


Kafka Connect is an open source framework and we can say it is another layer on core Apache Kafka, to support large scale streaming data:
- import from any external system (called Source) like mysql,hdfs,etc to Kafka broker cluster
- export from Kafka cluster to any external system (called Sink) like hdfs,s3,etc
For the above 2 mentioned responsibilities, KC works in 2 modes:
Source Connector : imports data from a Source to Kafka
Sink Connector : exports data from Kafka to a Sink
For using Kafka Connect for a specific data source/sink, a corresponding source/sink connector needs to be implemented by overriding abstraction classes provided by KC framework
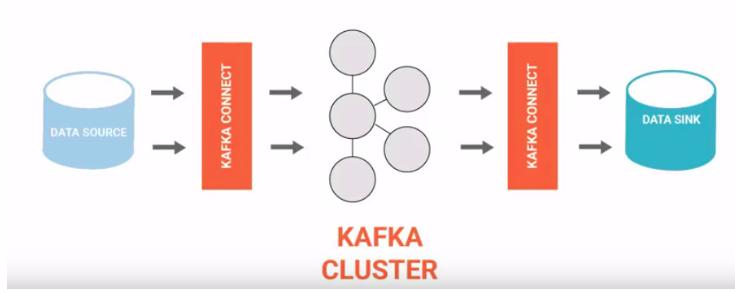
KC just makes it explicit that it either reads from Kafka Topic (Source) or write to a Kafka Topic (Sink) and it uses Kafka message broker underneath for data buffering. By doing that, it brings on table all those features like reliable buffering, scalability, fault tolerance, simple parallelism, auto recovery, rebalancing, etc for which Kafka is popular.
Internally, what happens is, at regular intervals, data is polled by source task from data source and written to kafka and then offsets are committed. Similarly on the sink side, data is pushed at regular intervals by Sink tasks from Kafka to destination system and offsets are committed
WHY Kafka Connect:
KC brings a very important Dev principle in play in ETL pipeline development where on runtime we any datasource need to be changes kafka connect help here.
HOW TO Use Kafka Connect
KC exposes REST api to create, modify and destroy connectors.
Why not Kafka Connect:
Like any other framework, KC is not suitable for all use cases . First of all, it is Kafka centric, so if your ETL pipeline does not involve Kafka, you can not use KC. Second, the KC framework is jvm specific and only supports Java/scala languages.
: