


In today’s data-driven world, organizations generate vast amounts of data from multiple sources. Managing and analyzing this data can be challenging, especially when it’s distributed across various platforms. This is where virtual data warehousing (VDW) comes into play. Snowflake, a modern cloud-based data warehousing solution, provides robust capabilities for implementing virtual data warehousing. This blog will guide you through the concept of VDW, its benefits, and how Snowflake can help you leverage it effectively.
What is Virtual Data Warehousing (VDW)?
Virtual Data Warehousing is a data management architecture that allows users to access and analyze data without moving it from its original source. Unlike traditional data warehouses, which require data to be physically stored and processed in one place, a VDW enables organizations to access real-time data from multiple sources seamlessly. This approach helps in reducing data silos and allows businesses to make informed decisions based on the latest available data.
Key Characteristics of VDW:
- Data Virtualization: Data remains at its source; only the required data is queried and processed.
- Real-time Data Access: Ability to access the most current data for up-to-date analysis.
- Simplified Data Management: Eliminates the need for extensive ETL (Extract, Transform, Load) processes.
- Scalability: Easy to scale as data volumes grow.
Why Choose Snowflake for Virtual Data Warehousing?
Snowflake is a cloud-native data platform that offers unique features making it an ideal choice for VDW. Here’s why:
- Multi-Cluster Shared Data Architecture:
Snowflake’s architecture separates storage and compute, allowing organizations to scale independently. This feature enables real-time querying across multiple data sources without affecting performance. - Data Integration and Data Sharing:
Snowflake simplifies data integration from various sources such as on-premise databases, cloud storage, and SaaS applications. With its data sharing capabilities, Snowflake allows secure and instant access to shared data without the need to copy or move it. - Ease of Use:
The platform is user-friendly and supports SQL, which makes it easy for data analysts and engineers to query and analyze data. - Security and Compliance:
Snowflake ensures high-level security and compliance, including data encryption, multi-factor authentication, and compliance with standards like HIPAA, GDPR, and SOC.
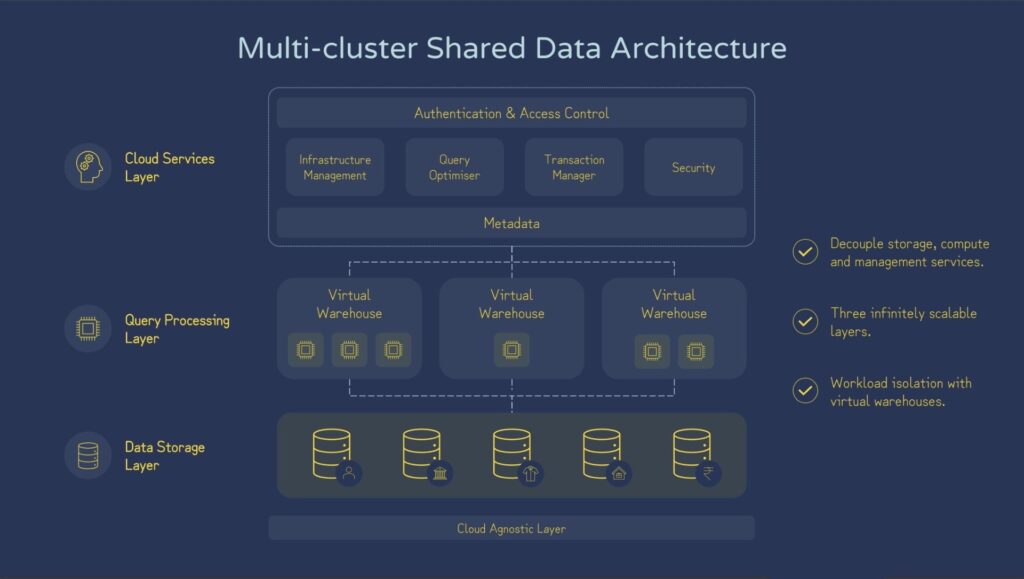
Snowflake Architecture and Virtual Data Warehousing
Snowflake’s architecture is built on three layers: Storage, Compute, and Services.
- Storage Layer:
Snowflake stores all your data in a compressed, columnar format. It can manage both structured and semi-structured data (e.g., JSON, Parquet). This layer enables organizations to access data across multiple regions and availability zones. - Compute Layer:
Snowflake uses virtual warehouses, which are clusters of compute resources that can run independently. Users can create multiple virtual warehouses for different workloads, ensuring that one workload doesn’t interfere with another. - Services Layer:
This layer handles various services like authentication, query optimization, metadata management, and more. It allows Snowflake to automate many tasks, such as scaling, managing workloads, and optimizing performance.
Here’s a simplified diagram of the Snowflake architecture:
Setting Up a Virtual Data Warehouse in Snowflake
Let’s dive into how you can set up a VDW using Snowflake. We will walk through connecting data, querying data, and scaling your Snowflake environment.
Step 1: Setting Up a Virtual Warehouse
To create a virtual warehouse, you can use the following SQL command:
CREATE WAREHOUSE my_virtual_warehouse
WITH
WAREHOUSE_SIZE = 'X-SMALL'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE
INITIALLY_SUSPENDED = TRUE;Explanation:
WAREHOUSE_SIZE: Specifies the size of the warehouse (e.g., X-SMALL, SMALL, MEDIUM, etc.)AUTO_SUSPEND: Suspends the warehouse if there are no queries running after 60 seconds.AUTO_RESUME: Automatically resumes the warehouse when a query is executed.
Step 2: Integrating Data from Multiple Sources
Snowflake allows you to integrate data using several connectors. For example, you can load data from Amazon S3 or Azure Blob Storage using the following SQL command:
CREATE OR REPLACE STAGE my_stage
URL = 's3://my-bucket/data/'
CREDENTIALS = (AWS_KEY_ID = 'your_access_key' AWS_SECRET_KEY = 'your_secret_key');
COPY INTO my_table
FROM @my_stage/file.csv
FILE_FORMAT = (TYPE = 'CSV' FIELD_OPTIONALLY_ENCLOSED_BY = '"');Step 3: Querying Data Using SQL
Once your data is loaded, you can use standard SQL to query it. For example, you can join data from different sources seamlessly:
SELECT c.customer_name, o.order_date, p.product_name
FROM customers c
JOIN orders o ON c.customer_id = o.customer_id
JOIN products p ON o.product_id = p.product_id;This query enables you to extract insights by joining tables from different databases, demonstrating the VDW concept where data doesn’t need to be physically moved.
Step 4: Scaling the Warehouse
Scaling is one of Snowflake’s strong suits. You can scale up or down depending on your workload:
ALTER WAREHOUSE my_virtual_warehouse
SET WAREHOUSE_SIZE = 'MEDIUM';Scaling can be performed without downtime, and Snowflake also supports multi-cluster warehouses for automatically handling high query loads.
Practical Use Case: Real-Time Data Analysis
Imagine a retail company that wants to analyze sales data from multiple stores across different regions. Each store stores its sales data in a different database (some on-premises and others in the cloud). Traditionally, the company would need to perform extensive ETL operations to move all this data into a central data warehouse.
With Snowflake’s VDW, they can set up a data pipeline that connects to each store’s database. This way, analysts can query data in real-time without worrying about data movement, which reduces latency and improves decision-making speed.
Benefits of Virtual Data Warehousing with Snowflake
- Cost-Effective:
Since you don’t need to store redundant data copies, VDW can save significant storage costs. Snowflake also allows you to pay only for the compute resources you use. - Flexibility:
Organizations can quickly adapt to new data sources or changes in the existing ones. Snowflake’s ability to handle structured and semi-structured data makes it highly versatile. - Data Security:
Snowflake offers robust data encryption and access controls, ensuring that data is secure while in transit and at rest. Moreover, its data sharing capabilities allow businesses to securely share data with partners and clients without creating additional data copies. - Performance:
With Snowflake, data can be queried and analyzed in real-time, leading to faster insights. Its architecture allows for scaling on-demand, ensuring high performance even with large datasets.
Conclusion
Virtual Data Warehousing is transforming how businesses handle and analyze data by enabling real-time access to distributed data without the need for heavy data movement. Snowflake, with its scalable, secure, and easy-to-use platform, offers a robust solution for implementing VDW. By using Snowflake’s features like data integration, scaling, and secure data sharing, organizations can streamline their data workflows, reduce costs, and drive faster decision-making.
With the knowledge shared in this blog, you are well-equipped to explore Snowflake for your VDW needs. Whether you’re looking to streamline data integration, scale analytics workloads, or ensure secure data sharing, Snowflake provides the tools and flexibility to make it happen seamlessly.