


Key takeaways
Graph-Augmented Retrieval
LightRAG enhances traditional RAG by integrating a knowledge graph (entities + relations) with vector search, enabling multi-hop reasoning and relational awareness.
Dual-Level Retrieval
Supports local (precise entity-based) and global (context-rich, multi-hop) retrieval modes for flexible question handling.
Efficiency & Simplicity
Compared to heavy GraphRAG implementations, LightRAG offers faster query performance and lower operational complexity, making it practical for real-world deployments.
Incremental Updates
Allows easy addition of new data without full re-indexing, reducing maintenance overhead.
Rich Ecosystem
Ships with a web UI, multiple storage backends, citation support, and multimodal ingestion—ideal for teams seeking quick adoption.
What is LightRAG?
LightRAG is an open-source framework proposed by researchers at the University of Hong Kong and collaborators. It integrates graph structures with vector representations to extract entities and relations, build a knowledge graph (KG), and perform dual-level retrieval (local + global) before generation. In experiments, the authors report improved retrieval accuracy and efficiency versus baseline RAG approaches.
Why graph-augmented RAG matters
Multiple surveys and recent work on GraphRAG point out that graphs capture relational knowledge (nodes + edges) that conventional chunk/embedding pipelines miss. This enables better retrieval for networked or relational data (e.g., regulations linking entities, technical systems with dependencies, or research corpora with cross-citations)
LightRAG adopts that insight, but emphasizes simplicity and speed: its indexing prompts generate entities/relations and profile them into key–value pairs, then its retrieval combines vector search with graph-guided neighborhood collection, producing context that’s both semantically relevant and structurally coherent
Architecture
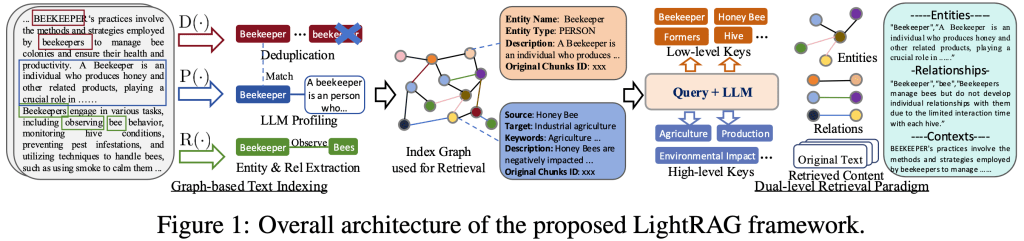
Source: LightRAG
Document segmentation & entity/relation extraction
Text is split into manageable chunks. LLM prompts identify entities (people, orgs, concepts, dates, etc.) and relations (edges) between them. These become nodes/edges in a knowledge graph. [lightrag.github.io]
LLM profiling → key–value pairs
Each node/edge is “profiled” by an LLM into compact descriptors (keys + summaries), which are stored alongside embeddings in the index. This helps both exact and approximate matching.
Dual-level retrieval
- Local (low-level) retrieval targets specific entities/relations (good for factual queries).
- Global (high-level) retrieval expands to multi-hop neighbors and thematic keys (good for broader or exploratory questions).
Both are fused with vector similarity and graph traversal to assemble a high-quality context bundle for the LLM. [lightrag.github.io]
Generation with grounded context
Retrieved snippets (from vector hits + graph neighborhoods) are concatenated with the prompt so the LLM can answer with richer, connected evidence
LightRAG vs. Microsoft GraphRAG (at a glance)
Microsoft’s GraphRAG popularized graph-guided retrieval with community detection and hierarchical summarization; it’s powerful for global summarization and static corpora but can be costly at query time whe
LightRAG keeps retrieval lighter—it leans on vector stores plus targeted neighborhood expansion instead of heavy global summarization, which practitioners report as more cost-efficient and faster for many workloads.
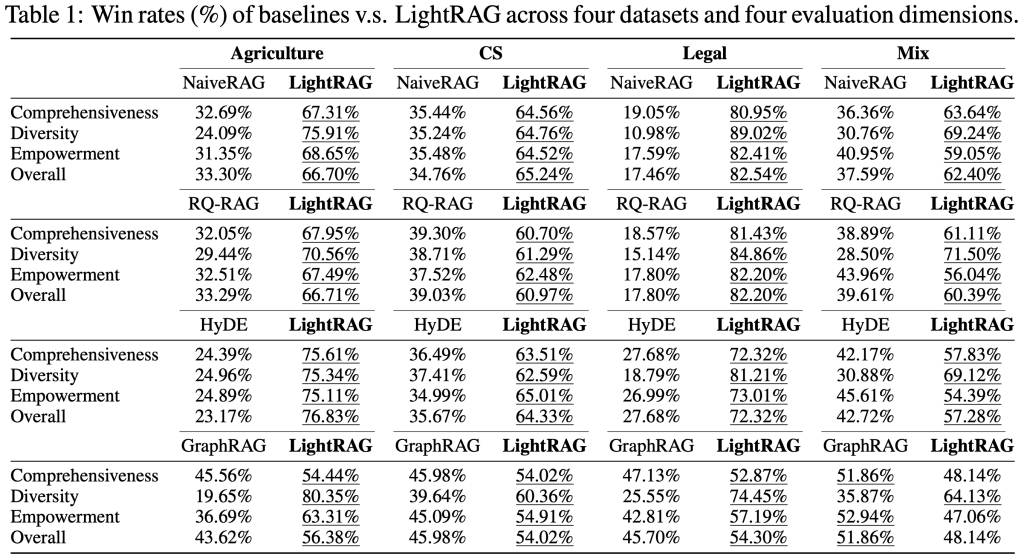
Source: LightRAG
When to choose LightRAG
Pick LightRAG if your application:
- Requires entity-centric or relationship-aware answers (e.g., compliance, engineering docs, product support), but you want to avoid heavy graph summarization costs
- Needs fast updates to the knowledge base with minimal re-indexing friction.
LightRAG Comes to BonBon for Next-Level AI Retrieval
LightRAG can be seamlessly integrated into NashTech’s Bonbon Intelligent Agent platform, enabling enterprises to leverage advanced graph-based Retrieval-Augmented Generation without building complex infrastructure from scratch.
By embedding LightRAG’s knowledge graph and dual-level retrieval capabilities into Bonbon’s workflows, businesses gain immediate access to context-rich, relationship-aware answers for compliance, operations, and decision-making. This integration minimizes development effort, accelerates deployment, and ensures that organizations can unlock the power of AI-driven insights within their existing Bonbon ecosystem—delivering smarter automation with minimal overhead.