



Welcome back to the Akka Persistence series! In Part 1: From Coffee Shops to Game Save/Load, we explored what Akka Persistence is and how it works. Following that, Part 2: The Akka Coffee Shop’s Secret delves into the inner workings like Event vs. State, Snapshots and Projections.
We’ve seen how Akka Persistence helped Khanh build a resilient coffee shop, handling everything from a simple loyalty program to a major power outage. But the shop didn’t stay small. It became a franchise. Khanh’s coffee shop becomes so popular that she needs to expand to multiple branches, serving thousands of customers, and even a new mobile app for pre-orders, the stakes are now higher: downtime costs money and system design must handle scale and evolution.
Today, we’re taking the final step of our journey. If our coffee shop is successful and expands globally, how will Akka Persistence be applied in a real production environment? We’ll explore the hard-won lessons of Clustering, Scaling, and the real-world challenges of bringing Akka Persistence to life.
Let’s walk through the next set of challenges our coffee shop faced, and how Akka Persistence in production offers solutions.
1. Challenge 1: From Monolith to Distributed Systems – Designing a Microservice
Khanh’s single-machine Akka application was a brilliant start, but as she opened branches in different cities, she realized a new strategy was needed. Each city branch had to be its own independent unit, a microservice, responsible for its own orders and customer data.
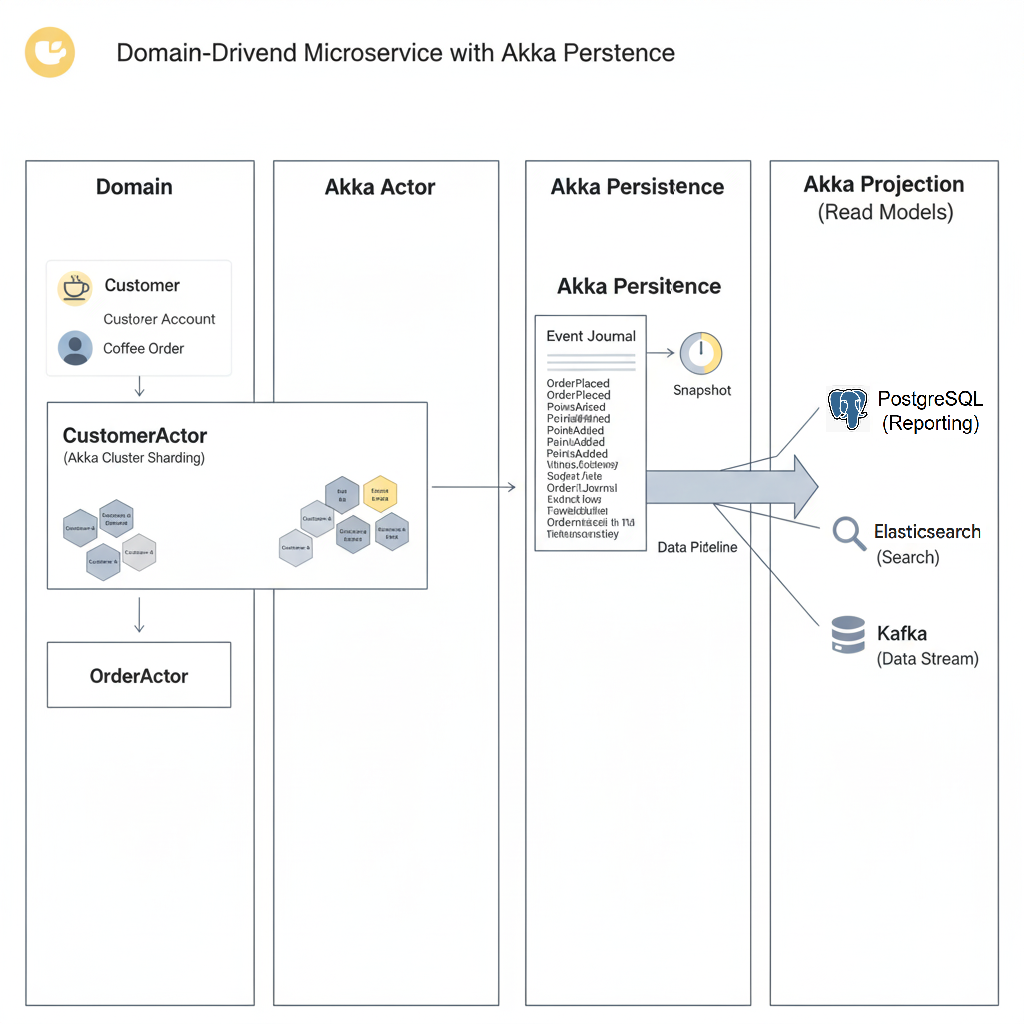
This led to a new design pattern:
- Domain: The business concept itself, like a
CoffeeOrderor aCustomerAccount. - Actor: A single actor instance in Akka, like
OrderActor-123, that handles all commands related to a specific domain entity. - Persistence: The
EventSourcedBehaviorwe’ve already discussed, saving every state-changing event for recovery. - Projection: The mechanism that reads these events and projects them into a read model (e.g., a database for analytics or a search index) for reporting and querying.
This microservice-based architecture, powered by Akka Persistence, ensured that if one branch (microservice) went down, the others remained unaffected.
Imagine each Order is modeled as an Actor. An actor persists order events (OrderPlaced, PaymentConfirmed, RefundIssued) using EventSourcedBehavior. A Projection streams these events into a loyalty points service and reporting dashboards.
2. Challenge 2: Pitfalls – The Ghosts in the Machine
Running a global coffee chain taught Khanh some painful lessons. She started facing problems she never knew existed – issues that only surface when a system reaches a certain scale.
Slow Replay – The Monday Morning Meltdown
Khanh’s most loyal customer, a man named Tuan, has placed over 10,000 orders at her coffee shops over two years. Every time he places an order, an OrderPlaced event is created. One Monday morning, a branch’s server fails and restarts. When the system tries to recover the state of Tuan’s CustomerActor, it starts replaying all 10,000 events from the beginning. Customers are waiting, and this process takes 10 minutes – an unacceptable amount of time in business.
The Solution: Snapshotting Strategy. Khanh realized she didn’t need to replay the entire 10,000-event history. She only needed the last known state of Tuan (e.g., his loyalty points and number of orders) and then replay the most recent events. She configured her system to “take a picture” of the state (a snapshot) every 100 events.
The Lesson: Using snapshotting is a trade-off between recovery performance and storage/processing costs. Too high a snapshot frequency uses a lot of disk space, while too low a frequency slows down recovery.
Code Samples
Behaviors.setup[Command] { context =>
EventSourcedBehavior[Command, Event, State](
persistenceId = PersistenceId.ofUniqueId("customer-123"),
emptyState = CustomerState.empty,
commandHandler = (state, command) => /* ... */,
eventHandler = (state, event) => /* ... */
).withRetention(
// Retain 2 snapshots, delete events after 2 snapshots and 100 events
RetentionCriteria.snapshotEvery(numberOfEvents = 100, keepNSnapshots = 2)
)
}Schema Evolution – The Death of Immutability
Khanh wanted to upgrade her loyalty program by adding a new loyaltyTier field (Bronze, Silver, Gold) to the CustomerPointsAdded event. She added this field in her code. However, when the system restarted and tried to read the millions of old events (which didn’t have this field) from the journal, it encountered a deserialization error and failed to recover the state.
The Solution: Event Adapters. Instead of changing the schema of the old event, Khanh created a new event type but also taught the system how to read the old events. She used Akka Persistence’s Event Adapters.
- The old event code was left as is.
- A new event with the
loyaltyTierfield was created. - An
EventAdapterwas written to recognize old events and transform them into the new format during the replay process. - Version your events (
CustomerPointsAddedV1,CustomerPointsAddedV2).
The Lesson: The core principle is: “Events are immutable.” You should never change a stored event. Event Adapters are a powerful tool to ensure backward compatibility.

Code Samples
// Define the old and new events
case class CustomerPointsAddedV1(customerId: String, points: Int) extends Event
case class CustomerPointsAddedV2(customerId: String, points: Int, loyaltyTier: String) extends Event
// The Event Adapter for transformation
class CustomerEventAdapter extends EventAdapter[Event, Any] {
// ...
override def fromJournal(event: Any, manifest: String): Event = {
event match {
case v1: CustomerPointsAddedV1 =>
// Assign a default value to the new field
CustomerPointsAddedV2(v1.customerId, v1.points, "Bronze") // safe default
case newEvent: CustomerPointsAddedV2 => newEvent
case other => throw new RuntimeException(s"Unknown event type: $manifest")
}
}
}Data Migration – Moving Beans Without Spilling Coffee
After a while, Khanh realized that her initial event-storage database (a simple file-based one) could not handle the demands of a global coffee chain. She decided to migrate all her event data to a more robust, distributed database like Cassandra, with zero downtime. This required migrating a massive amount of event data without interrupting the live system.
The Solution:
1. Dual-Write Strategy
- Keep the old pipeline running.
- Build a new projection off the new backend.
- Compare aggregates (counts, sums) and sample payload parity.
2. Outbox + Idempotency
- Persist an outbox record with a stable messageId in the same TX as the event.
- Projections publish using
messageId, downstreams de-duplicate.
3. Phased cutover
- Switch consumers to the new topic/endpoint gradually.
- Keep the old path hot as fallback until metrics are green.
The Lesson: Data migration in a production environment is always risky. A dual-write approach ensures data integrity and zero business disruption.
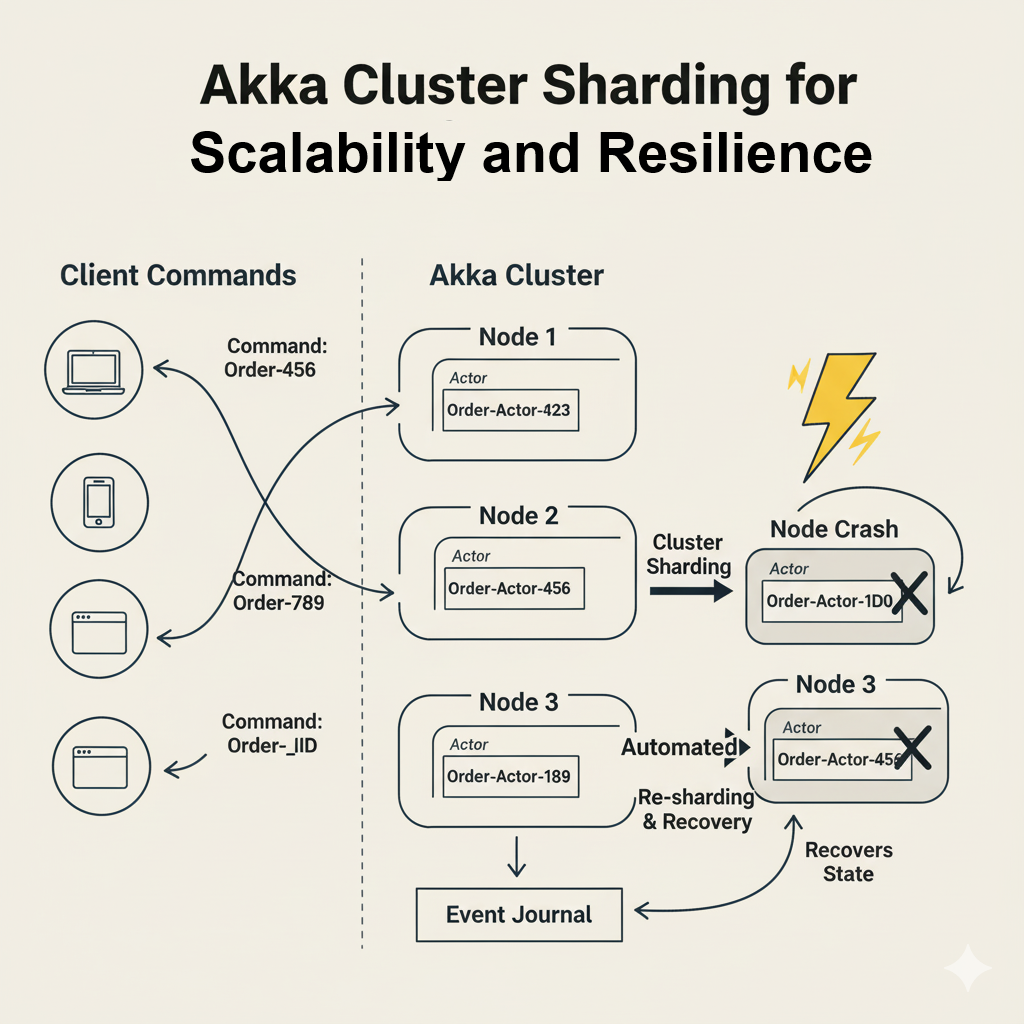
3. Challenge 3: Scaling Out with Akka Cluster Sharding and Persistence
The single-node architecture was no longer sufficient. To serve millions of customers, Khanh’s system needed to scale horizontally. She leveraged Akka Cluster to link multiple servers together, forming a single, logical system.
She then used Akka Cluster Sharding. Instead of having all OrderActor instances on one server, Sharding automatically distributed them across the entire cluster. When a command for Order-123 arrived, Akka knew exactly which server the corresponding OrderActor was running on and routed the command there. If that server went down, Akka would automatically re-shard the actors, spinning up a new OrderActor-123 on a different server and recovering its state from the event log. This is the built-in resilience of Akka at a massive scale.
4. Challenge 4: Akka Persistence on the Cloud – The Final Frontier
The final step for the coffee chain was to move its operations to the cloud (Azure, AWS, or GCP). This provided incredible flexibility and scalability, but also introduced new challenges. Khanh had to:
- Choose a distributed database that was a good fit for Akka Persistence, such as a managed Cassandra or a relational database with a dedicated journal plugin.
- Configure the Akka Cluster to work seamlessly within the cloud’s dynamic networking environment.
- Monitor performance and resource usage to optimize cloud costs.
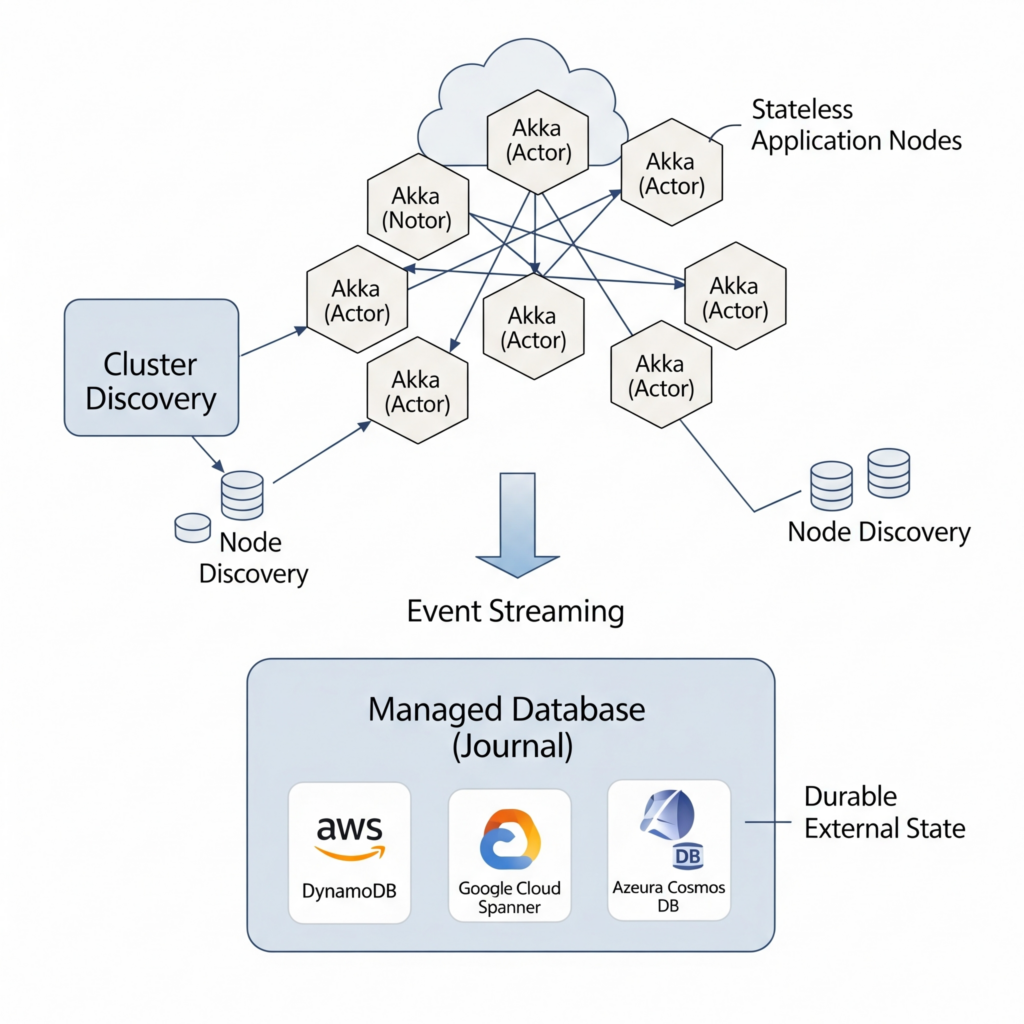
Running a stateful, clustered system like Akka Persistence in the cloud requires careful planning. The key is to leverage managed services for your journal and discovery.
- The Journal: The single source of truth. Using a managed, multi-AZ (Availability Zone) database service is critical for high availability.
- AWS: Amazon RDS for PostgreSQL/MySQL, or Amazon Keyspaces (for Cassandra).
- GCP: Cloud SQL for PostgreSQL/MySQL, or Bigtable.
- Azure: Azure SQL, Azure Database for PostgreSQL, or Azure Cosmos DB (with Cassandra API). Using a managed service offloads the immense operational burden of running a resilient database cluster yourself.
- Cluster Discovery: How do new nodes find each other to form a cluster when they start up in an elastic, cloud environment?
- Akka Management with Cluster Bootstrap: This is the standard mechanism. It integrates with cloud provider APIs to discover other nodes.
- Kubernetes: If you’re running on K8s, Akka Discovery has a Kubernetes API module that lets nodes use the K8s API server to find their peers. This is the most common and robust approach for containerized Akka applications.
- Stateless vs. Stateful: Your Akka application nodes themselves are stateful in the sense that actors live on them, but their state is durable because it’s stored externally in the journal. This allows you to run your application on ephemeral cloud instances (like EC2 Spot Instances or GCP Preemptible VMs) to save costs, knowing that if a node disappears, the actors and their state can be recovered elsewhere in the cluster.
Wrapping Up
Over the course of this three-part series, we’ve followed the story of Akka Coffee shop, using its evolution as a case study for building a resilient, scalable, and data-rich system with Akka Persistence. Here’s a quick recap of our journey:
- Start simple (Durable State). Initially, the shop used a basic state management approach, storing only the most recent data.
- Add resilience and audit (Event Sourcing, Snapshots). To handle failures and provide a full history, the system was upgraded to use Event Sourcing. To optimize recovery from the long event logs, a snapshotting strategy was added.
- Ensure correctness (Idempotency, Exactly-once). With a distributed system, a key challenge was guaranteeing that events were processed correctly, even if they were sent multiple times due to network issues.
- Scale out (Cluster Sharding). To handle the massive increase in customers, the system was scaled horizontally by distributing actors across multiple servers using Akka Cluster Sharding.
- Go global (Cloud persistence). The final step was to move the entire operation to the cloud, ensuring global reach and scalability while managing the unique challenges of cloud environments.