



Generative AI – Part 3: The Architecture Behind GenAI
Every time you chat with ChatGPT or watch GitHub Copilot write code, you’re experiencing the power of a single architecture: the Transformer. It’s the breakthrough that turned Generative AI from interesting research papers into real tools used by millions.
In the first two parts, we covered what Generative AI is and how machines learn patterns to create new content. Now, it’s time to explore the key architecture that made it all possible: the Transformer.
1. Before Transformers: The Struggle of RNNs and LSTMs
Before 2017, sequence models were built on Recurrent Neural Networks (RNNs) or their smarter cousin, LSTMs.
They processed text one word at a time, passing a hidden “memory” forward as they read.
It worked, but not well for long texts:
- They forgot earlier context when sentences got too long.
- Training was slow because you couldn’t parallelize easily.
- Long-term connections (like a word at the start affecting meaning much later) were weak.
Think of it like trying to read a whole novel but only remembering the last sentence you saw. Not great.
2. The Breakthrough: Attention Is All You Need
In 2017, Google researchers published a paper called “Attention Is All You Need.”
The big idea: instead of reading words one by one, let the model look at the whole text at once and decide which words matter most for the current prediction.
This mechanism is called Attention.

3. What Is Attention?
Here’s a simple example:
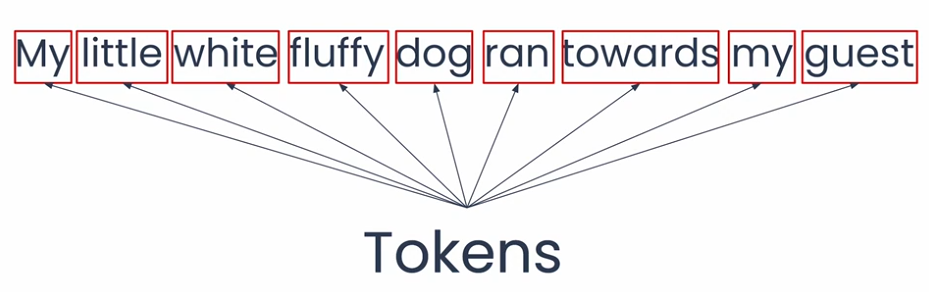
“My little white fluffy dog ran towards my guest.”
How does the model understand what “dog” really means here? Attention helps it focus on the important words — little, white, fluffy — to realize this is a small, white, fluffy dog, not just any random or aggressive dog.
With that context, the model is more likely to predict the next words as “and greeted them enthusiastically” instead of something unrelated.

In practice, here’s how it works:
- Text is split into tokens (words or smaller chunks).
- Each token is mapped to a vector of numbers called an embedding.

- Attention adjusts these embeddings based on the surrounding context.
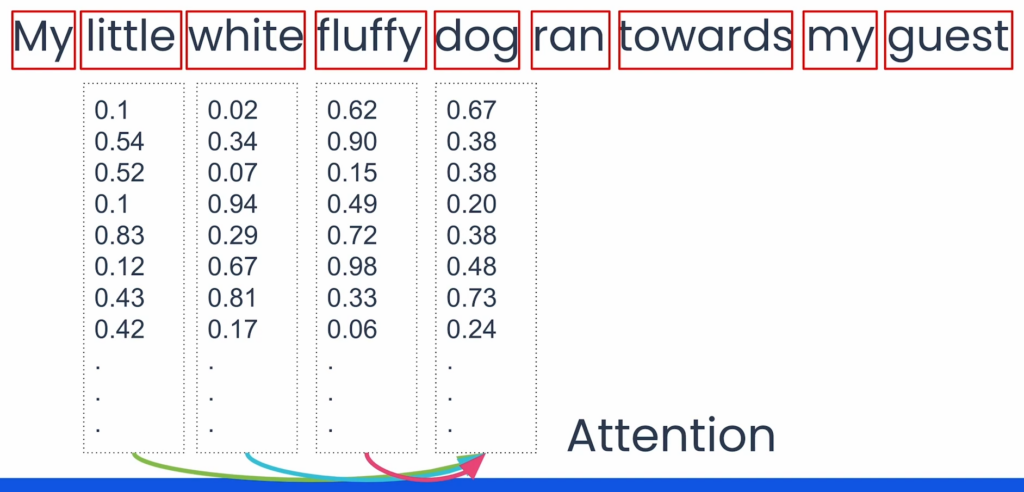
- The result: the model can capture deeper meaning and the relationships between words.
That’s what Attention does — it helps the model look at the right words in context, instead of treating everything equally.
4. The Transformer: The Big Picture
A Transformer has two main parts:
- Encoder — reads the input and builds a rich representation.
- Decoder — generates the output step by step, using both the encoded input and what it has produced so far.
Large Language Models (LLMs) like GPT mostly use the decoder part, since their job is to generate sequences (text, code, etc.).
5. Key Ingredients of a Transformer
Now, let’s take a closer look at the Transformer architecture and break it down into smaller parts using simple analogies.
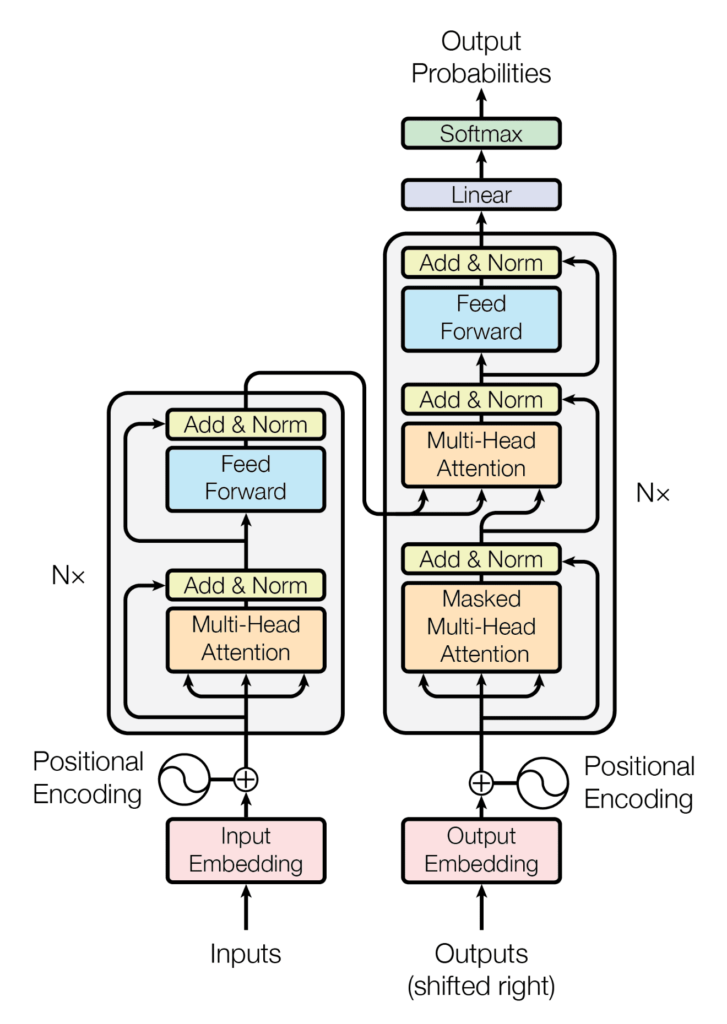
Taken from “Attention Is All You Need“
5.1. Multi-Head Attention
Imagine a group of friends reading the same sentence:
- One pays attention to the subject (who is doing the action).
- Another looks at the verb (what action is happening).
- Another focuses on the object (who or what is affected).
When they combine their views, they understand the sentence much better than if only one person read it.

That’s what Multi-Head Attention does — it looks at the text from many perspectives at once.
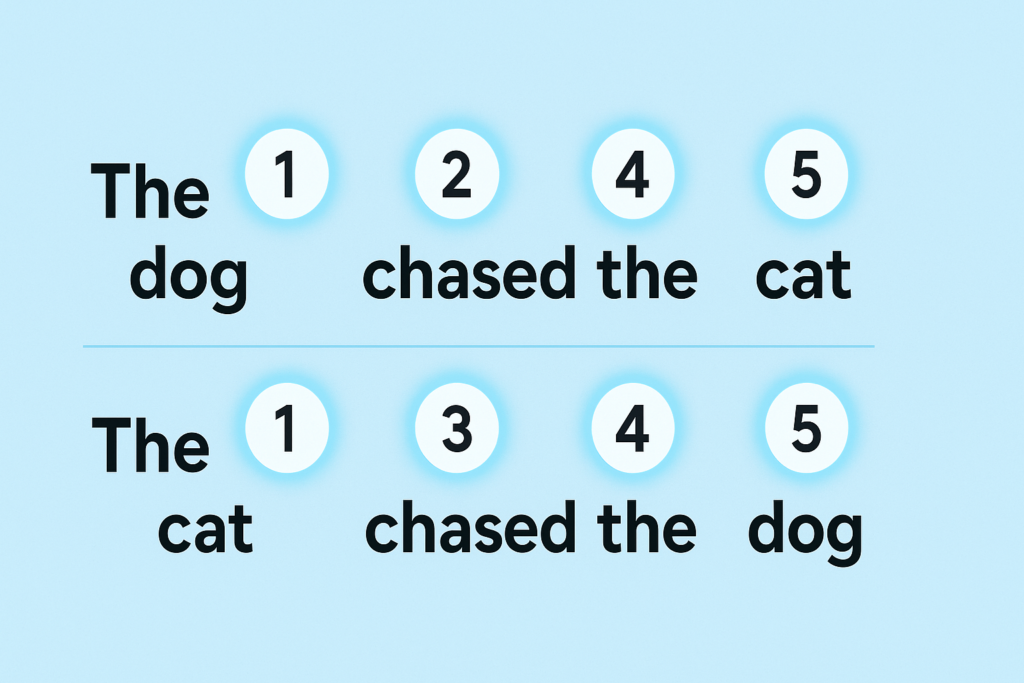
5.2. Positional Encoding
Transformers read all the words in a sentence at the same time. But word order matters:
“The dog chased the cat.”
Is not the same as:
“The cat chased the dog.”
Positional Encoding acts like giving each word a “timestamp” or a page number, so the model knows who came first, second, third, etc.
5.3. Feed-Forward Layers
After Attention decides which words are important, the model still needs to process that information further. Think of it like taking rough notes and then turning them into a polished summary.

That’s what the Feed-Forward Layers do — they refine the information before passing it on.
5.4. Add & Norm (Residual Connections + Normalization)
Training deep networks is tricky — sometimes the signal gets weaker as it flows through many layers.
To fix this, Transformers add two helpers:
- Residual connections: Like a shortcut that lets information skip ahead to the next step.
- Normalization: Like keeping the “volume” of signals at a comfortable level so nothing blows up or fades away.
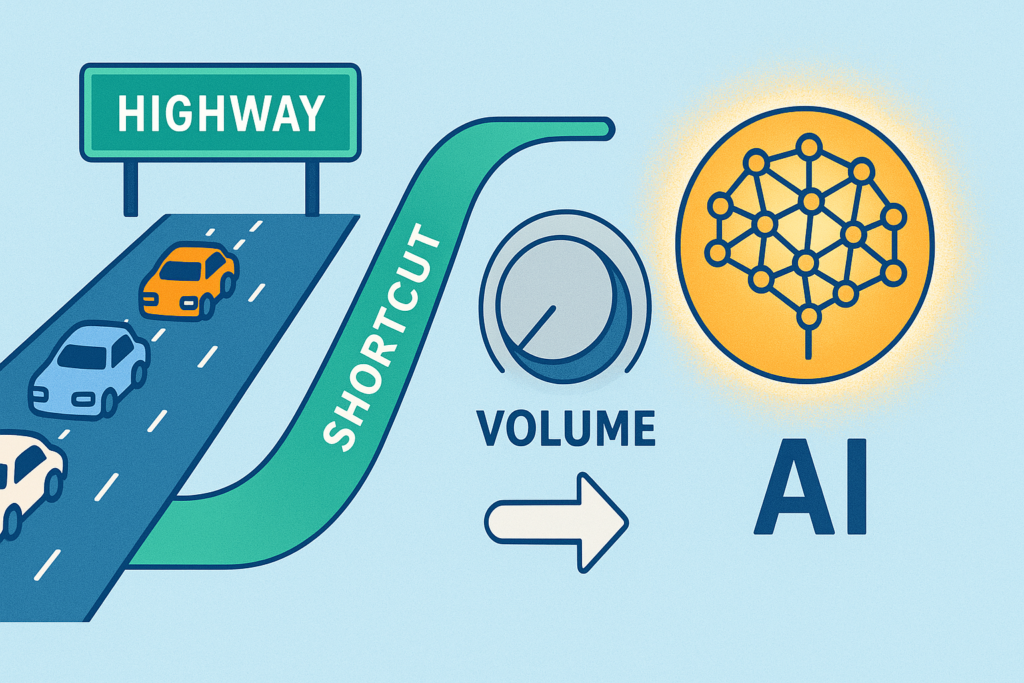
Together, they make the model much more stable and easier to train.
6. Why It Changed Everything
The Transformer was a game-changer because:
- Faster training → No more slow word-by-word reading; GPUs could train on massive datasets in parallel.
- Better memory → It can connect ideas across long distances in text.
- Scales beautifully → The bigger you make it, the better it performs.
In short, instead of stumbling through text step by step, models could suddenly see the whole picture, learn faster, and grow more powerful as we scaled them up.
That’s why today’s LLMs — GPT-4, Claude, Gemini — are all built on Transformers.

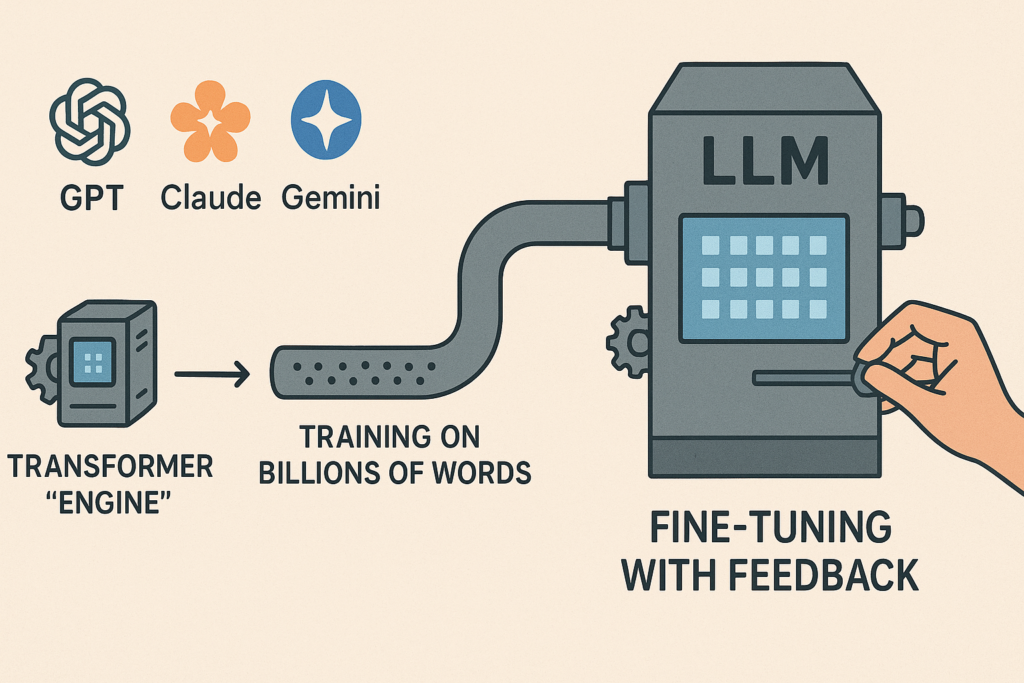
7. From Transformers to LLMs
When you train a Transformer on billions of words, you get a Large Language Model (LLM).
Then you fine-tune it with methods like RLHF (Reinforcement Learning with Human Feedback) to make it more helpful, safer, and aligned with human instructions.
In other words: Transformers are the engine, and fine-tuning is how we turn that raw power into something useful for real users.
8. What’s Next
Transformers turned AI from an academic idea into a foundation for real products. Without them, there would be no ChatGPT, no Copilot, no modern Generative AI.
In Part 4, we’ll dive into how LLMs are trained on massive datasets, how fine-tuning shapes their behavior, and why two models with the same architecture can act so differently. This is where things get really interesting.