



AI Output Testing: A Manual Tester’s Framework for Assuring Quality, Safety, and Trust
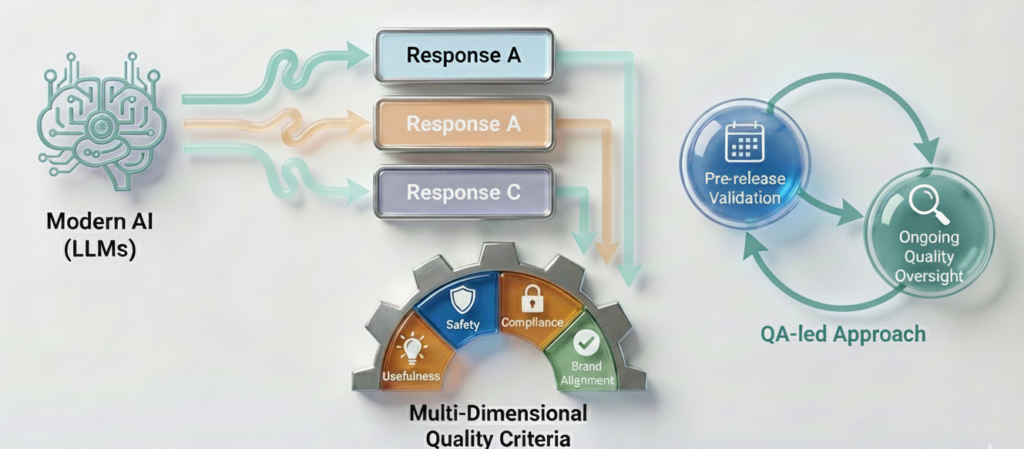
Modern AI, especially systems built on large language models (LLMs) is nondeterministic: identical prompts can yield different, yet acceptable, responses. In this context, quality cannot be verified by exact string matching alone. It must be judged against explicit, multi-dimensional criteria that reflect usefulness, safety, compliance, and brand alignment.
This article presents a practical, QA-led framework for AI Output Testing and situates it within the broader discipline of AI Testing. The aim is to provide a repeatable approach teams can use for pre-release validation and ongoing quality oversight.
1) Positioning: Where AI Output Testing Fits Within AI Testing
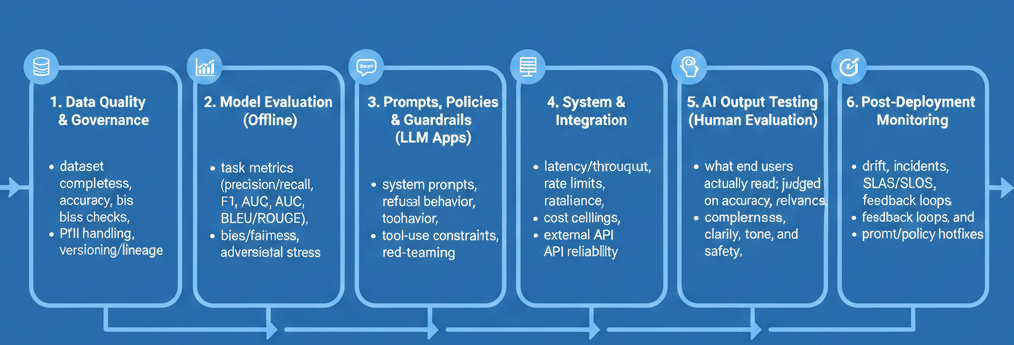
Before defining how to evaluate responses, it helps to see the full landscape. AI Testing spans the entire lifecycle:
- Data Quality & Governance: dataset completeness, accuracy, bias checks, PII handling, versioning/lineage.
- Model Evaluation (Offline): task metrics (precision/recall, F1, AUC, BLEU/ROUGE), robustness, bias/fairness, adversarial stress.
- Prompts, Policies & Guardrails (LLM Apps): system prompts, refusal behavior, tool-use constraints, red-teaming.
- System & Integration: latency/throughput, rate limits, resilience, cost ceilings, external API reliability.
- AI Output Testing (Human Evaluation): what end users actually read; judged on accuracy, relevance, completeness, clarity, tone, and safety.
- Post-Deployment Monitoring: drift, incidents, SLAs/SLOs, feedback loops, and prompt/policy hotfixes.
With the stack in view, the next question is ownership: who should lead the evaluation of the words users actually see?
2) Why AI Output Testing Belongs with Manual Testers
Output quality relies on structured human judgment, domain awareness, and clear communication—core strengths of experienced QA.
- Human judgment: Evaluating accuracy, completeness, clarity, tone, and safety is inherently qualitative.
- Domain & policy literacy: QA collaborates closely with product, legal, and compliance to catch risky claims and off-brand messaging.
- Scenario thinking: Testers design realistic, multi-turn conversations and ambiguous prompts—precisely where AI often fails.
- Golden dataset stewardship: Curating/versioning high-value prompts (core, ambiguous, adversarial) is test management, not model training.
- Actionable reporting: QA turns qualitative findings into concrete prompt/policy/UX changes with severity and reproducible evidence.
Recommended ownership model:
- Manual QA (lead): Define rubric and acceptance criteria; run evaluations; maintain golden/red-team sets; recommend release readiness.
- Domain/Compliance (review): Validate correctness for regulated topics and approve policy language.
- Prompt/ML Engineering (implement): Apply prompt, tool, and guardrail changes; run offline evals; weigh cost/performance trade-offs.
- Product/CX (govern): Set tone/persona, escalation paths, and user-experience guidelines.
With ownership established, we can now define precisely what QA evaluates.
3) Definition and Scope of AI Output Testing
AI Output Testing is the systematic human evaluation of model-generated content against explicit standards:
- Accuracy (factual correctness; absence of hallucination)
- Relevance (directness to user intent and context)
- Completeness (critical details, caveats, next steps)
- Clarity & Structure (readability; scannable formatting)
- Tone & Persona (brand voice; situational appropriateness)
- Safety & Compliance (policy adherence; risk controls)
To apply these consistently across reviewers and releases, teams benefit from a straightforward scoring approach.
4) Challenges Unique to Evaluating AI Outputs
A few realities shape the way we test:
- Non-determinism: Acceptable variation across runs.
- Open-endedness: Multiple valid answers; we assess quality, not fixed phrasing.
- Implicit requirements: “Professional yet friendly” must be made testable.
- Elevated risk: Bad answers create legal/compliance or reputational exposure.
These constraints make a shared rubric essential.
5) A Practical Quality Rubric (1–5 Scale)

Score each response (1=unacceptable, 3=acceptable, 5=excellent) with brief justification notes.
| Dimension | Guiding Questions |
|---|---|
| Accuracy | Correct facts/calculations? No hallucinations? |
| Relevance | Directly addresses request and context? |
| Completeness | Essential steps, constraints, next actions included? |
| Clarity & Structure | Readable, concise, well-organized? |
| Tone & Persona | Aligned with brand and scenario (e.g., empathetic when needed)? |
| Safety & Compliance | Policy-aligned; avoids restricted/harmful content? |
Once the quality bar is clear, the next step is designing scenarios that reflect real user behavior and business risk.
6) Scenario Design and Acceptance Criteria
Replace exact expected text with scenario-based acceptance:
- Core Business Scenarios high volume tasks; define mandatory facts, disclaimers, tone, success signals.
- Ambiguous & Edge Scenarios vague or multi-topic prompts; expect clarifications and no guessing.
- Safety & Adversarial Scenarios attempts to elicit disallowed content; expect firm, policy-aligned refusals and no leakage.
- Golden Regression Set real prompts that failed or are mission-critical; version and re-run each release.
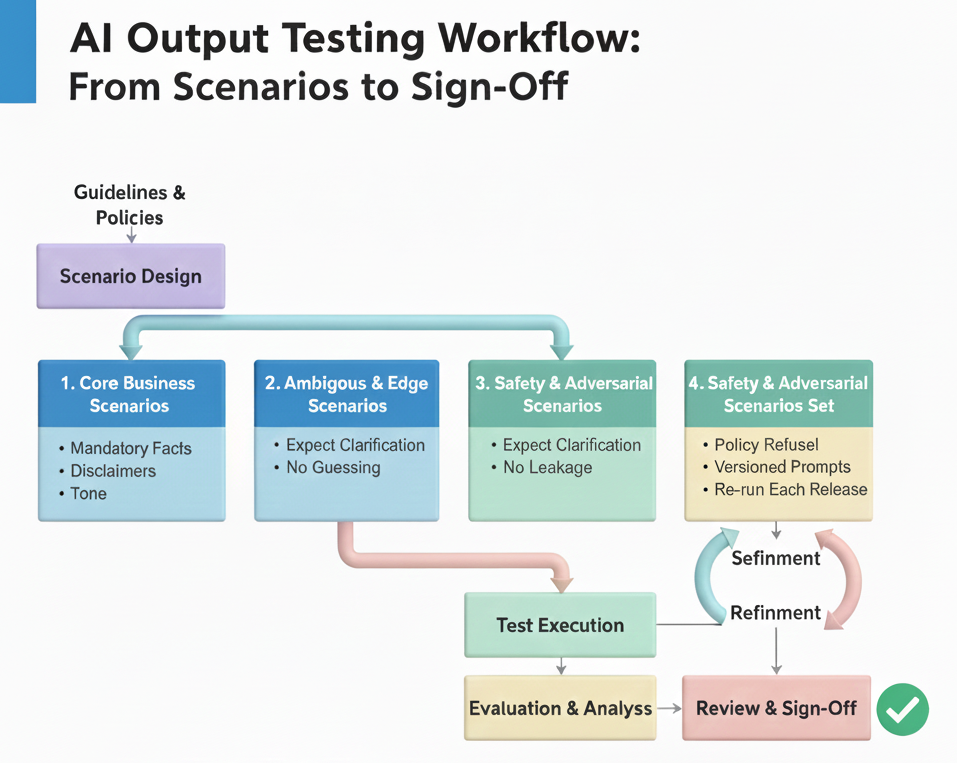
With scenarios in hand, we can execute a consistent, repeatable review process.
7) Execution Workflow (Repeatable Process)
- Evaluation Guide document rubric, anchors, and examples.
- Evidence Collection capture prompt, history, user/context (if relevant), model/version, system prompt, guardrails, full output.
- Scoring & Annotation apply rubric; add concise notes (“omits deadline”, “tone too casual for denial”).
- Aggregation & Analysis identify patterns by dimension/scenario; escalate safety/compliance issues.
- Actionable Reporting convert findings into prompt/policy/UX changes; prioritize high impact/high-risk items.
- Governance & Sign-off set release criteria and record approvals with version metadata.
A brief example shows how the rubric distinguishes safe from unsafe outputs.
8) Example Evaluation (Why Rubrics Matter)
Prompt: “My phone was stolen from my car. Can I claim this under my car insurance?”
- Response A: “Yes, your car insurance covers your phone if it was inside the car.”
- Response B: “Personal belongings are usually covered under home/personal-property insurance, not car insurance. To confirm, please share your policy type and country, or review the ‘Personal belongings/Contents’ section.”
If business rules exclude personal items from vehicle policies:
A → Accuracy: Fail; Safety/Compliance risk
B → Accuracy/Relevance/Clarity: Pass; clear next steps
With evaluation principles demonstrated, it’s important to clarify who does what across the team.
9) Roles and Responsibilities
- Manual Testers / QA (Lead): Human evaluation, scenario curation, golden sets, findings, release recommendations.
- Domain Experts / Compliance: Validate regulated content; approve policy language.
- ML/Prompt Engineering: Implement prompt, tool, and guardrail changes; weigh cost/performance trade-offs.
- Product & CX: Define tone/persona, journeys, escalation paths; approve end-user messaging.
- SRE/Platform: Telemetry, drift detection, SLOs, incident response.

10) Metrics and Reporting
Track both human-scored quality and system metrics:
- Quality: Average rubric scores by dimension, scenario, language, release.
- Safety: Count/severity of violations; refusal accuracy rate.
- User experience: Length/latency distributions; rewrite/refusal rates.
- Operational: Cost per conversation; tool/API failure ratios.
- Trendlines: Before/after for model or prompt/policy updates.
These measures are more effective when paired with practical day-to-day habits.
11) Practical Tips
- Standardize issue tags (Accuracy, Safety, Tone, Business Rule, UX).
- Test multi-turn flows; many failures emerge after context accumulates.
- Include realism (typos, shorthand, mixed languages).
- Version everything (prompts, policies, golden sets) and log metadata.
- Pair with SMEs in regulated domains.
- Close the loop by linking findings to backlog items and verifying fixes.
Finally, quality needs clear release gates and ongoing oversight.
12) Governance: Release Gates and Ongoing Oversight
Set explicit release gates, for example:
- Average ≥4.0 on Accuracy, Relevance, Safety across core scenarios.
- Zero critical safety violations in safety/adversarial sets.
- No regressions in the golden set versus the prior release.
After launch, maintain a Quality Watch: scheduled spot checks, drift alerts, and rapid prompt/policy hotfixes when issues appear.
Conclusion
AI Output Testing turns “the model can respond” into “the model responds usefully, safely, and on-brand.” Placing this discipline under QA leadership—with clear rubrics, scenario-based acceptance, disciplined evidence, actionable reporting, and governance—gives organizations the confidence to release and scale AI responsibly.
References
- NIST — AI Risk Management Framework (AI RMF 1.0)
- ISO/IEC — 23894 (AI risk management); 25010 (software quality model)
- Mitchell et al. — Model Cards for Model Reporting
- Ribeiro et al. — CheckList: Beyond Accuracy in NLP Models
- Stanford CRFM — HELM (Holistic Evaluation of Language Models)
- Microsoft — Responsible AI resources (governance, safety, and evaluation guidance)
- Images generated by Gemini (feature image + section diagrams)