



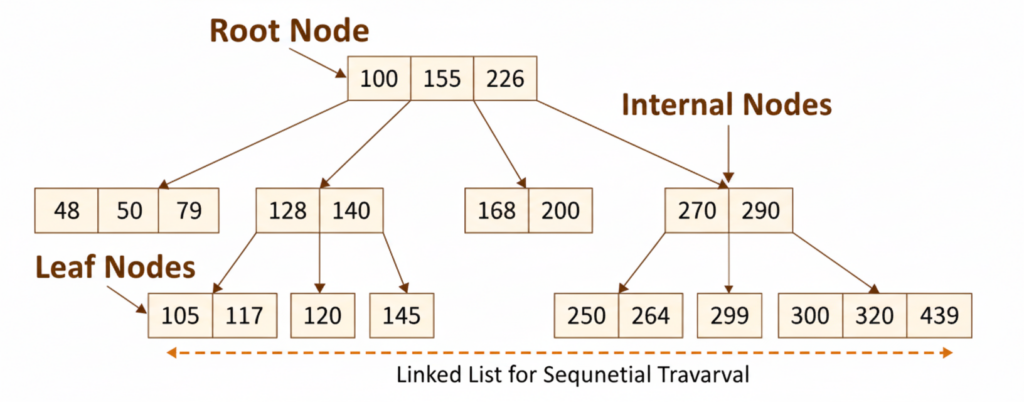
🧩 Definition
A B+Tree (Balanced Plus Tree) is an advanced form of the B-Tree data structure, optimized for database indexing and file systems. It maintains data in a sorted and balanced way, allowing fast search, insertion, deletion, and range queries.
Unlike the traditional B-Tree, where data can appear in both internal and leaf nodes, the B+Tree stores all actual data only in the leaf nodes, while internal nodes only keep keys to guide navigation.
Because all leaf nodes are linked sequentially, B+Tree supports efficient range scans — making it ideal for operations like:
SELECT * FROM customers WHERE age BETWEEN 72 AND 115;
In PostgreSQL, the B+Tree is the default index type, forming the backbone of how indexes speed up query performance.
⚙️ Components of a B+Tree
B+Tree consists of several key parts:
1. Root Node
– This is the starting point for any search operation in the tree.
– It contains only keys (also called index keys or separators) and pointers to child nodes.
– Its primary function is to direct the search to the appropriate child node.
2. Internal Nodes (Branch Nodes)
– These nodes lie between the root and the leaf nodes.
– Like the root, they also contain only keys and pointers to child nodes. They do not store actual data records.
– Their purpose is purely for navigation and routing the search down the tree.
3. Leaf Nodes
– This is where the most significant difference from a standard B-tree lies.
– All actual data entries (or pointers to the actual data records in a separate data file) are stored only in the leaf nodes.
– The leaf nodes are linked together sequentially (often as a doubly-linked list). This linking is crucial for efficient range queries, as once the starting point of a range is found, the database can traverse horizontally through the leaves without needing to go back up the tree.
– Each leaf node entry typically contains an index key and either the full data record associated with that key or a pointer (ROWID) to where the actual data record is stored on disk.
🌿 Features of B+Tree Index
| Feature | Description |
|---|---|
| Balanced Structure | All leaf nodes are at the same depth, ensuring consistent access time. |
| Ordered Keys | Keys in each node are stored in sorted order. |
| Efficient Range Queries | Sequential links between leaf nodes enable fast range scans. |
| Dynamic Growth | Automatically splits and merges nodes to stay balanced as data changes. |
| Disk-Friendly | Each node typically matches a PostgreSQL page (8KB), minimizing disk I/O. |
🔍 How B+Tree Works
Let’s take an example of a simple table:
CREATE TABLE customers (
id SERIAL PRIMARY KEY,
age INT,
name TEXT
);And an index:
CREATE INDEX idx_customers_age ON customers(age);Now imagine the ages stored are:
10, 20, 30, 40, 60, 70, 80, 90, 110, 120, 130Step 1 — Organize and Split
PostgreSQL sorts the data and divides it into leaf blocks (e.g., groups of 4 keys per leaf):
[10,20,30,40] [60,70,80,90] [110,120,130]Step 2 — Choose Split Keys
Split keys (like 50 and 100) are chosen to guide lookups:
[50 | 100]
/ | \
[10,20,30,40] [60,70,80,90] [110,120,130]Step 3 — Searching
To find between 72 and 115, PostgreSQL:
1. PostgreSQL starts at the root node [50 | 100].
– Since 72 lies between 50 and 100, it follows the middle branch.
2. It reaches the leaf node [60,70,80,90].
– It skips values below 72 and retrieves 80 and 90.
3. Because the range continues up to 115, PostgreSQL follows the linked pointer to the next leaf node,[100,110,120,130].
– From there, it fetches 100 and 110.
Result: Values found → 80, 90, 100, 110
All done with just a few sequential leaf reads, thanks to the linked structure of the B+Tree.
⚖️ Difference Between B+Tree and B-Tree
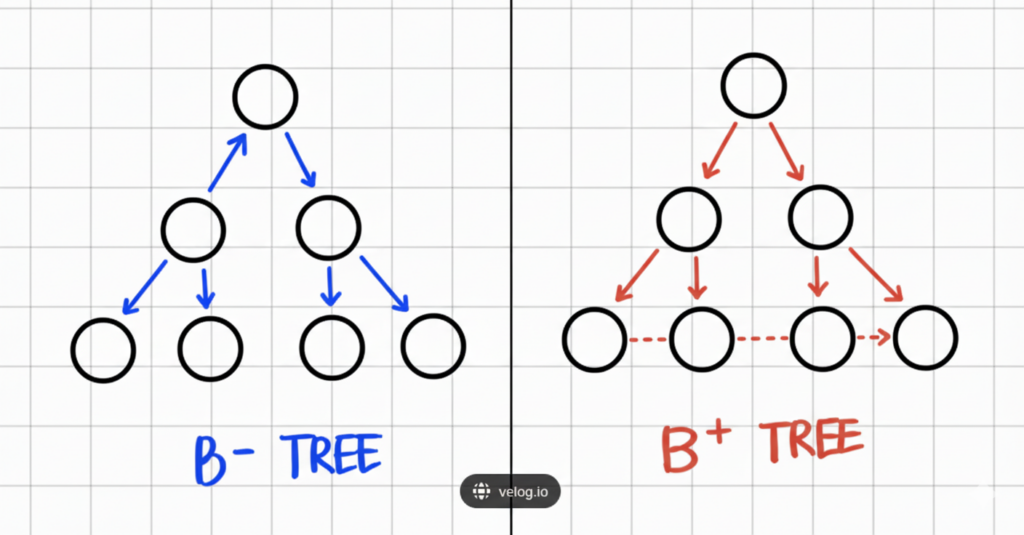
| Feature | B-Tree | B+Tree |
|---|---|---|
| Where data is stored | In all nodes (internal + leaf) | Only in leaf nodes |
| Internal node keys | Contain actual data | Contain only copy/reference keys |
| Leaf node linkage | No link between leaves | Leaves are linked sequentially |
| Range scan performance | Slower | Very fast |
| Storage overhead | Slightly smaller | Slightly larger |
| Used in PostgreSQL | ❌ (conceptual ancestor) | ✅ Yes (default index type) |
🧠 Why B+Tree Scales Well
The B+Tree scales excellently because its design minimizes Disk I/O operations, which is the slowest part of data retrieval.
1. High Fan-out (Branching Factor):
– Internal Nodes store Keys and Pointers only, excluding large data records.
– This allows each node to hold hundreds of pointers, resulting in a very flat tree structure with few levels.
2. I/O Optimization:
– Each tree level corresponds to one single Disk Block Read (e.g., 8KB).
– Because the tree is so flat (typically 3–4 levels deep), finding a record out of millions only requires 3–4 I/O operations—making searches incredibly fast.
🏁 Conclusion
B+Tree is truly the heart of PostgreSQL indexing.
It combines balance, order, and efficiency, making it perfect for workloads that involve:
– Equality searches (=)
– Range scans (>, <, BETWEEN)
– Sorting (ORDER BY)
In essence:
Without B+Tree, PostgreSQL wouldn’t be nearly as fast or efficient at data retrieval.
Every time you run a query that uses an index,
somewhere deep inside PostgreSQL —
a B+Tree is doing the heavy lifting for you. 💪