



1. What is promptfoo?
promptfoo is an open-source CLI and library designed for evaluating and red-teaming Large Language Model (LLM) applications.
LLM red teaming involves identifying vulnerabilities in AI systems before deployment by using simulated harmful inputs. Essentially, promptfoo addresses both the functional and non-functional quality assurance (QA) of LLM applications.
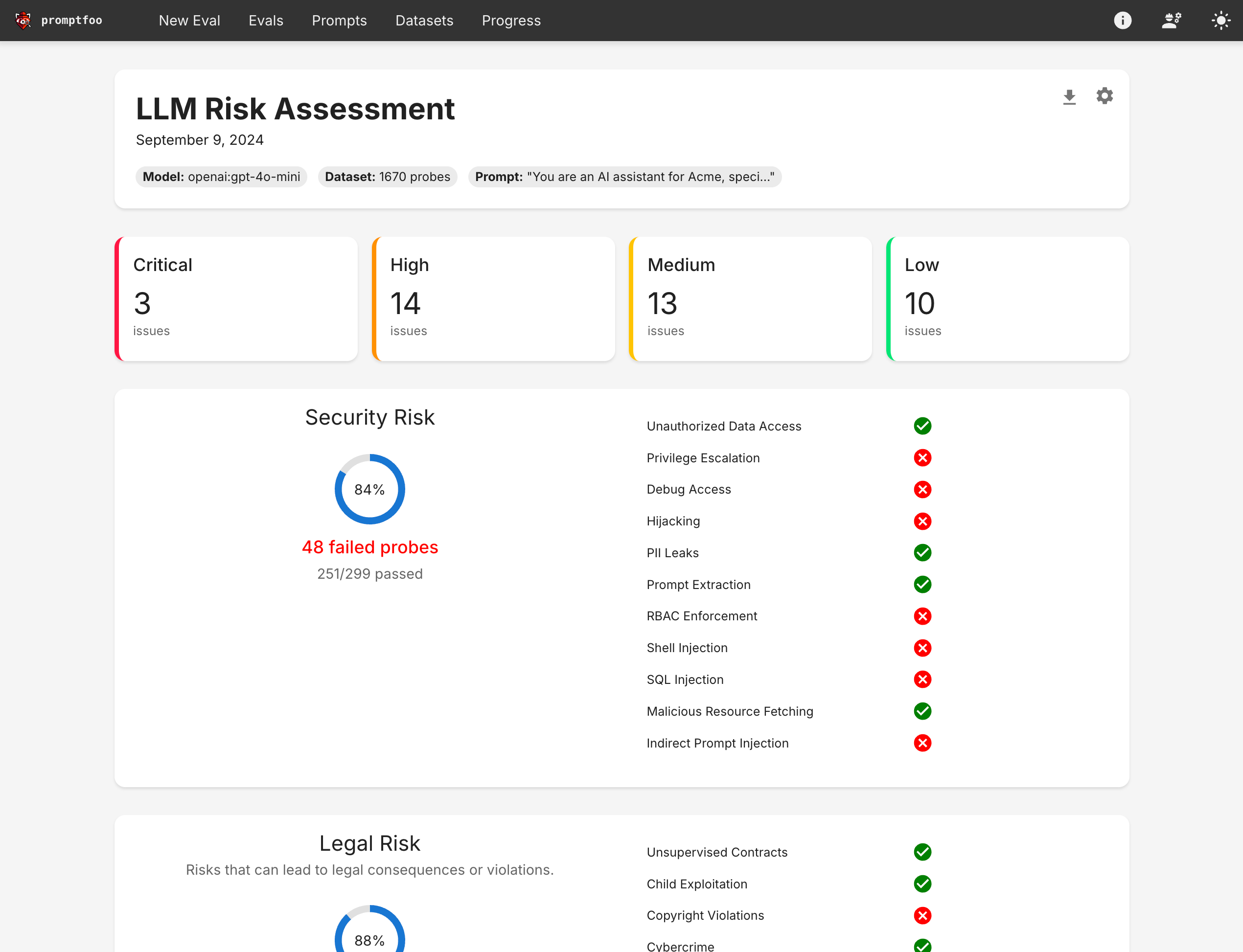
Both are crucial for ensuring that LLM applications are market-ready. However, this blog will focus solely on the first aspect of LLM QA: quality evaluation.
2. Benefits of using promptfoo in LLM development
With promptfoo, you can apply test-driven LLM development, not trial-and-error.
- Build reliable prompts, models, and RAGs with benchmarks specific to your use-case
- Secure your apps with automated red teaming and pentesting
- Speed up evaluations with caching, concurrency, and live reloading
- Score outputs automatically by defining metrics
- Use as a CLI, library, or in CI/CD
- Use OpenAI, Anthropic, Azure, Google, HuggingFace, open-source models like Llama, or integrate custom API providers for any LLM API
3. promptfoo’s strengths in LLM evaluation
- Proven capabilities: promptfoo is battle-tested by big LLM players such as Microsoft, Discord, Doordash, etc., serving over 10 million users in production.
- Simple, declarative test cases: Define evaluations without writing code or dealing with complex notebooks.
- Share & collaborate: Includes built-in sharing functionality and a web viewer for team collaboration.
- Open-source: Completely open-source with no strings attached.
- Private: Runs entirely locally. Evaluations are conducted on your machine and communicate directly with the LLM.
4. Basic structure of a promptfoo test case
promptfoo’s test cases are defined in a YAML file (call configuration). The YAML configuration format runs each prompt through a series of example inputs (“test case”) and checks if they meet requirements (“assertions”).
A promptfoo configuration has the following basic structure:
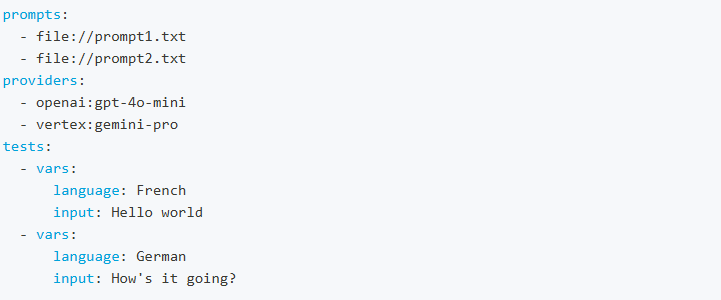
- prompts: input for tests. You can feed prompts from json or text files.
- providers: the LLM model/AI service under test. prompfoo supports a large number of providers including: OpenAI (GPT), Anthropic (Claude), Google Vertex AI (Gemini), etc.
- test inputs: example inputs for prompts. You can import tests from CSV files.
- assertions: automatically grade outputs on a pass/fail basis and score.
5. promptfoo’s assertions and metrics for LLM evaluation
Assertions are used to compare the LLM output against expected values or conditions. While assertions are not required to run an eval, they are a useful way to automate analysis.
Different types of assertions can be used to validate the output in various ways, such as checking for equality, JSON structure, similarity, or custom functions.
In machine learning, “Accuracy” is a metric that measures the proportion of correct predictions made by a model out of the total number of predictions. With promptfoo, accuracy is defined as the proportion of prompts that produce the expected or desired output.
5.1. Deterministic assertions
These assertions check if the output meets a determined criterion.
Some popular deterministic assertions are:
Contains
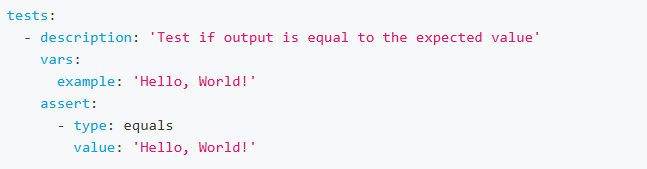
The contains assertion checks if the LLM output contains the expected value. Example:

Cost
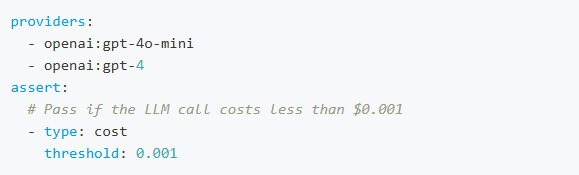
The cost assertion checks if the cost of the LLM call is below a specified threshold.
This requires LLM providers to return cost information. Currently this is only supported by OpenAI GPT models and custom providers. Example:
Latency
The latency assertion passes if the LLM call takes longer than the specified threshold. Duration is specified in milliseconds. Example:

Perplexity
Perplexity is a measurement used in natural language processing to quantify how well a language model predicts a sample of text. It’s essentially a measure of the model’s uncertainty.
High perplexity suggests it is less certain about its predictions, often because the text is very diverse or the model is not well-tuned to the task at hand.
Low perplexity means the model predicts the text with greater confidence, implying it’s better at understanding and generating text similar to its training data.
Example:

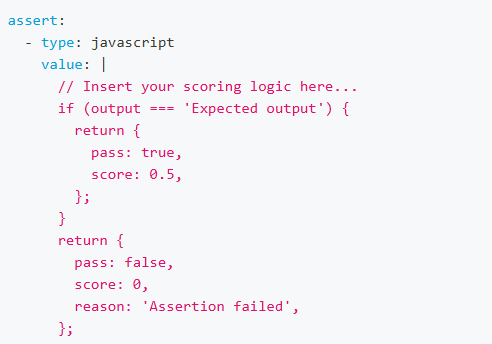
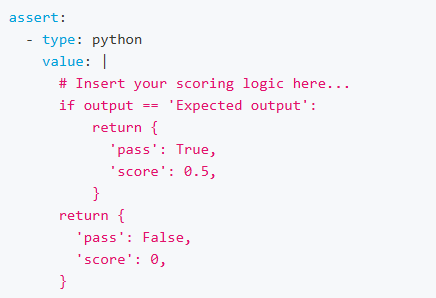
Javascript and Python assertion
promptfoo also allows using custom Javascript and Python functions for assertion.
Using Javascript:
Using Python:
5.2. Model-assisted assertions
These assertions rely on LLMs or other machine learning models to evaluate the output.
Some popular model-assisted assertions are:
Answer Relevance
The answer-relevance assertion evaluates whether an LLM’s output is relevant to the original query.

Factuality
The factuality assertion evaluates the factual consistency between an LLM output and a reference answer. That is, to grade if the output only contains information supported by the reference answer.

LLM Rubric
llm-rubric is promptfoo’s general-purpose grader for “LLM as a judge” evaluation.
llm-rubric uses a model to evaluate the output based on the criteria you provide. By default, it uses GPT-4o.

RAG-based assertions
promptfoo also supports assertions designed for RAG (Retrieval-Augmented Generation) applications as follows:
- Context Faithfulness: evaluates whether the LLM’s output is faithful to the provided context, ensuring the application doesn’t hallucinate.
- Context Recall: evaluates whether key information important facts/key information are being retrieved.
- Context Relevance: evaluates whether the retrieved context is relevant to the original query
6. Conclusion on promptfoo and LLM evaluation
In conclusion, when it comes to LLM evaluation, promptfoo is an invaluable tool for testing and optimizing LLM (Large Language Model) applications. By providing robust testing capabilities, it helps developers ensure their models perform reliably and efficiently. Additionally, promptfoo can leverage AI models to grade LLM outputs, offering insightful evaluations that guide improvements.
Whether you’re working on improving model accuracy, reducing biases, or enhancing user interactions, promptfoo offers the essential tools to achieve your goals. Embrace the power of promptfoo to elevate your LLM applications and deliver exceptional results.
1 thought on “Understanding promptfoo: LLM Evaluation Made Easy”
Great post, thanks @Quan Do