



In the age of Big Data, handling and processing large volumes of information efficiently has become essential. Organizations today generate terabytes of data daily, and traditional data processing tools often fall short of managing this vast amount of information in real-time. This is where Apache Spark comes into the picture. Spark has revolutionized the world of Big Data processing with its speed, scalability, and versatility.
In this blog, we’ll take a closer look at what Apache Spark is, its key features, and why it matters in modern data processing.
What is Apache Spark?
Apache Spark is an open-source distributed computing system that processes large datasets quickly. Initially developed at UC Berkeley’s AMPLab, it has become one of the most popular Big Data frameworks, particularly for its speed, ease of use, and support for multiple programming languages. Spark can handle both batch and real-time data processing, making it incredibly versatile for different data processing needs.
Spark is built on the idea of resilient distributed datasets(RDDs), which allow it to process large-scale data efficiently across a cluster of computers. This distributed architecture is at the heart of Spark’s ability to scale and process petabytes of data in parallel.
Significance of Apache Spark
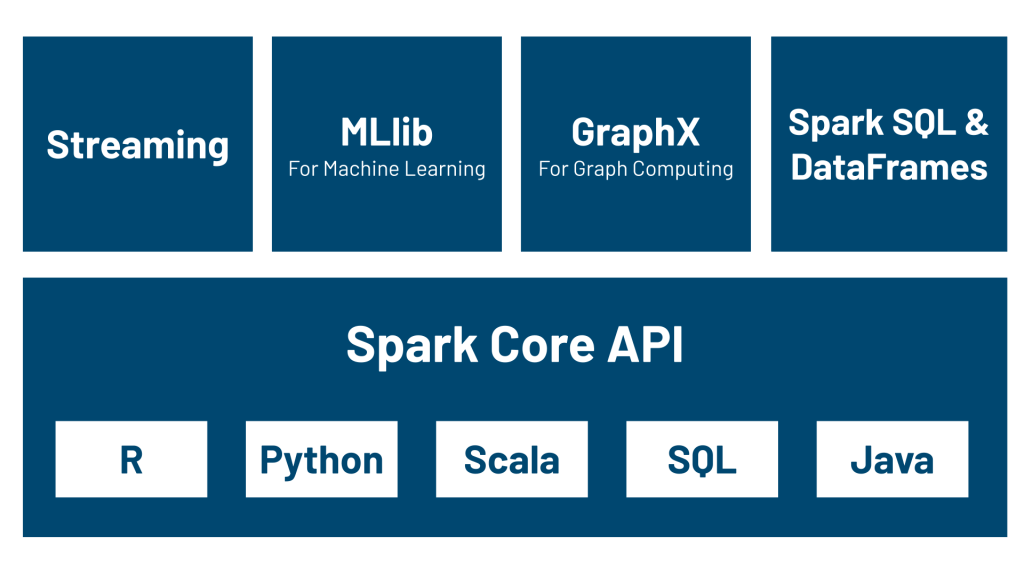
Apache Spark has quickly become one of the most popular big data processing frameworks in the world. Its significance lies in its ability to handle large datasets with speed, flexibility, and ease of use. Let’s dive into some of the reasons why Spark has gained such widespread adoption:
List of Significance
- Speed and Performace: One of the most prominent advantages of Apache Spark is its speed. In-memory computing, which Spark uses to accomplish this, keeps data in memory (RAM) during processing instead of writing to and reading from disc like traditional Hadoop MapReduce does. As a result, complicated data operations take a lot less time, and Spark can frequently do some jobs up to 100 times quicker than Hadoop.
- Unified Framework for various Workloads:
Spark provides a unified platform for diverse workloads such as:
* Batch processing (similar to Hadoop)
* Stream processing for real-time data using Spark Streaming
* Machine learning with MLlib
* Graph processing with GraphX
* SQL-based querying via Spark SQL - Ease of Use: Apache Spark provides simple APIs in various languages like Python, Scala, Java. This makes I accessible for a wide range of developers and data scientists, as they can use their preferred language. The extensive documentation and large community of users also contribute to its ease of use.
- Support for Big Data: Big data frameworks must be scalable, and Apache Spark excels in this aspect. It is designed to handle data in clusters, making it highly scalable. Whether you’re working on a local machine or a large distributed cluster, Spark can efficiently process terabytes of data.
Spark is integrated with Hadoop’s HDFS and other cloud-based storage systems like Amazon S3, making it compatible with big data storage solutions. - Stream Processing for Real-Time Analytics: In today’s fast-paced world, real-time data processing is essential. Spark offers a real-time stream processing engine via Spark Streaming. This feature enables the analysis of data streams in near real-time, making it suitable for applications like fraud detection, real-time advertising, and monitoring systems.
Apache Spark’s Architecture
Understanding Spark’s architecture is crucial to understanding how it works. Spark operates on a master-slave architecture, where:
- Driver Program (Master): The driver is responsible for the overall job execution. It runs on the master node of the cluster, where it distributes tasks across worker nodes and manages the execution process.
- Cluster Manager: The cluster manager assigns resources to applications, managing the distribution and execution of tasks. Spark can work with different cluster managers like YARN, Mesos, or its own Standalone cluster manager.
- Executor (Workers): Executors run on the worker nodes, where the actual computation happens. Each executor is responsible for running the tasks that make up a spark job.
The core of Spark’s architecture is the concept of Resilient Distributed Datasets (RDDs), which is a distributed collection of data across nodes. RDDs can be cached in memory and rebuilt automatically in case of failures, making Spark fault-tolerant and efficient.
Real-World Use Cases of Apache Spark
Apache Spark has found widespread use across various industries, from tech giants to startups, for processing large datasets. Some examples include:
- Real-Time Analytics for E-Commerce: E-commerce companies use Spark for real-time analytics to recommend products to customers based on browsing and purchase history. Spark’s ability to process live data helps deliver personalized recommendations and promotions in real-time.
- Fraud Detection in Finance: Financial institutions use SPark for fraud detection, analyzing transaction patterns to identify suspicious activity in real-time. Spark Streaming enables them to detect and respond to anomalies quickly.
- Social Media Analytics: Platforms like Twitter and Facebook process huge amounts of data every second. Spark helps them analyze this data for friends, user sentiment, and engagement patterns, driving decisions in content recommendation and advertising.
- Genomics: Healthcare and genomics researchers use Spark to process large sets of biological data, accelerating research and developing new treatments.
Conclusion
Apache Spark has revolutionized the way organizations handle large-scale data. Its flexibility, speed, and unified analytics engine make it a powerful tool for diverse data processing needs. Whether you’re dealing with real-time streams, running machine learning algorithms, or managing large-scale batch processing jobs, Spark offers a solution that is fast, scalable, and easy to work with.
In an era where data drives decision-making and innovation, Apache Spark plays a crucial role in processing big data. It is a must-have technology for businesses aiming to harness the power of their data effectively.
For blogs related to rust click here and for more tech related blogs please visit Nashtech Blogs.
Would you mind sharing any Spark-related advice with the community? Then leave a comment with your response.