



Generative AI – Part 4: How LLMs Are Trained and Fine-Tuned
In Part 3, we looked at Transformers — the core engine behind today’s AI models.
But an engine alone isn’t enough. How do we turn that into something like GPT-4 or Claude that can actually answer our questions?
This is where the training pipeline comes in. Think of it as the step-by-step process that transforms a raw neural network into a helpful assistant.
1. Pretraining
At the beginning, the model knows nothing. It’s just a giant pile of random numbers (weights). Pretraining is about showing it huge amounts of text (and sometimes code) so it can learn the patterns of language.
The idea is simple:
- Give the model part of a sentence:
“The quick brown fox jumps over the …” - Ask it to guess the next word.
- Compare its guess with the correct answer (“lazy”).
- Adjust the weights.
- Repeat billions or even trillions of times.

This is called next-token prediction. After pretraining, the model has learned:
- Grammar and vocabulary.
- Facts, like “Paris is the capital of France.”
- Relationships between concepts.
- Programming syntax and patterns (if trained on code).
By now, it can write fluent text — but it doesn’t know how to be helpful.
It’s like someone who has read the entire internet but doesn’t know how to answer a question politely.
2. Supervised Fine-Tuning
After pretraining, the model can write sentences, but it doesn’t really know how to answer your question. It’s like talking to someone who has read a million books, but when you ask, “How do I reverse a string in Python?”, they might just start reciting random programming facts.
To fix this, humans step in. Annotators create pairs of prompts and good answers:
- Prompt: “Write a Python function to reverse a string.”
- Good Answer: short, correct, and easy-to-read code.

By training on thousands of these examples, the model learns how to:
- Focus on the user’s request.
- Give answers that are structured and useful.
- Skip unnecessary rambling.
In short, fine-tuning is like teaching a well-read person to be a practical assistant: not just showing off what they know, but actually solving the task you gave them.
3. Reinforcement Learning from Human Feedback
Even after supervised fine-tuning, the model can still feel robotic. It might give you an answer that’s technically correct but a bit dry, unhelpful, or awkward. This is where RLHF (Reinforcement Learning from Human Feedback) comes in.
Here’s the idea:
- The model generates several different answers to the same prompt.
- Humans rank these answers from best to worst.
- A separate “reward model” learns to predict which answers humans prefer.
- The main model is then adjusted to produce responses that score higher on this human preference scale.
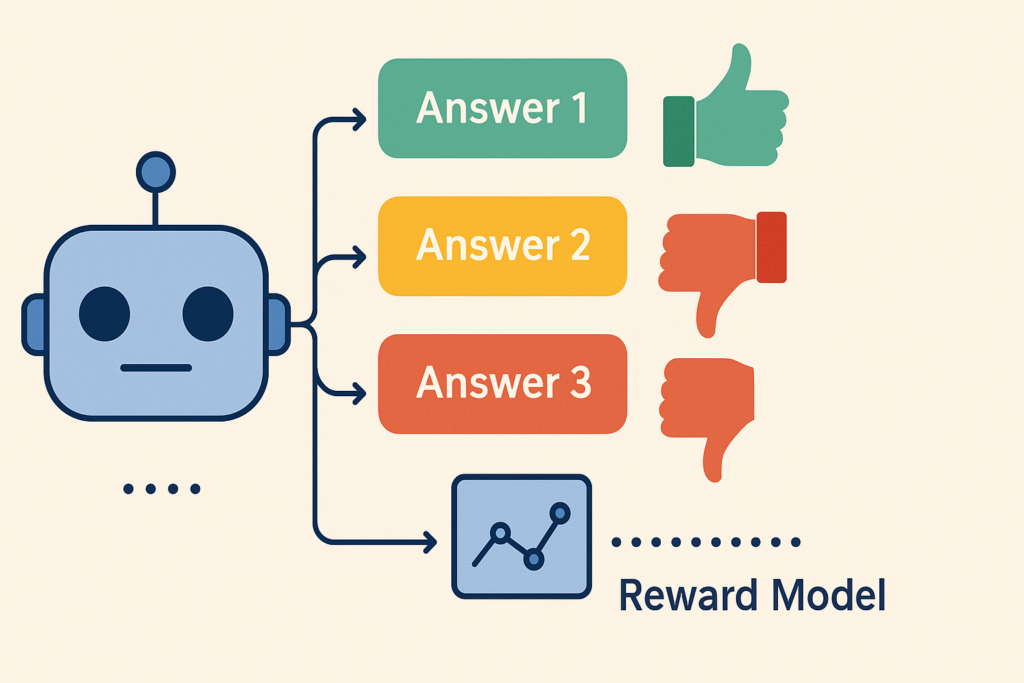
Think of it like this:
The model is a student who already knows the facts. RLHF is the teacher saying, “This explanation is clearer. That one is confusing. Next time, do it more like this.”
Or in developer terms: imagine the model suggests three different code snippets. All of them work, but one is cleaner, easier to read, and follows best practices. Humans pick that one, and the model learns to prefer that style in the future.
That’s why models like ChatGPT don’t just give you a correct answer — they try to give you the answer you’ll find most helpful, natural, and safe.
4. Post-Training Improvements
After RLHF, companies often add extra layers:
- Instruction tuning → Training on a wide mix of Q&A and reasoning tasks.
- Safety filters → Blocking or rewriting unsafe outputs.
- Tool integration → Teaching the model to call APIs, run code, or fetch external data.
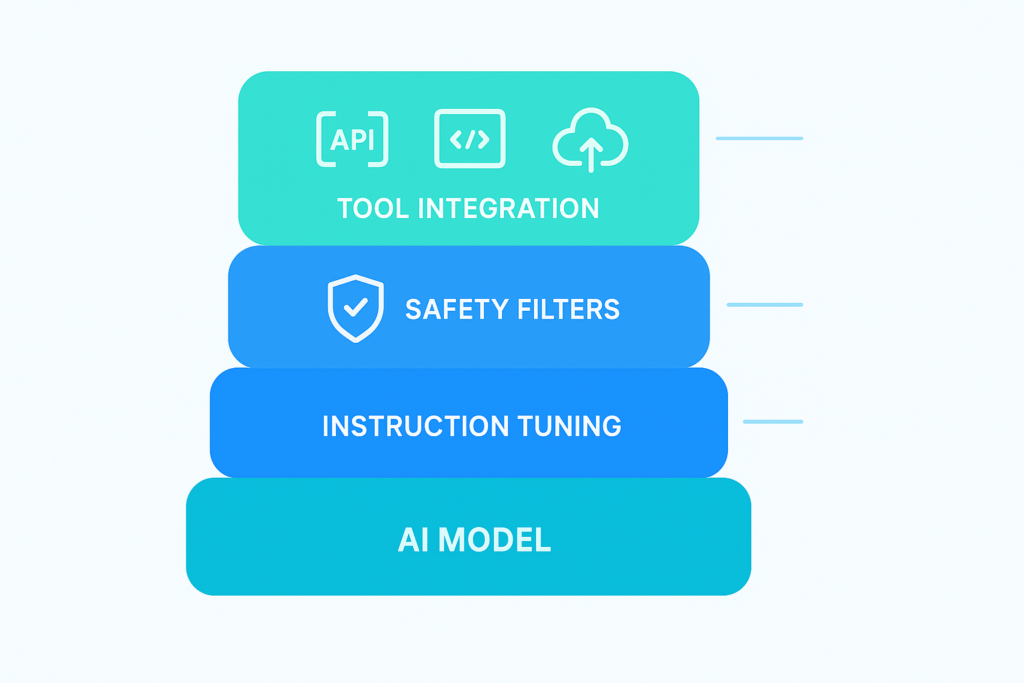
This is why two Transformer-based models can behave very differently.
The difference isn’t just the architecture — it’s also the training data and tuning steps applied after.
5. A Developer’s Takeaway
For developers, this pipeline explains a lot:
- Fine-tuning beats building from scratch. You don’t need to train a model on the entire internet. Starting from a pretrained model saves time and money.
- Training explains prompt behavior. Some prompts work better because they align with how the model was tuned.
- Know the limits. Models don’t “know” everything. If something wasn’t in the training data, the model might hallucinate.
- Practical tip: If you want to adapt a model for your project, start small — try fine-tuning with LoRA (Low-Rank Adaptation) or parameter-efficient methods instead of retraining everything.
6. Wrapping Up
And that wraps up our series. We started from the basics of neural networks, explored Transformers, and walked through the training pipeline that turns raw models into helpful assistants like GPT-4. AI is still evolving fast, but if you understand these foundations, you’ll have a clear lens to follow — and maybe even build on — the next big steps.