



Retrieval-Augmented Generation (RAG) is widely used in modern AI models. But what is it, and why does it matter?
Have you ever wondered why AI models sometimes provide outdated or inaccurate information?
Many AI-powered chatbots and content generation systems rely solely on pre-trained data. However, this approach has a major limitation: it cannot access real-time or external knowledge sources. As a result, AI models may produce outdated, incorrect, or even completely fabricated information.
The Retrieval-Augmented Generation (RAG) model was introduced to solve this challenge. But what exactly is RAG, and how does it work? More importantly, how does it improve AI-generated content?
Let’s explore RAG and understand how it works and why businesses, researchers, and AI developers are increasingly adopting this approach.
1. What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) is an advanced AI technique that combines retrieval-based search with content generation to enhance AI responses’ accuracy, relevance, and freshness. Instead of relying solely on pre-trained knowledge, RAG actively searches for the most relevant external information before generating a response.
RAG techniques effectively help LLMs reason about private datasets—data that the LLM has not been trained on or seen before, such as an enterprise’s proprietary research, business documents, or communications.
2. How Does It Work?

Phase 1: Retrieval – Find the Right Data

In phase 1, we search external sources (e.g., databases, APIs, vector search). This step does not typically require calling an LLM.
- AI searches external sources (databases, documents, APIs) for relevant information.
- We fetch data using embedding-based search (e.g., vector databases like LanceDB, FAISS, Pinecone) or keyword search (e.g., Elasticsearch, SQL).
- As a result, the goal is to fetch relevant documents quickly without invoking a computationally expensive LLM.
Phase 2: Augment – Enhancing AI Knowledge

After phase 1, we will have relevant documents, and following this step-by-step process, we will have accurate documents.
- The system processes, filters, and structures the retrieved data to improve quality.
- After that, AI combines this information with pre-trained knowledge for better context.
But, in some advanced hybrid RAG models, we can use an LLM in this phase. We can see some cases below:
1. Rewrite User Queries for better search results:
We can use an LLM to rephrase the query instead of searching directly with the raw query to improve retrieval accuracy.
Example:
- User query: “How does quantum computing work?”
- LLM reformulates: “Explain the principles of quantum mechanics in computing with examples.”
- The retrieval engine will use the refined query.
2. Extract Structured Queries:
If the retrieval system requires SQL, GrpahQL, or API calls, an LLM can convert a natural language query into a structured search query.
Example:
- User query: “Show me the recent EU data privacy laws.”
- LLM converts to “SELECT * FROM laws WHERE region = ‘EU’ AND category = ‘data privacy’ ORDER BY date DESC;”
3. Re-Rank Retrieved Results:
After retrieving multiple documents, an LLM can evaluate and rank them based on relevance. Instead of picking the first match, an LLM scores and selects the most useful document.
Phase 3: Generation – Producing Accurate Responses

In this phase, the AI model processes both the retrieved external information (from the retrieval phase) and its internal knowledge. As a result, the LLM models (such as GPT, LLaMA, or Claude) will generate a response by combining both sources coherently and meaningfully.
1. Pass Augmented data to LLM
The system feeds the refined, structured, and contextually relevant data from the Augment phase into the LLM. This ensures the model leverages external knowledge rather than relying solely on its pre-trained data.
2. LLM generates the final response
The LLM synthesizes the retrieved data and its internal knowledge to construct a well-informed response. After that, reasoning, language coherence, and contextual understanding are applied to deliver an accurate answer.
3. The user receives an AI-generated answer
The final response is formatted and returned to the user through the application interface (e.g., chatbot, search assistant, API). As a result, the user gets a fact-based, enriched response that dynamically integrates real-time external knowledge.
3. Why should you use Retrieval-Augmented Generation?
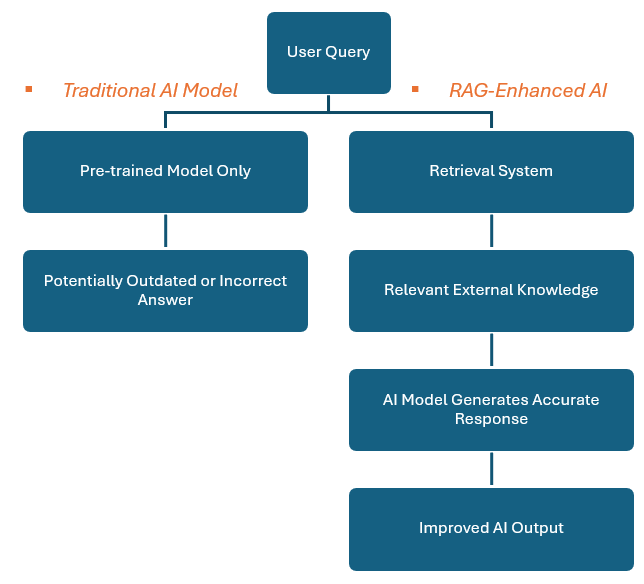
After reading two sections, we can learn what RAG is and how it works. This section will continue explaining why we should use it. Before that, we need to understand the difference between RAG and the traditional AI model. Please take a look at the below table to have an overview:
| Feature | Traditional AI Model | RAG – Enhanced AI |
|---|---|---|
| Data Source | Uses only pre-trained knowledge | Retrieves real-time information |
| Response Accuracy | Prone to outdated or hallucinated facts | More accurate and up-to-date |
| Adaptability | Requires re-training for new data | can dynamically fetch new information |
| Use Case Examples | Chatbots, static knowledge bases | Research assistants, real-time customer support |
As seen above, RAG empowers AI models to deliver factual and reliable responses, especially in fast-changing finance, healthcare, and legal industries. Finally, we have some reasons to use RAG below:
3.1 Improving Accuracy and Reducing AI Hallucinations
First and foremost, RAG minimizes the risk of AI-generated misinformation. Traditional models might generate plausible but incorrect responses due to outdated training data. However, RAG verifies and enriches answers with real-world facts before responding.
3.2 Keeping Information Fresh and Updated
Furthermore, RAG eliminates the need for constant retraining. Instead of updating an AI model’s dataset periodically, RAG-enabled AI can access external sources in real time, ensuring responses always reflect the latest information.
3.3 Enhancing AI-powered Search and Chatbots
Many AI applications, such as customer service chatbots and virtual assistants, struggle with retrieving specific and accurate information. With RAG, AI can retrieve and summarize the most relevant data, improving user experience.
3.4 Scaling Knowledge Management Effortlessly
RAG provides a more intelligent way to query and summarize data dynamically for businesses managing large volumes of internal documents (e.g., FAQs, policy documents, research papers).
4. How to implement Retrieval-Augmented Generation?
Implementing Retrieval-Augmented Generation (RAG) requires integrating multiple components to retrieve relevant information, enhance it, and generate a final AI response. A well-designed RAG system significantly improves the accuracy of AI-generated content by combining real-time information retrieval with generative AI capabilities.
4.1 Define the RAG Use Case
Before implementation, we need to identify why and where RAG is needed. We have some common use cases:
- Chatbots & Virtual Assistants: These AI will answer user queries with up-to-date knowledge.
- Enterprise Knowledge Management: Almost all internal documents are private data, so we need to build a mechanism to retrieve data. Besides that, we need to retrieve insights from internal documents.
- Scientific Research & Healthcare: Access the latest research papers and medical guidelines.
- Legal & Compliance: Fetch the latest laws and policies for accurate legal assistance.
- E-commerce & Product Discovery: Enhance product recommendations with real-time inventory and pricing.
4.2 Build a Knowledge Base (Retrieval Data Source)
RAG relies on external data sources to fetch real-time information. These can be structured or unstructured data repositories. We can have various kinds of data sources:
- Vector databases: used for similarity search (LanceDB, FAISS, Pinecone, Weaviate, ChromaDB)
- Relational Database: used for structured information (PostgreSQL, MySQL, SQL)
- Search Engines: useful for keyword-based retrieval (Elasticsearch, OpenSearch, Vespa)
- Document Storage Systems: used for unstructured document retrieval (AWS S3, MongoDB, Google Drive, SharePoint)
- API-based Sources: Real-time knowledge retrieval (Wikipedia API, Google Knowledge Graph, News APIs)
We will choose a combination of structured and unstructured sources based on the retrieval needs.
4.3 Implement the Retrieval Engine
The retrieval engine searches, ranks, and returns the most relevant data based on the user’s query. So, we need to implement below steps:
- Convert Query into Searchable Format
- Use embedding models (e.g., OpenAI
text-embedding-ada-002, BERT, Sentence Transformers) to transform queries into vectors. - If using keyword-based retrieval, apply TF-IDF or BM25 ranking.
- Use embedding models (e.g., OpenAI
- Retrieve the Most Relevant Data
- Perform vector similarity search (for semantic search).
- Use full-text search (if working with structured keyword queries).
- Re-rank & Filter Results
- Use additional scoring functions to prioritize the most relevant results.
- Implement LLM-based re-ranking if needed for better context matching.
4.4 Augment Retrieved Data for Context
Once the relevant documents are retrieved, the system must carefully process and structure them before passing them to the LLM. This step is essential because raw retrieved data may contain irrelevant information or lack proper context. Therefore, to enhance the quality of the final response, we typically follow several key steps in the augmentation process.
- Preprocess the retrieved content:
- First and foremost, we need to remove irrelevant sections
- Moreover, we need to extract key insights
- Finally, we summarize lengthy documents
- Format the Data for LLM Processing:
- We should use structured prompts:
"Based on the following retrieved information, answer the user query ..." - In addition, we can combine multiple sources for better accuracy.
- Finally, we implement context window optimization (e.g., truncate long documents)
- We should use structured prompts:
Example of Augmented Context:
{
"query": "How does RAG work?",
"retrieved_docs": [
"RAG combines information retrieval with language model generation.",
"It fetches relevant data before generating AI responses."
],
"formatted_context": "RAG integrates retrieval and generation to enhance AI accuracy. It first searches external sources for relevant documents, then synthesizes them to generate informed responses."
}
4.5 Generate AI Responses (Calling the LLM)
After carefully structuring the retrieved information, the next crucial step is to pass it to the LLM for response generation. To achieve this efficiently, we should follow a structured approach. First, ensuring that the input is well-formatted is essential, allowing the model to process the data accurately and generate a coherent response. Then, we must refine the prompt to provide clear guidance. Finally, we can optimize parameters to balance accuracy and coherence, ensuring the best possible response.
- Pass augmented data to LLM
- Combine user query + retrieved documents as input.
- Use prompt engineering to guide response generation.
- Generate the final response
- Use an LLM API (OpenAI GPT-4, Claude, LLaMA) or a fine-tuned model.
- Adjust temperature and max tokens to balance creativity vs. factual accuracy.
4.6 Optimize and Monitor RAG Performance
Optimizing and monitoring performance continuously is essential to ensuring RAG delivers accurate and efficient responses; otherwise, retrieval errors, increased latency, and irrelevant outputs can degrade the system’s effectiveness. So, we can follow below strategies:
- Fine-tune retrieval accuracy:
- Experiment with embedding models (e.g., OpenAI, BERT, Cohere).
- Improve ranking algorithms for better result prioritization.
- Improve system latency:
- Cache frequently retrieved documents.
- Use low-latency vector search techniques (e.g., Approximate Nearest Neighbors).
- Monitor and refine AI outputs:
- Log user feedback to improve retrieval ranking.
- Regularly update the knowledge base to maintain relevance.
Conclusion
Retrieval-Augmented Generation (RAG) transforms AI by integrating real-time, relevant information into generated responses. Instead of relying on stale, static models, RAG offers a dynamic, evolving AI experience, making it more intelligent, accurate, and useful for businesses, research, and everyday applications.
Read more
- AI ChatGPT: Revolutionizing Human-Computer Interaction
- Explore AI: perform human intelligent tasks – NashTech Insights
- Top AI Tools: Frameworks, Platforms, and AutoML Solutions – NashTech Insights
- Agentic AI vs AI Agent – NashTech Insights
Reference
- LanceDB – The Database for Multimodal AI
- Welcome to Faiss Documentation — Faiss documentation
- The vector database to build knowledgeable AI | Pinecone
- What Is Retrieval-Augmented Generation aka RAG | NVIDIA Blogs
- What is Retrieval-Augmented Generation (RAG)? | Google Cloud
- What is RAG? – Retrieval-Augmented Generation AI Explained – AWS