



Introduction
Automated testing is key to ensuring software quality, but flaky tests in Selenium and Cucumber can create unreliable results. In this blog, we’ll explore how machine learning can help predict and reduce test flakiness, improving test stability. By the end, you’ll know how to make your tests more reliable.
Introduction to Machine Learning Models
Overview of Machine Learning
Machine learning, a branch of AI, trains algorithms to detect patterns and make data-driven predictions, offering solutions where traditional programming falls short.
Types of Machine Learning Models
- Supervised Learning: These models are trained on labeled data, where the outcome is known. Examples include regression and classification models.
- Unsupervised Learning: Unsupervised learning is a type of machine learning where models find patterns and structures in data without labels. Clustering algorithms are a common example.
- Reinforcement Learning: These models learn by interacting with an environment and receiving rewards or penalties based on their actions.
Using Machine Learning to Predict Test Flakiness
Data Collection and Preparation
The first step in predicting test flakiness is to gather useful data. This includes test execution logs, environmental parameters, code changes, and any other factors that might influence test outcomes. (This can be achieved by storing the failed Test cases into a separate file like failedTests.txt).
Feature Selection
Key features that may influence test flakiness include:
- Execution Time
- Environment Variables
- Code Changes
- External Dependencies
Model Selection
Choosing the right machine learning model is crucial. Commonly used models for predicting flakiness include:
- Decision Trees: These are easy-to-understand models that can work with both numbers and categories.
- Random Forests: This method uses many decision trees together to make more accurate and reliable predictions.
- Neural Networks: More complex models that can capture intricate patterns in data but require more computational resources.
Practical Implementation of Machine Learning
Tools and Frameworks
Several tools and frameworks can facilitate the implementation of machine learning models for predicting test flakiness.
Popular choices include:
- TensorFlow: TensorFlow is an advanced, open-source machine learning platform developed by Google, enabling developers to create cutting-edge models with ease.
- Weka: It is a Java-based machine learning tool. It helps with tasks like sorting data, making predictions, and finding patterns. It’s great for Java developers and can be added to Java programs.
- scikit-learn: This is a Python library that makes data analysis easy. It works well with other Python tools like NumPy and pandas, and it’s known for being simple to use.
Case Study or Example
Consider a scenario where a software team uses Selenium for automated browser testing. By collecting data from their CI system, such as test execution logs and environmental variables, they train a random forest model to predict flaky tests. Over time, they observe a significant reduction in false positives and improved stability in their test suite, allowing them to deploy code with greater confidence.
Workflow / Implementation Steps
Data Flow Diagram

Data Collection
We will first store the Flaky data from Test execution logs into the CSV file in a list of TestResult objects. Each TestResult object should contains relevant data such as test name, execution name, result(pass/fail), and environment details.
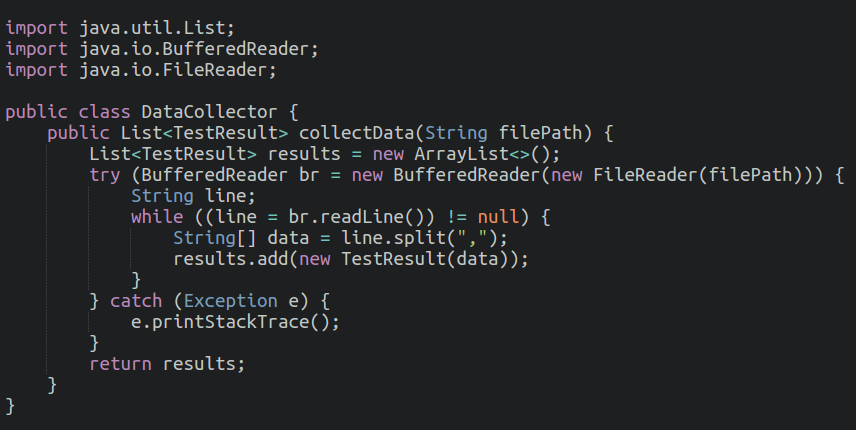
Data Preprocessing
After data collection, we will now organize the data to make it suitable for machine learning. This process cleans up the data by removing duplicates and converts text-based information (like categories) into numbers that make the machine learning model to understand the data.
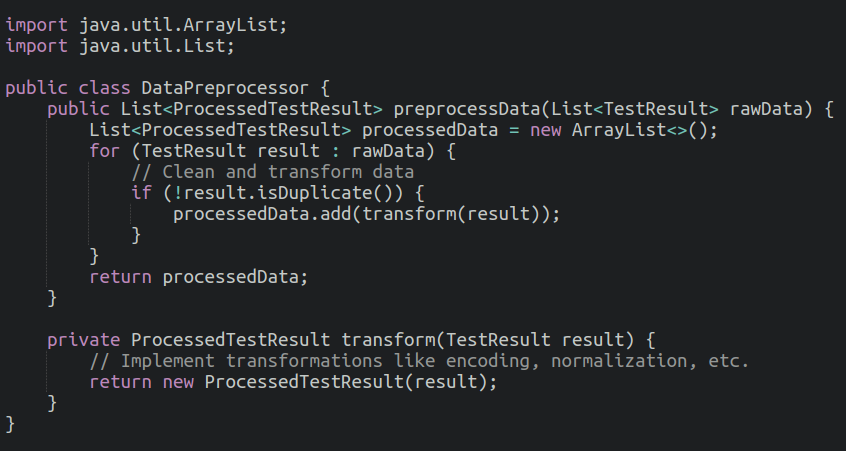
Feature Selection
This step involves using a library like Weka to perform feature selection. The CfsSubsetEval and BestFirst classes are used to evaluate and select the most relevant features.
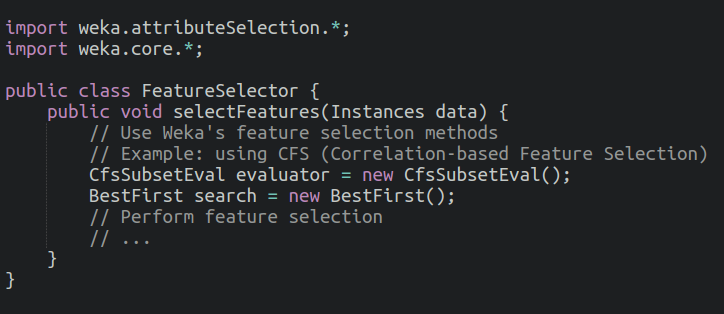
Model Selection
- We then have to choose an appropriate machine learning algorithm according to the need (e.g., Random Forest, Support Vector Machines, or Neural Networks). In our case we have chosen the Random Forest algorithm.
Let’s look how Random Forest algorithm make predictions:
- Random Forest combines multiple decision trees to predict test flakiness.
- Each tree analyzes different features like execution time, environment, and dependencies.
- Trees are trained on unique data subsets to ensure diverse predictions.
- Random Forest Algorithm performs final predictions internally via majority voting, ensuring accuracy and reliability.
- It handles imbalanced datasets effectively and identifies key factors causing flakiness.
Model Training
This code snippet demonstrates how to train a Random Forest model using Weka. The trainModel method builds the classifier based on the training data.
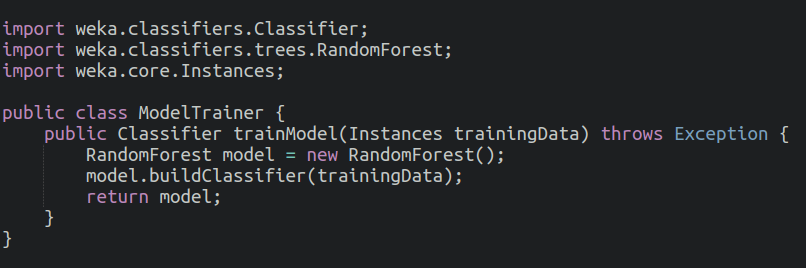
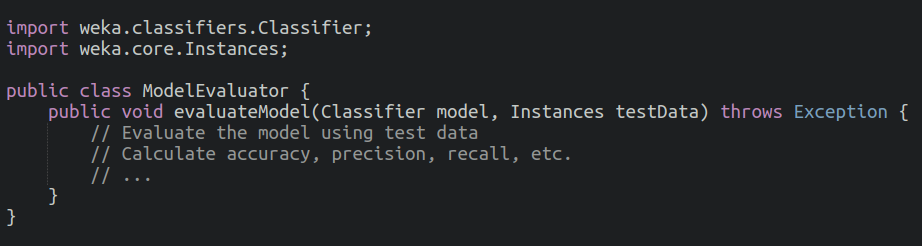
Model Evaluation
After Model training, we will then evaluate our trained model using the test dataset and then calculate the performance metrics to access how well the model predicts test flakiness.
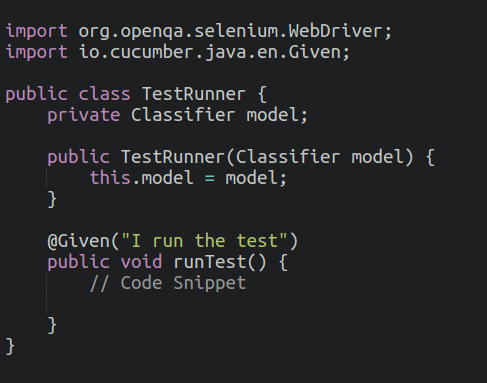
Integration of Machine Learning Model with Selenium & Cucumber
We then integrate the machine learning model into the Cucumber test execution process.
Continuous Monitoring and Improvement
- Continuously collect new test execution data and retrain the model periodically to improve its accuracy and adapt to changes in the test environment.
Conclusion
Machine learning offers a powerful toolset for predicting and addressing test flakiness, thereby enhancing the stability of Selenium and Cucumber tests. By leveraging these techniques, development teams can improve the reliability of their automated test suites, streamline their CI/CD pipelines, and ultimately deliver higher-quality software.