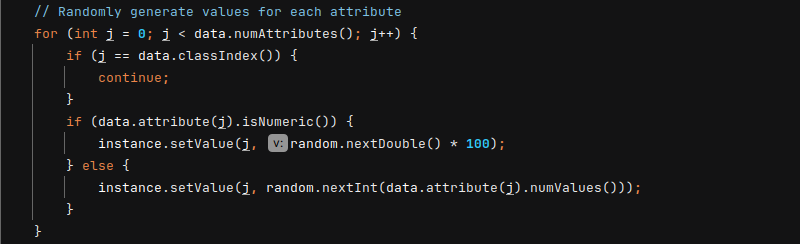
- Generate Random Values for each attribute
a) If the attribute is numeric, a random value is generated between0and100.
b) If the attribute is nominal (categorical), a random index is selected from the available nominal values.
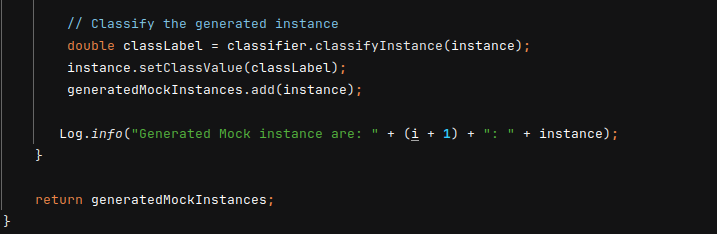
- Classify the generated Random Instances
Create a method to predict the class label (or target value) for theinstancebased on the trained classifier.
4.3 AI Data Management using Apache Spark
Now, to manage the generated data we will use Apache Spark. The code manages data through two approaches: Data Aggregation and Data Transformation.
Apache Spark: is a free and open-source platform for distributed computing, built to handle and process large-scale datasets efficiently. It provides robust tools and libraries, such as MLlib, for building, training, and deploying machine learning models and performing real-time data processing.
- Creating a Spark Session: A
SparkSessionis initialized, which acts as the entry point to interact with Spark functionalities.

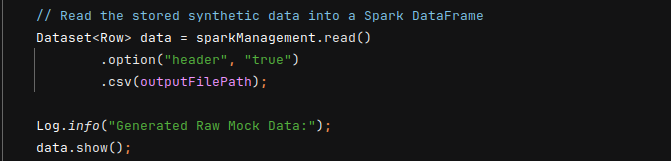
- Load the previously saved data into a Spark DataFrame: which provides a structured representation of the CSV data for further operations.
Spark DataFrame: represents structured data and allows transformations/queries.
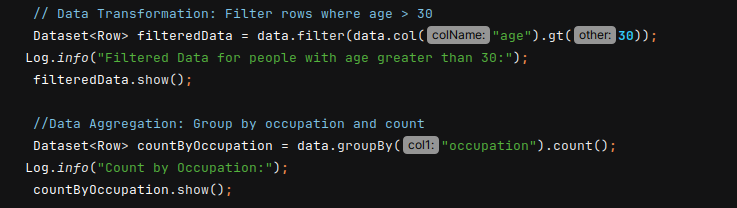
- Performing Data Transformation and Data Aggregation:
a) Data Transformation: focuses on extracting relevant data subsets for analysis.
b) Data Aggregation: summarizes or combines data based on specific criteria to understand data patterns (e.g., how many people belong to each occupation).
- Managed data output visible on the terminal
Filtered Data (age > 30):
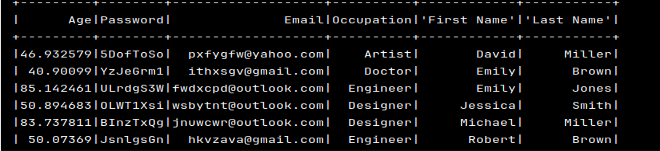
Count by Occupation:

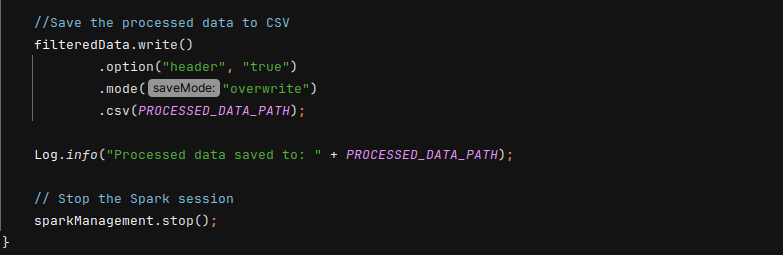
- Save the Processed Data and Stop the Spark Session: to ensure proper cleanup after data processing is complete.
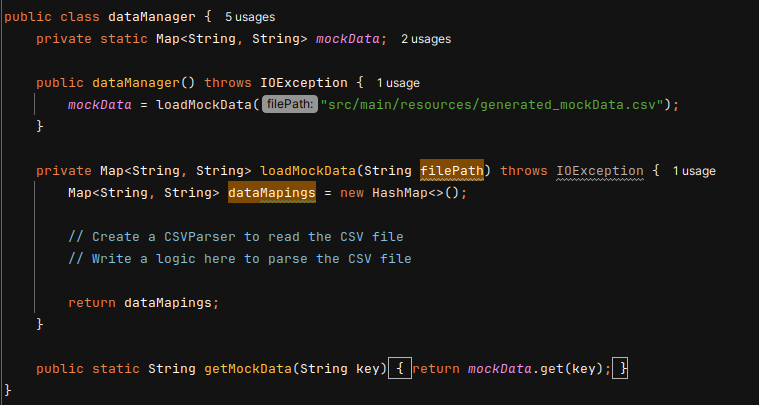
4.4 Using Processed Data
Create a DataManager.java class to parse the CSV file and get the mock data allowing easy reading and usage of processed data in our tests.
5. Future of AI in Test Data Management
- Predictive Test Data Generation: AI predicts what test data will be most valuable for upcoming changes.
- AI-Powered Data Masking and Synthesis: Advanced techniques for creating realistic yet fully anonymized data that complies with data privacy regulations.
- Intelligent Data Relationships: AI models that will help to understand and maintain complex relationships between different data entities.
- Natural Language Test Data Requests: Generating test data from natural language descriptions of test scenarios.
6. Conclusion
AI-based test data management greatly improves the efficiency and effectiveness of testing in Selenium and Cucumber. By automating the process of generating and managing test data, teams can spend more time on important testing tasks instead of routine data handling. As the industry moves toward AI-driven solutions, adopting these technologies will be key to staying competitive in software development and testing.