
What is a Data mesh?
Data mesh is a new architectural approach coined by Zhamak Dehghani that emphasizes the decentralization of data ownership, governance, and infrastructure. The idea of Data Mesh was initially introduced in 2019, and its maturity has been evolving since 2021. It responds to the limitations of traditional centralized data warehouses, which can be inflexible, expensive to maintain, and difficult to scale. Gartner calls it a solution architecture for the specific goal of building business-focused data products.
The evolution of data solution is below.

Figure 1- the evolution of data solution
In this blog, I would share our experience in adopting data mesh to build a Proof of Concept (PoC) that apply in Education sector. Within this sector, there are multiple reasons why adopting a data mesh can be advantageous.
Why adopting data mesh can be advantageous?
1. Reduced Data silos: Universities or Colleges usually have multiple disparate systems that store various types of data, including Student Information System (SIS), Learning Management Systems (LMS), Content Management System (CMS) and so on. This can result in data silos which make it difficult for different departments to share data and work collaboratively. A data mesh approach can help break down these silos and enable more effective sharing and collaboration across different departments and systems.
2. Improved Data quality: With the increasing volume and complexity of data in education, it can be challenging to maintain data quality. A data mesh approach help establish clear data ownership and governance, enabling data stewards to take responsibility for data quality and ensure that data is accurate, consistent, and up to date.
3. Reduced bottlenecks: The central data team with traditional DW/Data Lake approach may become a bottleneck. The team cannot handle all the analytical questions of management and product owners quickly enough. Data Mesh decentralizes these tasks, enabling multiple domain teams to work concurrently, thereby reducing bottlenecks and accelerating data delivery.
4. Faster time to insight: With domain teams responsible for managing their data products and team can interact directly with Business owner, the time it takes to transform raw data into actionable insights is reduced. Teams can iterate and experiment with data pipelines and analytics independently, leading to faster insights.
5. Improved Data privacy and security: Many universities use legacy systems that might lack modern security features. Integrating these systems with new technologies while ensuring data security can be complex. They are also responsible for handling sensitive student, ensuring compliance with strict data privacy and security regulations like GDPR or FERPA. A data mesh approach with clear data ownership and consent can help ensure that data is securely and appropriately shared only with authorized parties, while still enabling data discovery and exploration.
6. Scalability and Agility: Data Mesh provides a scalable and agile framework for managing data. By distributing data ownership and responsibilities to domain-specific teams, organizations can more effectively handle growing data volumes and complexity. This agility allows for quicker responses to changing business needs.
Key elements of a Data mesh
Data product
A data product is a data set that is cleaned and transformed for analytical purpose. It can be published to other teams and should comply with global policies defined by federated governance group.
Transformation
In real-world situations, data is often integrated from one or multiple data products as external data. This data is then merged with domain-specific data to facilitate transformations and aggregation processes answering analytical questions within that specific domain. The domain data can be shared with other teams by establishing a data contract. This contract is typically implemented by a view, which is stable even when the underlying data models change.
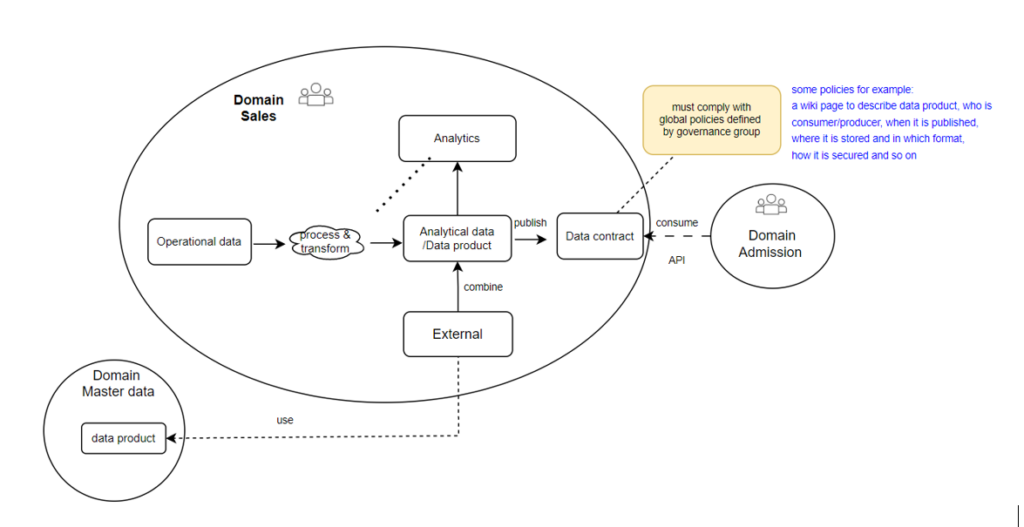
Figure 2 – how data integrated to each other
Global policies
- The federated governance group is typically organized as a guild consisting of representatives of all teams taking part in the data mesh. They agree on global policies, which are the rules of play in the data mesh. In our context, a sales team need to collect master data from Domain team (Master data) and its data product will be used by Admission team later.
- An example of policies we defined.
- Interoperability policy: all data products would be published via API.
- Documentation policy: a wiki page with a predefined set of metadata such as owner of the data product, who is consumer, location, and descriptions of data product.
- Security policy: implement role-based access control using Azure IAM.
Roles and responsibilities in Data mesh
In the data mesh approach, a few teams are involved to support scaling, each with its own set of responsibilities.
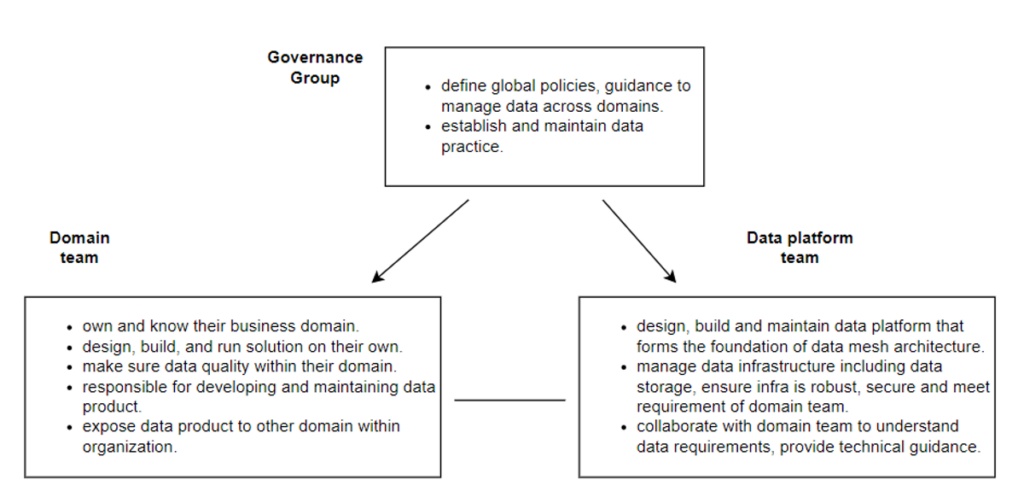
Figure 3 – Roles and responsibilities
- Domain team: normally include Business Owner, Data Engineer, Data Analyst, and Quality Control (QC)
- Data platform team: Data Architect, Data Engineer, DataOps or DevOps
- Governance group: Representatives from all domain teams
Our technical approach
When working in Azure, the natural way to decentralize and apply data as a product could be by using Resource Groups. This logical structure of cloud organization seems like a good way to separate the data ownership/architecture and allow a given domain to operate independently, within a Resource Group. In our context, we designed three resource groups representing for three domains.
1) Master data – all master data would be imported into a master database, go through data cleansing process before data exported to share with another domain team.
2) Sales – handle business inside sales process involves various steps aimed at promoting and providing educational programs, services, and offerings to prospective students.
3) Admission – track the process of applying to a University/College and being accepted as a student. Review and apply decisions to applications from submission to outcome.
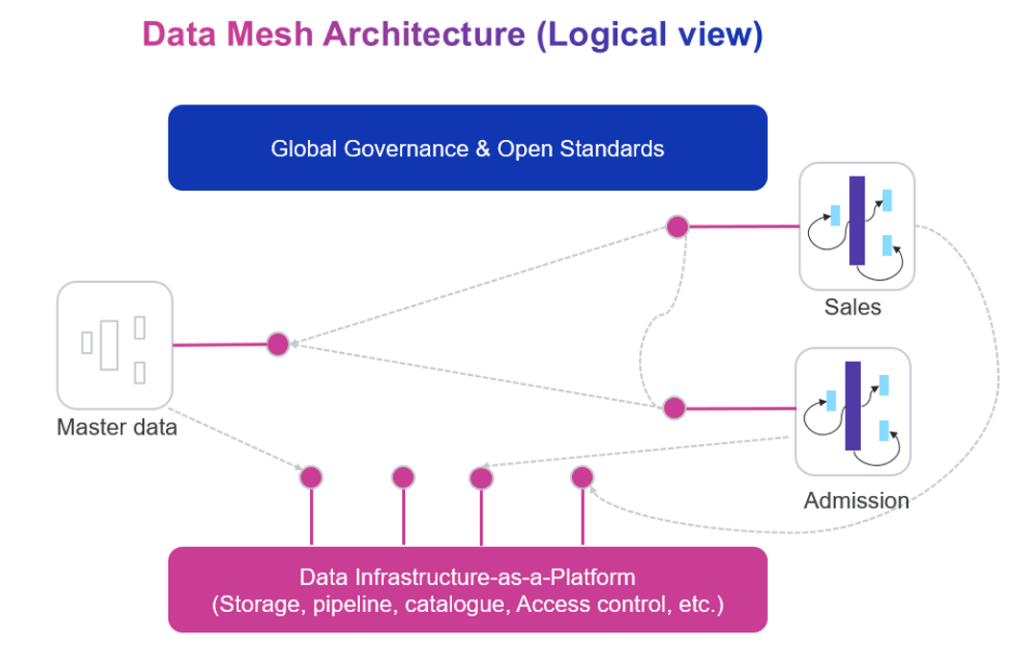
Figure 4 – Data mesh architecture – logical view
The architecture designed for Sales and Admission domain, built around the Lakehouse solution using NashTech Data Accelerator. It can be customized to address the requirements of other domain teams. To catalog, manage, govern the data, we use OpenMetadata and Azure Key Vault services for manage secret key during implementation. Data processing is carried out using Azure Databricks for data cleansing and transformation. Additionally, Azure Data Lake Gen 2 is utilized for data storage, while Azure SQL fulfills auditing needs.
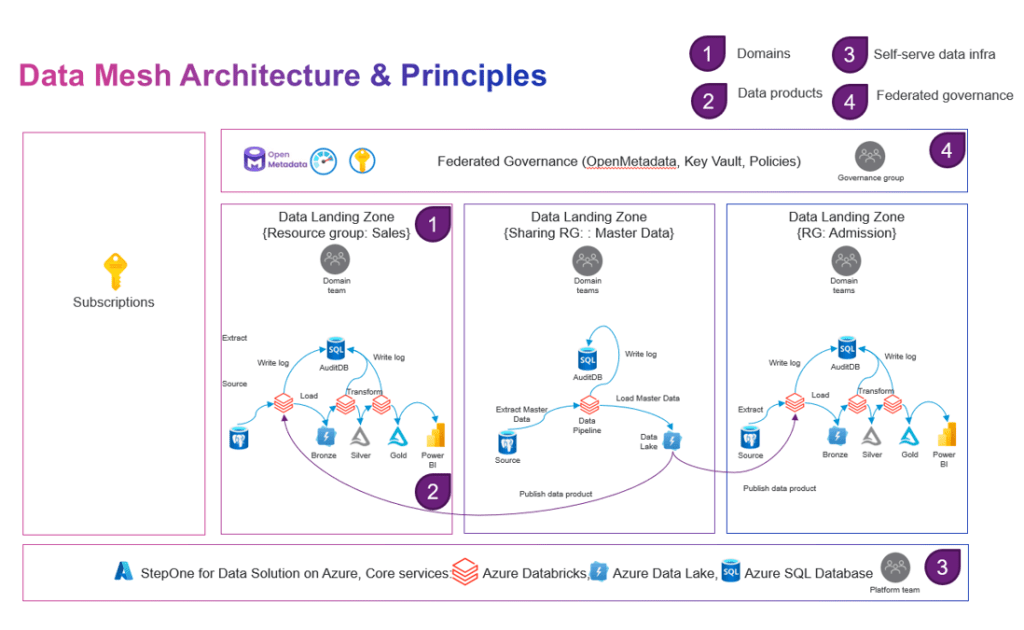
Figure 5 – Data mesh architecture – physical view
Different ways to share data product with others.
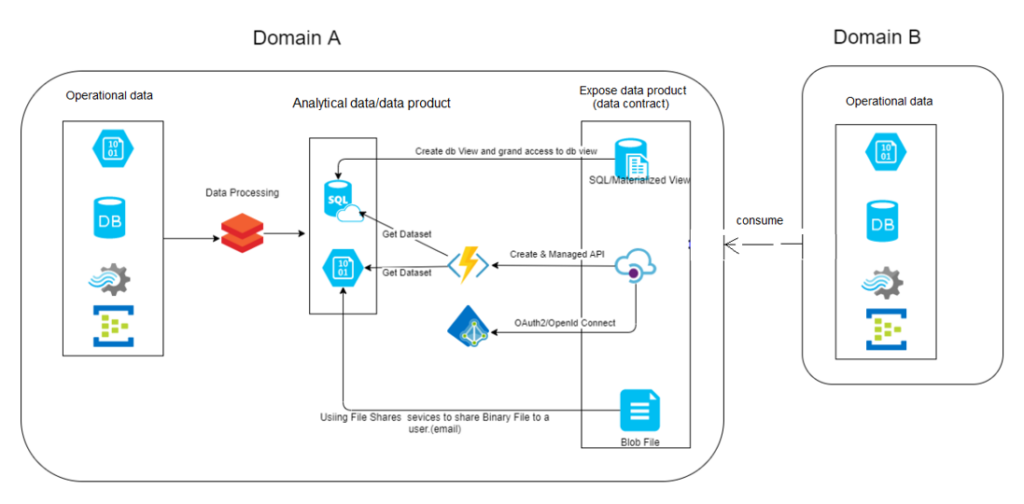
Figure 6 – Different ways to expose data product to other team
There are number of ways to share data product with other teams.
1) Expose via SQL view: Domain A user simply create a data product (using SQL view) by merging data from 1 to many tables within its database. Domain A then create a new user login and grant SELECT permission on SQL View to that user. The connection details are shared with Domain B to access to the view.
2) Expose via File share service: Domain A user leverages Azure Data Share services to create a dataset, either extracted from a binary file or derived from data within a database. They then add the email addresses of Domain B users as designated recipients. After that, they configure scheduling and duration for which this dataset will be shared. Following these settings, the Azure Data Share service proceeds to send invitation emails to the specified recipients, notifying them of the data sharing arrangement.
3) Expose via API: Domain A use Azure API Management service to create an API based on a template, such as OpenAPI or GraphQL. This API is then managed to expose a specific data set, which serves as a data product. Within the API management configuration, there is a setup to route the authorization process through Azure AD services. Domain A provides an HTTPS link designed to trigger the API, thereby initiating the data retrieval process. To access the data via that API, Domain B must first successfully authenticate (login) through Azure AD services. Once authenticated, the Azure AD service issues a token key, which Domain B can utilize within the API published by Domain A to retrieve data product.
Metadata management
In practice, there are two kinds of data that we have worked with.
- business data: the actual data that we collect and process for analytics purpose within a domain team and share to other domains when necessary.
- metadata: the data provides context, description, and characteristics of business data, helping users understand and interpret the data effectively. In Data mesh, metadata has become more important than ever before. It describes everything about data domain and how data is exchanged among domain teams.
Overview of OpenMetadata tool
During the PoC phase, we examine Microsoft Purview, a cloud-based data governance tool offered by Microsoft. However, due to cost constraints, we decided to use an alternative tool called OpenMedata, an open-source metadata management tool that help us catalog, manage, and govern data across domain.
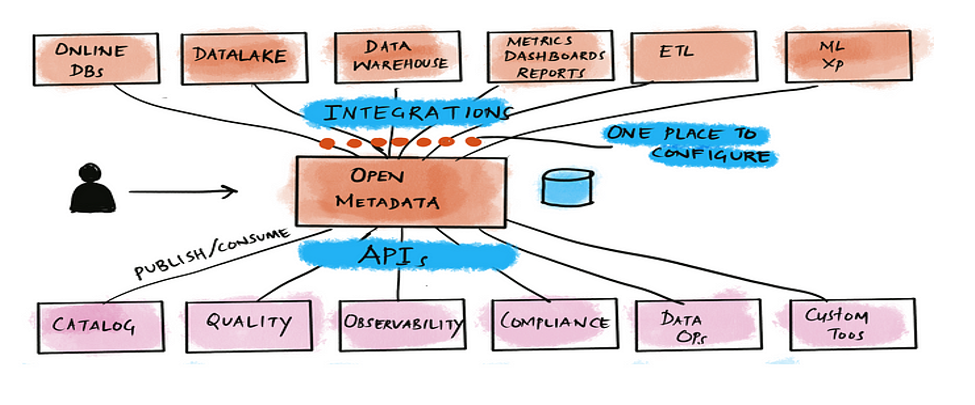
Figure 7- OpenMetaData high level view. Source: OpenMetadata
OpenMetadata offers a wide range of features as below.
- Data discovery: allows users to search for and discover relevant datasets and understand their context, usage, and quality.
- Data governance: enables defining and enforcing data governance policies, ensuring compliance with regulations and internal guidelines.
- Data lineage: helps visualize the flow of data across different systems and processes, showcasing how data is transformed and moved throughout the organization.
- Data quality: this tool help define tests and run profiles on data assets across different data sources. It allows you to group different tests together and create a test suite.
- Integrations: offers more than fifty connectors for metadata ingestion from data sources like databases, data lakes, data warehouses, business intelligence tools, message queues, data pipelines, and even other data catalogs.
Data catalog
Data catalog in OpenMetadata provide a single source of truth for metadata, enabling users to discover, understand, and access data assets more efficiently. We used data catalog to aligns data product with friendly business terms and data classification to identify data sources. The following image shows the UI where we can add description and tag for each attribute in one data set.
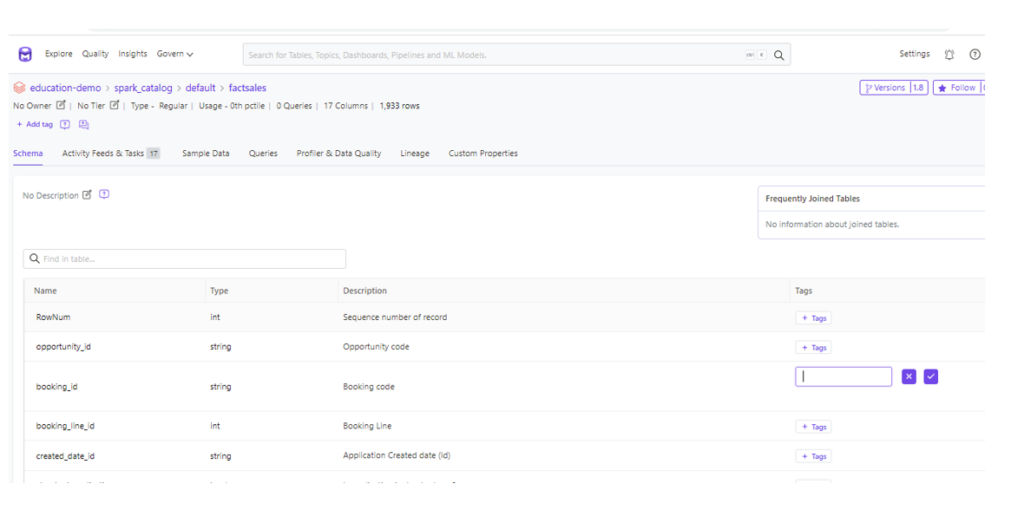
Figure 8 – Data catalog
Data governance
OpenMetadata designed based on Role-based access control to enable organization-wide data governance. A sophisticated role-based access control system with team hierarchy and a role-policy-rule-based access control sets a solid foundation for data governance in OpenMetadata. In our PoC, we have defined team hierarchy with 3 layers: Department (Sales, Admission, Master data), Division, and Group. Low level automatically inherited roles-policies-rules setting of parent/higher level in hierarchy.
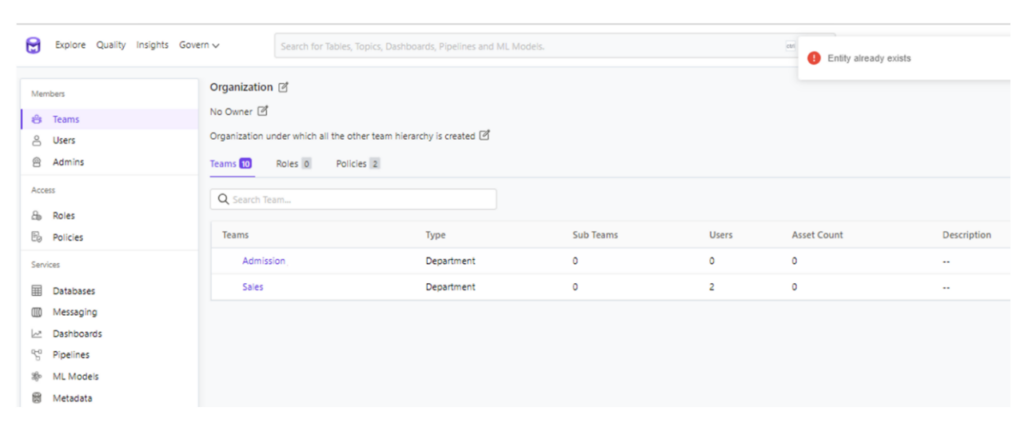
Figure 9 – create team hierarchy with 3 layers.
After team hierarchies created, we follow the UI on the page (below) to create and manage different policies and add rules associated to the policy.
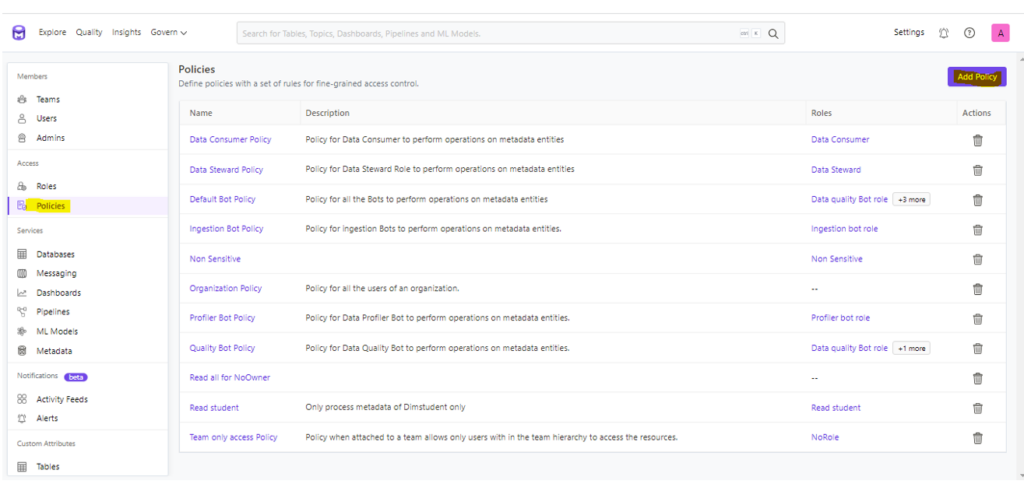
Figure 10 – add policy and rule
And this image shows the page on the UI where you can create and manage roles. We can attach policies to role to help control access to metadata operations.
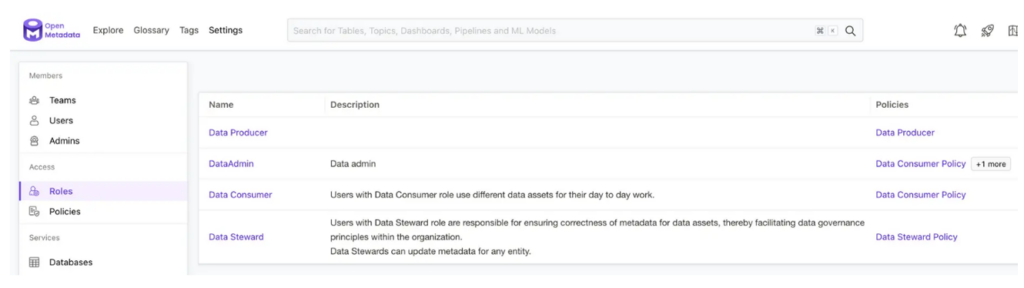
Figure 11 – create and manage roles
Data quality
OpenMetadata has tightly integrated data quality in the UI to enable data teams to make it a part of their usual workflow. This way data quality issues are always visible to the team consuming the data, which makes fixing these issues faster and easier. It is the feature I like the most on OpenMetadata tool. For example, Data Profile feature inside a dataset include table and column level can help answer questions like number of Null value and its percentage, number of distinct value and percent over total number of rows in dataset.
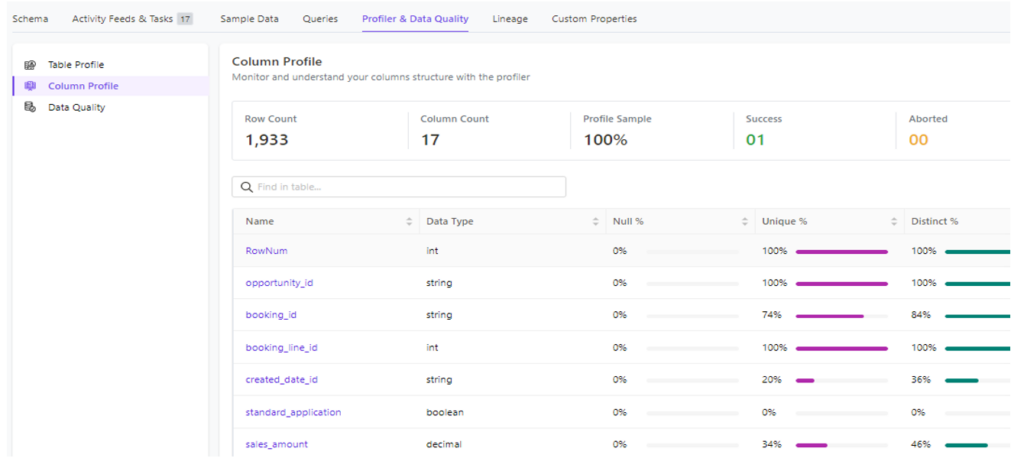
Figure 12 – Column profile
It’s also easy for us to set up and execute a test case from UI.
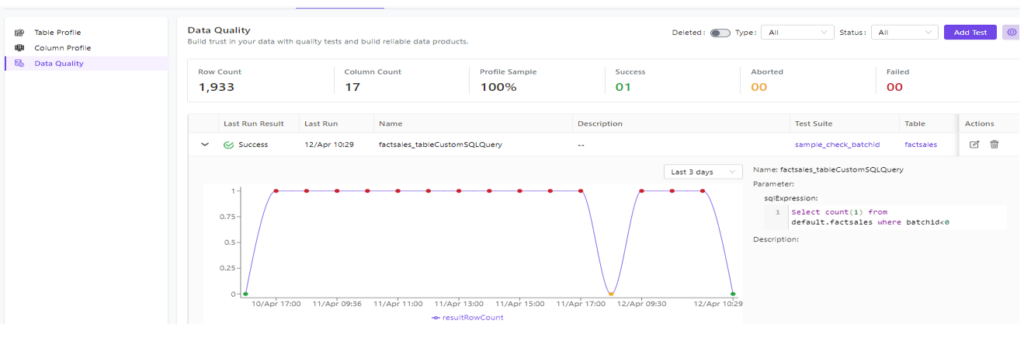
Figure 13 – Data quality check
Data Visualization in one domain
After data in one domain has been extracted, transformed, and loaded into an Analytical layer, we use Power BI to establish a connection to this layer, build report model and create visualizations specific to each domain, as illustrated below.
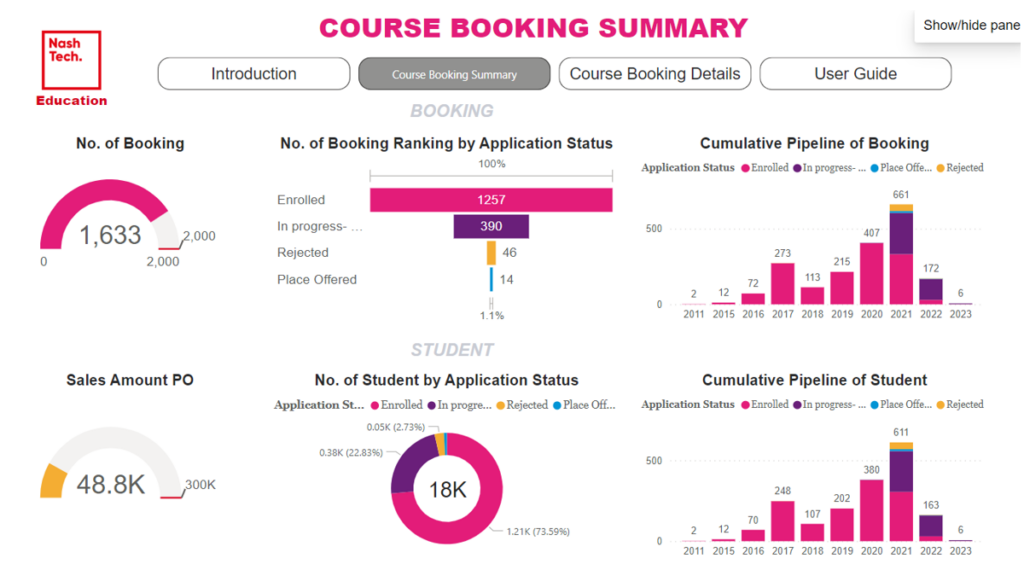
Figure 14 – Power BI Dashboard on Sales domain
Conclusion
By adopting the data mesh approach, we aim to achieve a more scalable, flexible, and data-driven ecosystem where domain teams can efficiently process, analyze, and act upon data that is relevant to their business domain. This approach reduces data silos, faster to gain insights, improved data sharing, and promotes a culture of data ownership and responsibility across the organization. However, if your organization is small and lacks multiple independent engineering teams and requires low-latency data, Data mesh might not be suitable.
References
- https://www.innoq.com/en/articles/2022/04/data-mesh-decentralized-data-analytics-for-software-engineers/
- Data Mesh Architecture (datamesh-architecture.com)
- https://learn.microsoft.com/en-us/azure/api-management/api-management-howto-protect-backend-with-aad
- Summary Translation: Quick Answer: Are Data Fabric and Data Mesh the Same or Different? (gartner.com)
- https://www.xenonstack.com/insights/data-lake-vs-warehouse-vs-data-lakehouse