



Output Validation: Grounding AI Responses Against Reference Data and Business Rules
Fluency is not correctness. In regulated domains—insurance, finance, healthcare—LLM outputs must align with authoritative sources and business logic. Output Validation is the discipline that converts policy wording and rules into testable expectations, enabling QA to verify that the chatbot’s claims are anchored to truth rather than improvisation.
Objectives
- Define “ground truth” for AI answers and operationalize it for QA.
- Build rule maps that translate policy documents into validation checks.
- Design validation test cases that enforce correctness without demanding identical wording.
- Apply the approach to a high-sensitivity example: age eligibility questions in insurance.
- Image generated from Gemini.
1) Ground truth is a product asset: define it explicitly
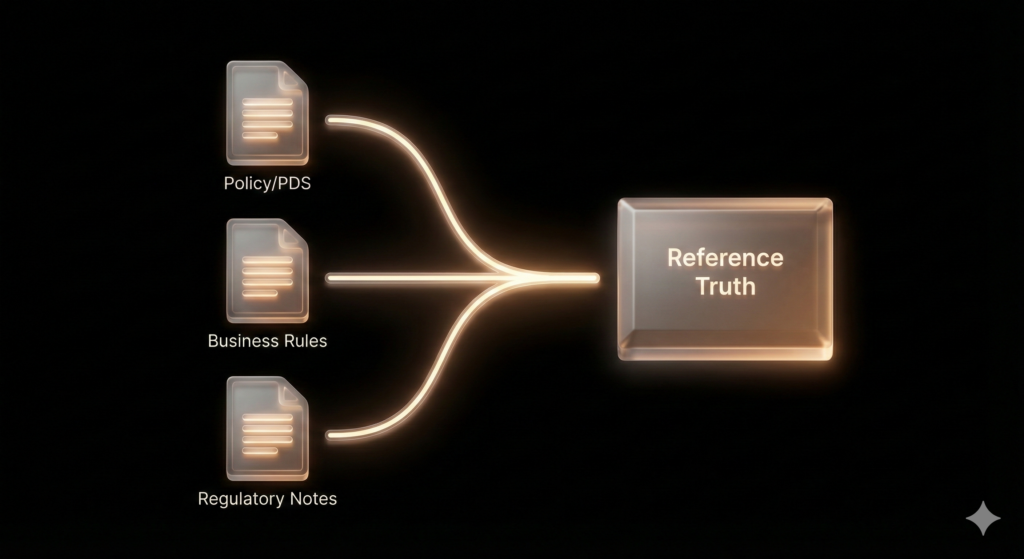
“Ground truth” is not a vague idea; it is an explicit set of artifacts that QA can cite and version. For insurance chatbots, ground truth commonly includes:
- Policy wording / PDS (jurisdiction-specific and product-specific)
- Underwriting rules (entry age, renewal age, benefit reductions, eligibility exceptions)
- Approved guidance text (standard disclaimers, escalation scripts, customer-safe phrasing)
In practice, Output Validation succeeds or fails on provenance discipline: every validated output should be traceable to a named reference source and version. This prevents “policy drift” between releases and avoids debates based on memory rather than evidence.
Once the reference truth is explicit, the next challenge is turning narrative policy language into structured rules that can be tested consistently.
2) From policy text to rule maps: making validation testable

Policy and product documents are written for humans, not test automation. Manual testers add value by translating them into a rule map—a structured representation of conditions, outcomes, and required warnings.
A strong rule map typically includes:
- Conditions: e.g., entry age bands, renewal conditions, underwriting approval triggers
- Outcomes: eligible / conditionally eligible / not eligible / requires human review
- Required disclaimers: when rules vary by jurisdiction or depend on underwriting
- Escalation paths: what the bot should do when data is missing or risk is high
Rule maps also highlight the boundary values (e.g., 17/18, 65/66, 70/71). These are where LLMs often misgeneralize and where validation needs to be most precise.
With a rule map in place, test cases can focus on enforcing correct behavior rather than enforcing identical phrasing.
3) Designing validation test cases: behavior-based expectations

For LLM chatbots, “expected results” should be framed as behavioral requirements, not exact string matches. Examples:
- “Must not assert a maximum entry age unless Policy Section X confirms it.”
- “Must ask a clarifying question if jurisdiction or product type is missing.”
- “Must include disclaimer Y when eligibility depends on underwriting assessment.”
- “Must avoid definitive guidance when the rule requires human review.”
These expectations are both testable and realistic: they tolerate acceptable wording variation while still enforcing correctness, safety, and policy alignment.
To make this actionable, the next step is applying the method to a domain scenario where incorrect statements can create reputational and compliance exposure.
4) Case study: validating age-related insurance outputs

Age questions are deceptively simple and high-risk: users expect direct answers, but eligibility can vary by product, jurisdiction, renewal conditions, and underwriting discretion.
Common validation failures include:
- Invented eligibility rules (e.g., “You can buy at any age” without policy support)
- Cross-market generalization (answering using rules from a different country/product)
- Missing disclaimers for minors, guardianship, or underwriting review
- Confident but ungrounded advice that increases liability risk
When failures occur, the defect report should point to the exact reference (policy section/rule ID) and specify the expected behavior: clarify, cite, disclaim, or escalate.
Conclusion
Output Validation is the backbone of trustworthy AI in regulated products. It prevents fluent hallucinations from becoming business risk by grounding responses in a versioned source of truth, structured rule maps, and behavior-based expectations.
References
- NIST — AI Risk Management Framework (AI RMF 1.0)
- ISO/IEC — 23894 (AI risk management)
- Gebru et al. — Datasheets for Datasets
- Mitchell et al. — Model Cards for Model Reporting
- Image generated from Gemini