


Azure Cosmos DB is a globally distributed, multi-model database service offered by Microsoft Azure. With its ability to replicate data across multiple regions, Cosmos DB provides a seamless experience for developers building highly scalable, low-latency, globally available applications. One of the key reasons why Cosmos DB is a preferred choice for distributed applications is its flexible consistency models, allowing developers to balance between performance, availability, and consistency based on application needs.
In this blog, we’ll dive into the core features of Cosmos DB’s global data distribution and explain how its consistency levels work, providing insight into how developers can leverage these capabilities to build robust cloud applications.
What is Azure Cosmos DB?
Azure Cosmos DB is designed for global scale, providing a high degree of elasticity, performance, and availability. It supports multiple data models, such as document, graph, key-value, and column-family, using various APIs like SQL, MongoDB, Cassandra, Gremlin, and Table. This flexibility allows developers to work with Cosmos DB across different scenarios, from traditional relational models to NoSQL architectures.
One of the standout features of Cosmos DB is its global distribution capabilities. With built-in features for global replication, developers can deploy their applications in any number of Azure regions worldwide. This capability ensures that data is replicated close to end-users, reducing latency and improving response times. For applications requiring consistent performance and availability, Cosmos DB becomes an ideal solution, offering single-digit millisecond reads and writes.
Understanding Global Data Distribution in Cosmos DB
The Need for Global Distribution
Global data distribution is crucial for applications that require real-time, low-latency access to data across different geographical locations. By replicating data across multiple regions, developers can ensure that users from different parts of the world have fast access to application data, improving the user experience. For example, an e-commerce application with a global customer base can benefit from distributing data globally, allowing users from Europe, North America, and Asia to access data with minimal delays.
How Cosmos DB Implements Global Distribution
Azure Cosmos DB uses a system of multiple-region reads and writes. This means that data is automatically replicated to all selected regions. Each write is propagated across all regions, ensuring that a copy of the data is available in every region where the application is deployed. This replication model supports both multi-region write and single-region write configurations, giving developers the flexibility to optimize for their specific use case.
Cosmos DB also offers data partitioning mechanisms to manage large datasets. It divides data into smaller, manageable partitions, each with its own replica set. These partitions are automatically distributed across regions based on the traffic, ensuring that data is always available with high performance.
Region Failover and Disaster Recovery
In case of regional failures, Cosmos DB provides automatic failover capabilities. This feature ensures that if one region experiences downtime or network issues, the application can seamlessly switch to a different region, maintaining high availability. Developers can also configure manual failover to control how and when the failover happens. This mechanism is particularly beneficial for mission-critical applications where downtime can lead to significant business losses.
What Are Consistency Levels in Cosmos DB?
The CAP Theorem and Cosmos DB’s Approach
The CAP theorem states that a distributed system can offer only two out of the three following guarantees: Consistency, Availability, and Partition Tolerance. Cosmos DB is designed to address the needs of distributed applications by offering tunable consistency levels. This allows developers to find the right balance between consistency and availability, depending on the application’s requirements.
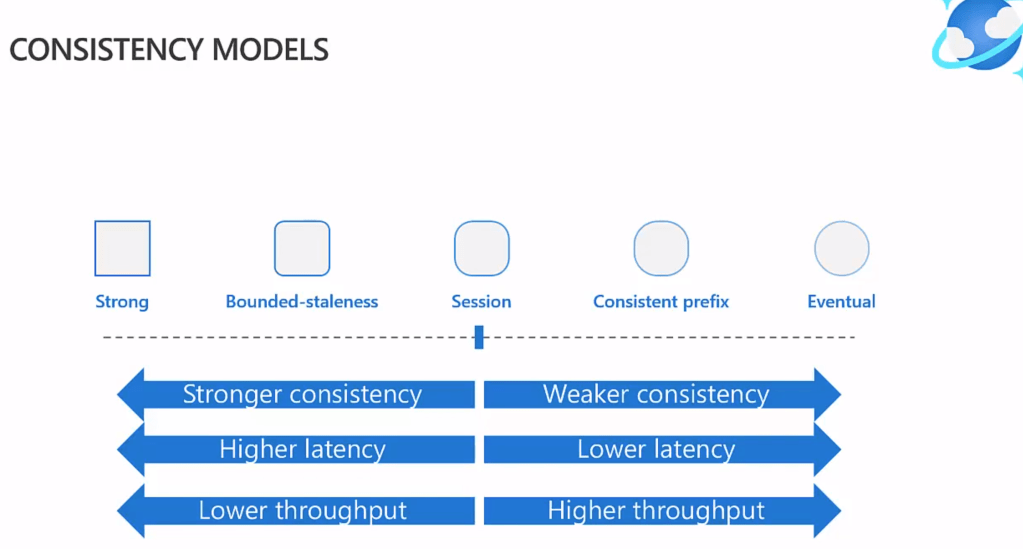
Cosmos DB provides five distinct consistency levels, ranging from strong consistency to eventual consistency. This flexibility enables developers to select the right consistency level for their application, whether it requires strong guarantees or can afford more relaxed consistency in exchange for better performance.
Five Consistency Levels of Cosmos DB
Cosmos DB offers five consistency levels:
- Strong Consistency
Strong consistency ensures that every read receives the most recent write. This is the most stringent consistency level and guarantees absolute consistency, where all clients see the same version of data. However, this comes at the cost of higher latency and reduced availability in the event of partitioning. Strong consistency is typically used in scenarios like banking or financial applications where correctness is crucial. - Bounded Staleness
Bounded staleness guarantees that reads are lagged by a predefined amount of time or number of operations. This consistency model allows developers to define the staleness tolerance for their application, making it suitable for scenarios where slightly stale data is acceptable, such as collaborative editing applications. - Session Consistency
Session consistency is ideal for user-specific workloads. It ensures that within a given session, a user always sees their own writes. This is particularly useful for applications like social media platforms where users need a consistent view of their own data, but other users can tolerate eventual consistency. - Consistent Prefix
This level guarantees that reads never return out-of-order writes, though they may be stale. The consistent prefix model is useful for applications where the order of operations matters, such as logging or event tracking systems, but strict real-time consistency is not required. - Eventual Consistency
Eventual consistency provides the lowest latency and highest availability. With this model, the system guarantees that all replicas will eventually converge to the same value, though the data may not be immediately consistent across all regions. This is a good choice for scenarios where high throughput is essential, and the application can tolerate stale data, such as in social media feeds or content delivery networks.
How to Choose the Right Consistency Level
Balancing Performance and Consistency
Choosing the right consistency level for your application involves understanding the trade-off between consistency, availability, and performance. Stronger consistency levels, such as strong and bounded staleness, ensure that data is always consistent but come with a cost of higher latency and lower availability. On the other hand, weaker consistency models like eventual consistency provide better performance but at the expense of immediate consistency.
For instance, if you’re building a global e-commerce platform where users frequently interact with data (e.g., browsing product catalogs), session or eventual consistency might be more appropriate to ensure low-latency operations. However, for payment processing, where accuracy is critical, you might opt for strong or bounded staleness consistency.
Case Studies of Consistency Levels
Let’s explore some practical use cases for each consistency level:
- Strong Consistency: Financial services, inventory management systems.
- Bounded Staleness: Collaborative document editing, distributed task scheduling.
- Session Consistency: User-specific sessions like social media platforms.
- Consistent Prefix: Event logging, IoT device data streams.
- Eventual Consistency: Social media news feeds, product catalogs.
Each consistency level serves different use cases, and understanding the application’s requirements is key to making the right choice.
Adjusting Consistency Levels Dynamically
One of the unique features of Cosmos DB is its ability to allow dynamic adjustments to consistency levels. Developers can switch between consistency levels based on the evolving needs of their application. For example, during periods of heavy traffic, you might switch to eventual consistency to reduce latency, and during critical operations, you could switch to strong or bounded staleness to ensure the accuracy of data. This flexibility ensures that you can balance performance and consistency across the lifecycle of your application.
Conclusion
Azure Cosmos DB’s global data distribution and flexible consistency levels make it a powerful solution for building high-performance, globally distributed applications. By leveraging its multiple-region replication, partitioning, and various consistency models, developers can build applications that are responsive, available, and capable of handling vast amounts of data across the globe. Whether you’re building a social media platform, a financial system, or an e-commerce site, Cosmos DB provides the tools to ensure data consistency, performance, and scalability tailored to your specific needs.