



Machine Learning (ML) is a core branch of Artificial Intelligence (AI) that focuses on giving computers the ability to improve their performance through data and experience. Instead of being explicitly programmed with rigid rules, ML systems can learn patterns, make predictions, and make decisions on their own based on the examples they are trained on.
Categorizing Machine Learning Algorithms
When you first venture into the vast landscape of Machine Learning, it is easy to feel overwhelmed by the sheer diversity of algorithms—each boasting its own unique logic and specialized goals. To give you a sense of this scale, take a look at the map below, which visualizes over 40 distinct algorithms that form the backbone of modern AI. Looking at such a vast ecosystem, one might wonder: where do we even begin?

The good news is that you don’t have to learn this entire ‘pile’ of algorithms just to start with ML. Still, it’s worth keeping them on your radar for when the right problem comes along. For now, we’ll stick to the essentials and cover only the most common ones.
To keep things organized, we usually group ML algorithms in two ways:
- Learning Style: How the algorithm ‘learns’ from the information it’s given.
- Functional Similarity: Grouping algorithms that share a similar purpose or mathematical foundation.
1. Classification by Learning Style:
Supervised Learning
Supervised Learning is the most widely used category of Machine Learning algorithms. It focuses on predicting the outcome of new data points (new inputs) based on a set of pre-defined (input, outcome) pairs. These pairs are commonly referred to as (data, label).
Prerequisite: The data must be clearly and consistently labeled — for example, an image should be tagged with its corresponding label such as “cat.”
Objective: To predict the correct labels for new data.
Example problems: Classification, Regression.
- Classification: The goal is to predict a discrete label or category.
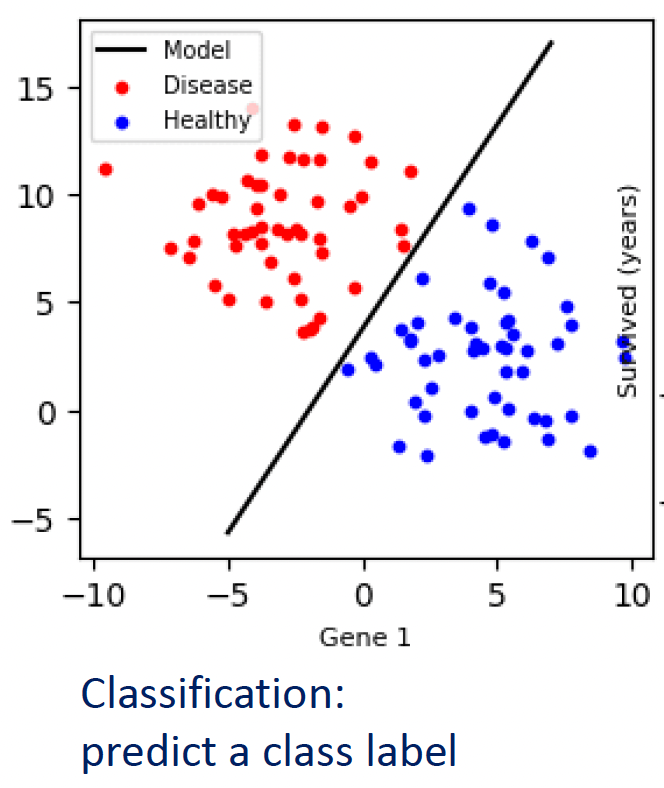
- Regression: The goal is to predict a continuous, numerical value.
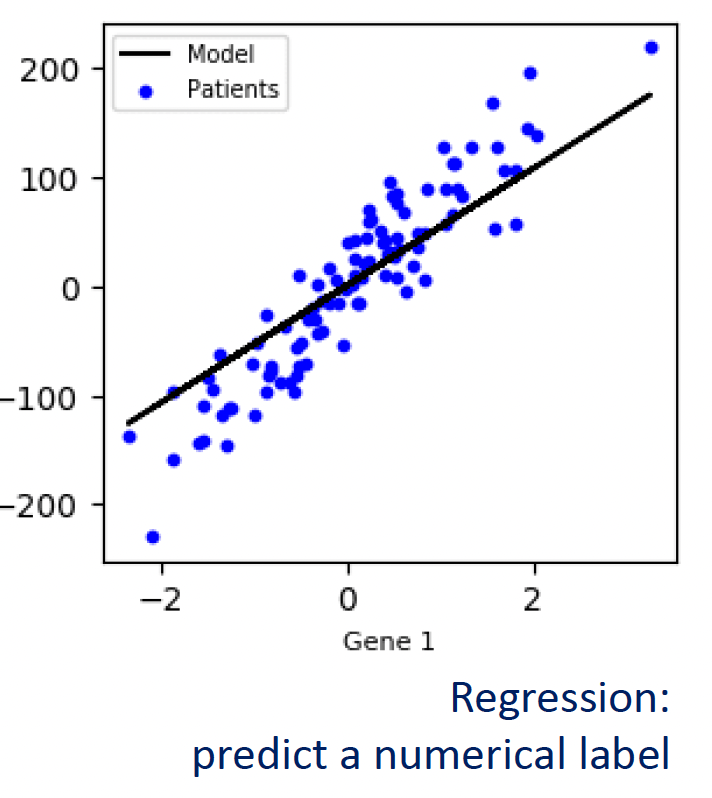
Unsupervised Learning
Here, the machine is given raw data without any labels. It must act as an explorer to find hidden structures or patterns on its own.
Prerequisite: The data is unlabeled — no predefined categories or target values are provided.
Objective: Discover the underlying patterns or structures within the dataset, such as grouping similar samples, reducing dimensionality, or compressing information while preserving its essence.
Example use cases: Clustering, Dimensionality Reduction.
- Clustering: Grouping similar data points together based on shared characteristics (e.g., Customer Segmentation).
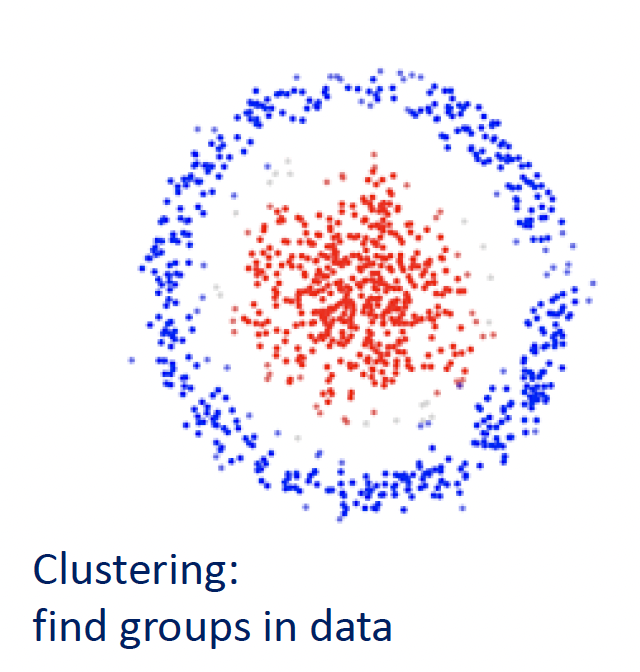
- Dimensionality Reduction: This process aims to simplify complex datasets by reducing the number of input variables (features) while retaining as much critical information as possible.
Semi-Supervised Learning
This is a hybrid approach used when you have a massive amount of data but only a small portion is labeled. It uses the small labeled set to “guide” the learning process for the much larger unlabeled set, saving time and costs on manual labeling.
Prerequisite: The data consists of a small portion with labels and a large portion without labels.
Objective: To leverage the small labeled dataset to “guide” the model’s understanding of the vast unlabeled dataset. By doing so, the model can achieve high accuracy while significantly reducing the cost and effort of manual labeling.
Example use cases: classification with limited labeled data, semi-supervised image recognition, semi-supervised text analysis.
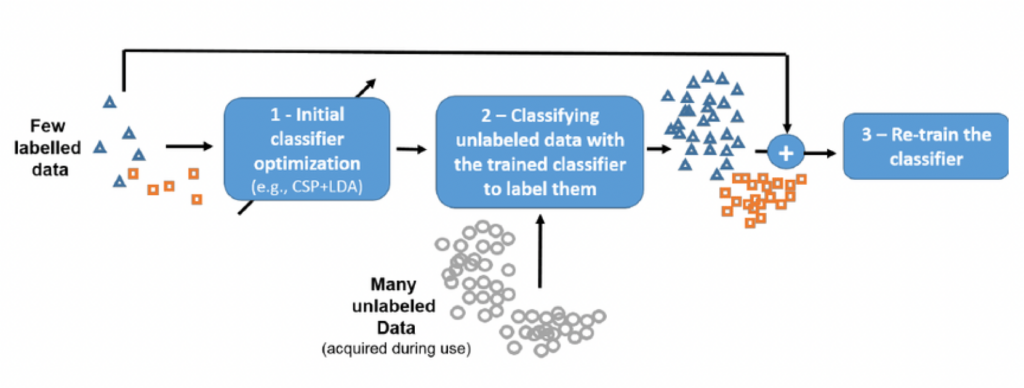
You can easily visualize the difference between supervised and unsupervised learning through the illustration below.

Reinforcement Learning
An agent learns to interact with an environment based on feedback signals it receives from the environment
Prerequisite: A learning model that uses trial and error, rewards or punishments.
Objective: Optimizing actions to achieve the highest total reward.
Example use cases: Robots learning to walk, AI playing games, dynamic recommendation systems.
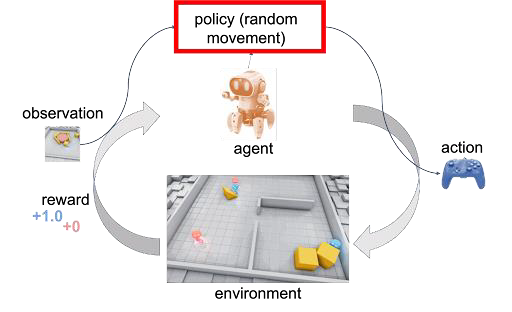
Trial and error: the learner is not told which actions to take, instead discover which actions yield the most reward by trial
The AlphaGo Moment: Why RL is the Future
The most iconic demonstration of RL’s power is AlphaGo, developed by Google DeepMind. For decades, the game of Go was considered the “Holy Grail” of AI because its complexity—with more possible board configurations than there are atoms in the observable universe—made it impossible to conquer using brute force or rigid, hand-coded rules.
- Beyond Human Limits: While initial versions of AlphaGo learned by studying thousands of human games, the true breakthrough came with AlphaGo Zero. It started with a completely blank slate (zero knowledge), learning purely by playing against itself millions of times.
- The Power of RL: Through Reinforcement Learning, the system didn’t just mimic human experts; it surpassed thousands of years of human wisdom. It discovered “divine” moves and creative strategies that no human player in history had ever imagined.
Why RL Stands Alone:
- Autonomy: It doesn’t require a teacher to provide a “correct” label for every action. Instead, it discovers the optimal path through autonomous trial and error.
- Adaptability: It excels in dynamic, high-stakes environments where a single decision’s success depends on a long, complex sequence of future events.
- Innovation: RL models often find “out-of-the-box” solutions that humans might overlook. This makes it the go-to technique for the future of robotics, autonomous driving, and complex strategic planning.
Reinforcement Learning isn’t just about learning from data — it’s about learning directly from experience.
Next Blog: Categorizing Machine Learning Algorithms (Part 2)
We have now explored the four major learning styles that define how machines process information. However, understanding the ‘how’ is only half of the story. To truly master the ML landscape, we need to look at these algorithms through a different lens: their specific roles and mathematical structures.
Join me in the next post, where we will categorize the ML world by Functional Similarity. We’ll break down the most popular algorithms by what they actually do. Don’t miss it!