



Introduction
In the dynamic realm of machine learning, efficient management of experiments, models, and deployments is paramount. MLflow stands out as a transformative tool, providing a comprehensive platform to streamline the experiment tracking of machine learning lifecycle.
From experimentation to deployment, MLflow offers a unified interface, empowering data scientists and engineers to expedite development and collaboration. This blog delves into the core concepts of MLflow, its key components, and how it revolutionizes the machine learning workflow.
Understanding MLflow
MLflow, an open-source platform developed by Databricks, addresses the complexities of managing machine learning projects. It fosters reproducibility, collaboration, and deployment, thereby enhancing productivity across teams. At its core, MLflow encompasses four key components for experiment tracking.
Projects
MLflow Projects offers a standardized format for packaging and sharing code, dependencies, and environments. By defining projects as directories containing code, data, and an ML-Project file.
Users can effortlessly reproduce experiments across different environments, ensuring consistency and reproducibility.
Models
MLflow Models simplifies the model deployment process by providing a consistent interface for packaging, managing, and serving models. Whether deploying models as REST APIs, Docker containers, or batch inference jobs.
Models streamlines the deployment pipeline, enabling seamless integration with existing infrastructure.
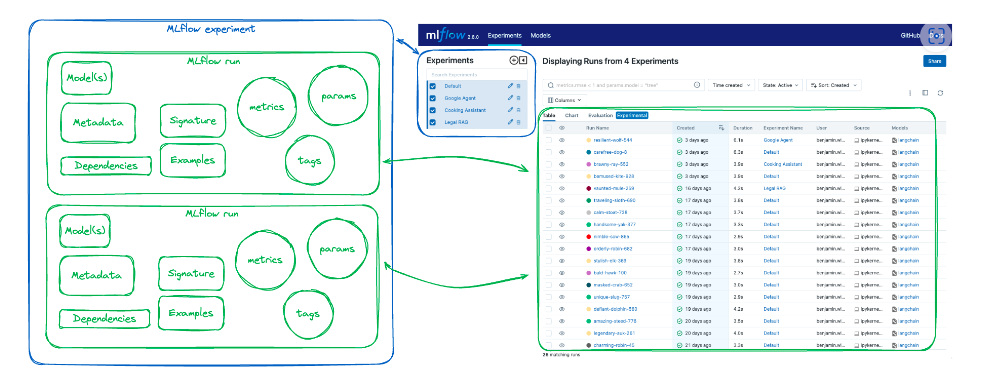
Tracking
MLflow Tracking facilitates logging and organizing experiments, enabling users to track parameters, metrics, and artifacts. Seamlessly integrated into popular libraries like TensorFlow, PyTorch, and scikit-learn.
Tracking provides a centralized repository for experiment results, facilitating comparison and analysis.
Registry
MLflow Registry serves as a collaborative hub for managing model versions, promoting model governance and collaboration. By versioning models, tracking lineage, and enforcing access controls.
Registry facilitates collaboration among data scientists, engineers, and stakeholders, ensuring transparency and reproducibility.
Implementation
Let’s explore how we can effectively utilize the MLflow wrappers or classes to log the previously mentioned data, examining each example step by step.
pip install mlflow
LOG RESOURCE UTILISATION
Monitoring system resource utilization is crucial for understanding system effectiveness, optimizing performance, troubleshooting problems, and ensuring reliability.
os.environ["MLFLOW_ENABLE_SYSTEM_METRICS_LOGGING"] = "true"
START TRACKING SERVER
A tracking server in MLflow acts as a centralized repository for storing and managing machine learning experiments, enabling easy tracking of parameters, metrics, and artifacts for enhanced collaboration and reproducibility.
mlflow server --host 127.0.0.1 --port 8080
SET TRACKING SERVER URI
A tracking server in MLflow acts as a centralized repository for storing and managing machine learning experiments, enabling easy tracking of parameters, metrics, and artifacts for enhanced collaboration and reproducibility.
import mlflow
mlflow.set_tracking_uri(uri="http://:")
LOGGING MODEL AND ITS METADATA
Model registering in MLflow is the process of officially logging and versioning trained machine learning models into a central repository, facilitating seamless collaboration, version control, and reproducibility throughout the model’s lifecycle.
import mlflow
from mlflow.models import infer_signature
import pandas as pd
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# Load the Iris dataset
X, y = datasets.load_iris(return_X_y=True)
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# Define the model hyperparameters
params = {
"solver": "lbfgs",
"max_iter": 1000,
"multi_class": "auto",
"random_state": 8888,
}
# Train the model
lr = LogisticRegression(**params)
lr.fit(X_train, y_train)
# Predict on the test set
y_pred = lr.predict(X_test)
# Calculate metrics
accuracy = accuracy_score(y_test, y_pred)
# Set our tracking server uri for logging
mlflow.set_tracking_uri(uri="http://127.0.0.1:8080")
# Create a new MLflow Experiment
mlflow.set_experiment("MLflow Quickstart")
# Start an MLflow run
with mlflow.start_run():
# Log the hyperparameters
mlflow.log_params(params)
# Log the loss metric
mlflow.log_metric("accuracy", accuracy)
# Set a tag that we can use to remind ourselves what this run was for
mlflow.set_tag("Training Info", "Basic LR model for iris data")
# Infer the model signature
signature = infer_signature(X_train, lr.predict(X_train))
# Log the model
model_info = mlflow.sklearn.log_model(
sk_model=lr,
artifact_path="iris_model",
signature=signature,
input_example=X_train,
registered_model_name="tracking-quickstart",
)
FUNCTION FOR MODEL INFERENCE
A function for model inference refers to a piece of code or algorithm used to make predictions or draw conclusions from a trained machine learning model. This function takes input data and applies the model’s learned parameters to generate output, enabling the model to be used for practical applications such as classification, regression, or other tasks.
# Load the model back for predictions as a generic Python Function model
loaded_model = mlflow.pyfunc.load_model(model_info.model_uri)
predictions = loaded_model.predict(X_test)
iris_feature_names = datasets.load_iris().feature_names
result = pd.DataFrame(X_test, columns=iris_feature_names)
result["actual_class"] = y_test
result["predicted_class"] = predictions
result[:4]
Advantages of MLflow
Improved Experimentation- MLflow Tracking empowers data scientists to conduct experiments systematically, capturing parameters, metrics, and artifacts. By providing a centralized dashboard for tracking experiments, teams can gain insights into model performance and iterate rapidly.
Enhanced Reproducibility- With MLflow Projects, reproducing experiments becomes effortless, thanks to its standardized project format. By encapsulating code, dependencies, and environments, teams can ensure reproducibility across different platforms and environments, mitigating potential discrepancies.
Facilitated Collaboration- MLflow Registry serves as a collaborative platform for managing model versions, promoting collaboration and governance. By versioning models, tracking lineage, and enforcing access controls, Registry fosters collaboration among data scientists, engineers, and stakeholders, facilitating knowledge sharing and decision-making.
Conclusion
In conclusion, MLflow emerges as a powerful platform for managing the machine learning lifecycle, from experimentation to deployment. By offering a unified interface for tracking experiments, packaging projects, managing models, and collaborating effectively.
MLflow enhances productivity and accelerates innovation across teams and organizations. As the field of machine learning continues to evolve, MLflow remains at the forefront, empowering practitioners to unleash the full potential of AI technologies.