



1. Introduction
In today’s interconnected digital landscape, Application Programming Interfaces (APIs) have become the backbone of communication between diverse software systems. From social media platforms and e-commerce sites to cloud services and IoT devices, APIs enable seamless data exchange and functionality integration. However, with the increasing reliance on APIs, managing their usage has become a critical aspect of ensuring performance, security, and availability. This is where API rate limiting comes into play.
API rate limiting is a technique used to control the number of requests a client can make to an API within a specified timeframe. It acts as a gatekeeper, preventing abuse, mitigating denial-of-service (DoS) attacks, and ensuring fair usage among all clients. By implementing rate limiting, API providers can maintain service quality and protect their infrastructure from being overwhelmed by excessive or malicious traffic.
In this blog post, we’ll delve into the rate-limiting algorithms. We’ll explore the use of rate limiting in contemporary applications and review the most widely-used rate-limiting algorithms.
2. What is API rate limiting?
API rate limiting is a technique used to control the number of requests a client can make to an API within a specified time period. This helps prevent abuse, ensures fair use of resources, and maintains the performance and reliability of the API.
Let’s take GitHub as an example. GitHub Apps authenticating with an installation access token use the installation’s minimum rate limit of 5,000 requests per hour. If the installation is on a GitHub Enterprise Cloud organization, the installation has a rate limit of 15,000 requests per hour. For installations that are not on a GitHub Enterprise Cloud organization, the rate limit for the installation will scale with the number of users and repositories. Installations that have more than 20 repositories receive another 50 requests per hour for each repository. Installations that are on an organization that have more than 20 users receive another 50 requests per hour for each user. The rate limit cannot increase beyond 12,500 requests per hour.
3. API rate limiting algorithms
Leaky bucket – a first come, first served approach that queues items and processes them at a regular rate.
The Leaky Bucket algorithm can be understood in this way: Imagine a server with a bucket that has a set capacity and an opening at the bottom for discharge, which is used to store a specific quantity of tokens. The tokens symbolize the requests that are made to the server. The user, or client, dispatches tokens to the server, which acts as the intermediary, regulating the admission and release of tokens from the bucket.

Consider a bucket that has a tiny opening at its base. The speed at which water is added to the bucket can fluctuate and isn’t steady, yet the water escapes from the bucket at a uniform rate. This means that as long as there is water in the bucket, the leakage rate is constant and does not change based on how quickly water is poured into the bucket.
The Leaky Bucket algorithm can enforce rate limiting:
- Each incoming request is treated like a “drop” in the bucket.
- The bucket processes the requests at a fixed rate, ensuring that even if there’s a sudden influx of requests, they are processed steadily, avoiding overloading the system.
- If the bucket overflows (i.e., the incoming rate is higher than the allowed rate for too long), excess requests can be dropped or delayed.
Token Bucket -Imagine a bucket containing a certain number of tokens. For a request to be processed, a token must be taken from the bucket. If there are no tokens left in the bucket, the request is denied, and the requester must try again later. The bucket is refilled with tokens at regular intervals.
This mechanism allows us to control the number of requests a user can make within a given time frame by assigning each user a bucket with a fixed number of tokens. Once a user depletes all their tokens within that period, any additional requests will be rejected until the bucket is refilled.

Fixed window – The fixed window counter algorithm segments the timeline into fixed-size intervals, each with its own counter. When a request arrives, it is assigned to the corresponding time window. If the counter for that window has already reached its limit, any additional requests within that same window will be denied.
For instance, if we set the window size to one minute and the limit is two requests per minute:
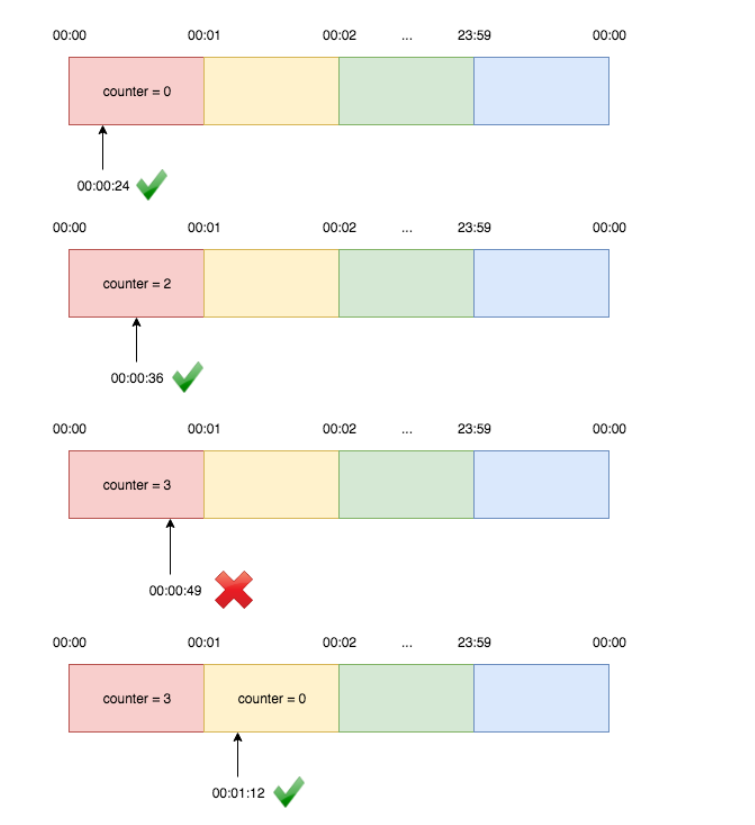
Clearly, the fixed window counter algorithm ensures the average request rate within each individual window but not across overlapping windows. For example, if the desired rate is two requests per minute and there are two requests at 00:00:58 and 00:00:59, followed by two more requests at 00:01:01 and 00:01:02, both the [00:00, 00:01) and [00:01, 00:02) windows will have a rate of 2 requests per minute. However, the rate for the overlapping window [00:00:30, 00:01:30) will actually be 4 requests per minute.
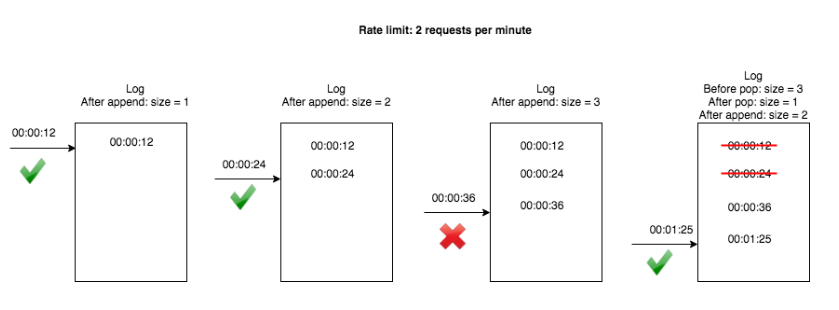
Moving/sliding window – similar to a fixed window but with a sliding timescale, to avoid bursts of intense demand each time the window opens again. The sliding window log algorithm maintains a log of request timestamps for each user. When a new request arrives, all outdated timestamps are removed from the log before adding the new request’s timestamp. We then determine if the request should be processed by checking if the log size exceeds the limit. For instance, if the rate limit is two requests per minute:
4. Why is Rate Limiting Important?
- Prevent overuse due to accidental issues in client code that result in an excessive number of requests.
- Guard against denial-of-service (DoS) attacks designed to overwhelm API resources, which could occur without rate limits.
- Protect your API from events that could affect its availability.
- Ensure that all users receive efficient and high-quality service.
- Support different API monetization models.
5. Conclusion
In conclusion, this blog aims to offer a balanced and comprehensive overview of API rate limiting, synthesizing insights from various sources. We’ve discussed several key algorithms, such as the token bucket, fixed window counter, and sliding window, each with unique approaches to managing request rates. By understanding the strengths and limitations of these methods, we hope to provide a helpful foundation for designing APIs that can effectively manage traffic and maintain system performance.
6. References
https://www.krakend.io/docs/throttling/token-bucket
https://toidicodedao.com/2020/03/17/rate-limiting-chong-ddos-p1/
https://hechao.li/2018/06/25/Rate-Limiter-Part1/