




Introduction
In the world of distributed systems and decentralized applications, InterPlanetary File System (IPFS) has emerged as a powerful solution for decentralized storage. IPFS provides a peer-to-peer network for sharing and storing files, routing, addressing, transferring data in a decentralized file system making it an attractive option for developers who want to build efficient applications. In this blog post, we’ll explore IPFS by diving into its architecture, key concepts, and practical implementation.
What is IPFS?
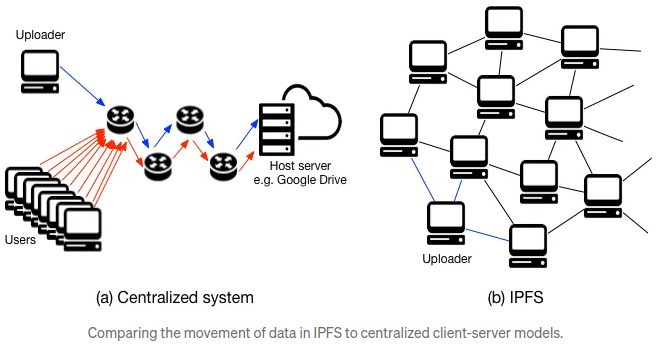
IPFS is a peer-to-peer hypermedia protocol that aims to create a global, distributed file system. Unlike traditional web protocols (such as HTTP), IPFS doesn’t rely on centralized servers. Instead, it leverages a decentralized network of nodes to store and retrieve files. Each file in IPFS is identified by its content hash, which ensures data integrity and allows for efficient caching.
How IPFS Works?
The three key responsibilities of the IPFS subsystems are:
- Representing and addressing data
- Routing data
- Transferring data
Content Addressing
In IPFS, files are addressed by their cryptographic hash (content hash) rather than their location. When you add a file to IPFS, it generates a unique hash based on the file’s content. This hash becomes the file’s address on the network.
Distributed Hash Tables (DHT)
IPFS uses a DHT to store information about which nodes have which files. The DHT ensures efficient lookup and retrieval of files across the network. Nodes participate in the DHT by storing and sharing information about the files they have.
Bitswap (for content routing)
IPFS nodes use Bitswap, a message-based, peer-to-peer network protocol for the transfer of data, that is also used for routing data.
Data Sharing using IPFS

The above diagrammatic representation can be concluded as follows:
- Put the file in IPFS: The data you want to share is uploaded to the IPFS network.
- IPFS returns a file hash: Once uploaded, a unique cryptographic hash, called a Content Identifier (CID), is generated for the file. This CID acts like a fingerprint for the data and is used to retrieve it later.
- Query the smart contract for the public key of worker: The process interacts with a smart contract, a program stored on a blockchain that facilitates transactions. The smart contract provides a public key, likely belonging to a worker node that will participate in the following steps.
- Split the file into n shares and randomly choose keys for encryption: The data is split up into multiple encrypted shares. Each share is encrypted with a different key.
- Store the encrypted shares on blockchain: The encrypted shares are then stored on the blockchain, a distributed public ledger.
Subsytems & Components
Content Identifiers (CIDs)
A CID is a label used to point to material in IPFS. It doesn’t indicate where the content is stored, but it forms a kind of address based on the content itself. CIDs are short, regardless of the size of their underlying content. Any difference in the content will produce a different CID.
Distributed Hash Tables (DHT)
A DHT is a distributed system for mapping keys to values. In IPFS, the DHT is used as the fundamental component of the content routing system and acts like a cross between a catalog and a navigation system. It maps what the user is looking for to the peer that is storing the matching content.
Bitswap
Bitswap is a core module of IPFS for exchanging blocks of data. It directs the requesting and sending of blocks to and from other peers in the network. Bitswap is a message-based protocol where all messages contain want-lists or blocks.
IPFS Gateway
An IPFS gateway is a web-based service that gets content from an IPFS network (private, or the public swarm backed by Amino DHT), and makes it available via HTTP, allowing IPFS-incompatible browsers, tools and software to benefit from content-addressing (opens new window).
HTTP vs IPFS: Understand the Difference
-
Structure:
- HTTP: Employs a client-server model. Your web browser (client) initiates a request to a specific server location for a webpage or file. The server retrieves the data and sends it back to your browser.
- IPFS: Utilizes a decentralized peer-to-peer (P2P) network. There are no central servers. When you request data, the network locates nodes that hold copies of the data and retrieves it from them.
-
Data Storage:
- HTTP: Data is stored on the server hosting the website or application. If the server goes down or the content is removed, it becomes inaccessible.
- IPFS: Leverages a content-addressed storage system. Data is assigned a unique cryptographic hash based on its content. Nodes in the network store copies of the data based on this hash. This means if you request data with a specific hash, any node holding a copy can deliver it.
-
Addressing:
- HTTP: Relies on URLs to specify the location of data. A URL points to a specific server and file path.
- IPFS: Utilizes cryptographic hashes to identify data. The hash is a unique identifier derived from the content itself. This ensures that as long as the data remains the same, the same hash will always point to it, regardless of its location on the network.
-
Performance:
- HTTP: Performance can be bottlenecked by server capacity and network bandwidth. If many users access a popular website simultaneously, the server may struggle to keep up.
- IPFS: Offers improved performance. By distributing data across the network, retrieval can potentially be faster as content can be served from the nearest node with a copy.
-
Security:
- HTTP: Can be secured with encryption protocols like HTTPS, which manipulates data during transmission.
- IPFS: Encryption protocols like IPFS with TLS can be used to secure communication within the network.
Advantages & Use Cases
Advantages of IPFS
- Distributed data storage: Unlike centralized storage where data resides on specific servers, IPFS distributes data across a network of computers. This makes it resistant to data loss because if one node goes down, others can still provide the data.
- Enhanced data accessibility: Since data is replicated across multiple devices on the network, it’s more likely to be available even if some nodes are unavailable.
- Efficient data transfer: IPFS utilizes a content-addressed system, where data is retrieved based on a unique fingerprint called a Content Identifier (CID) instead of its location.
- Faster content delivery: By retrieving content from the closest node in the network, IPFS has the potential to deliver content faster, particularly for users spread out geographically.
- Data integrity: The cryptographic hash function ensures data integrity. Any modification to the data would result in a different hash, signaling a tamper.
Use Cases of IPFS
- Decentralized website hosting: Websites can be hosted on IPFS, offering a more decentralized alternative to traditional hosting services.
- Data archiving for long-term preservation: IPFS can be used to archive data for the long term, ensuring its accessibility even if the original source becomes unavailable.
- Building resilient and efficient Content Delivery Networks (CDNs): IPFS can be leveraged to build CDNs that are more robust and efficient than traditional CDNs.
- Sharing large files more efficiently: IPFS can facilitate sharing large files more efficiently by breaking the data down into smaller chunks and distributing them across the network.
Challenges
Limited Availability
The current version of IPFS doesn’t promise that data will always be available when requested. One way to ensure availability is by content pinning, which involves keeping copies of published content on an IPFS node all the time. This node needs to stay online continuously to make sure the data is always accessible.
Higher Bandwidth Requirement
Operating an IPFS node requires a high bandwidth, which might be impractical for various users. The extensive utilization of bandwidth could hinder the acceptance of IPFS globally. Despite multiple proposals for mitigating this issue, there is no outcome. However, gaining financial rewards for hosting content on IPFS can compensate the costs of running nodes.
Conclusion
IPFS revolutionizes data storage and distribution by embracing decentralization. As developers, we benefit from content addressing, ensuring data integrity through content hashes. IPFS finds applications in decentralized websites, peer-to-peer file sharing, and data persistence. Challenges include managing large-scale networks and handling dynamic content. By incorporating IPFS into our toolkit, we empower ourselves to build censorship-resistant applications in a decentralized world.
References
- Official IPFS Documentation – https://docs.ipfs.tech/
- Medium Article – https://medium.com/zkcapital/ipfs-the-distributed-web-e21a5496d32d