



Welcome back to our series on Akka Persistence! In our previous article, we explored a theoretical Akka-powered coffee shop to understand what Akka Persistence is and how it reconstructs state from a stream of events. Today, we’re going behind the scenes, where the real magic happens. We’ll explore the practical challenges the owner faced and how Akka Persistence helped transform his business into a resilient and powerful “machine.”
1. The Problem: Storing State or Storing History?
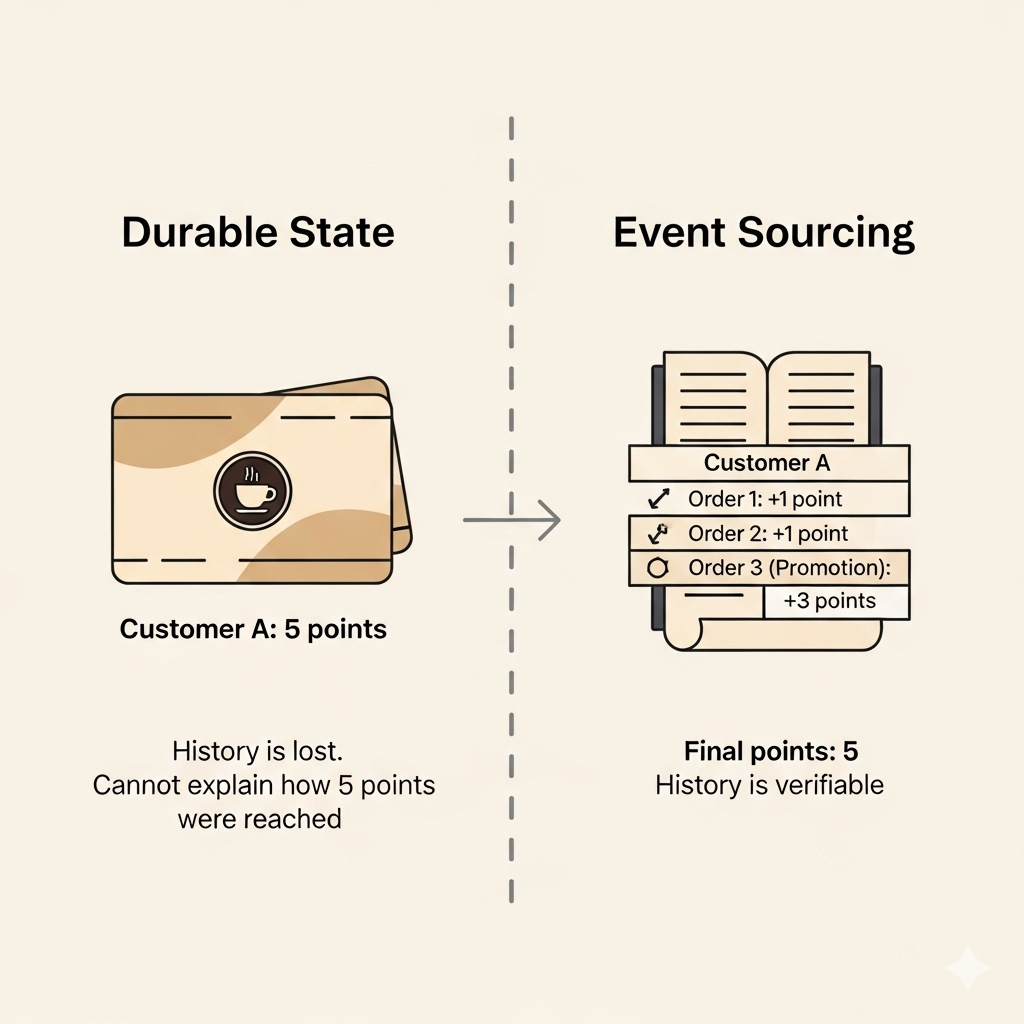
Khanh, the owner, just launched a new loyalty program. Every time a customer places an order, they get a point. Accumulate 10 points, and they get a free coffee.
Initially, she simply stored the current state of each customer: “Customer A has 5 points,” “Customer B has 8 points.” This was simple and effective. But then, a problem arose. One day, a customer complained, “I remember ordering two coffees last week. Why do I only have 5 points now?”
To solve this, she needed to know not just “how many points Customer A has,” but also “the history of how Customer A earned those points.” She needed to be able to replay the entire process: “Transaction 1: +1 point,” “Transaction 2: +1 point,” “Transaction 3: +3 points (promotion).”
This is the core difference between two approaches in Akka Persistence:
- DurableStateBehavior: This was her initial, simple approach. It only stores the last known state of an object. Each time there’s a change, it overwrites the old state. It’s fast, but you lose the history.
- EventSourcedBehavior: She switched to this method. Instead of storing the final point count, she recorded each point-earning event:
PointAdded(customerId, 1),PointAdded(customerId, 3). By doing this, she could reconstruct the final state at any time by replaying the entire history of events. It’s like keeping a full ledger.
The Solution: Akka Persistence lets her choose EventSourcedBehavior to preserve the full history, making it easy to query past events, debug issues, and handle more complex scenarios down the road.
When to use which?
EventSourcedBehaviorshould be used when:- You need the full history of state changes.
- You want to create different read models from the same event stream.
- Events have business significance and need to be processed individually (e.g., sending a confirmation email on an
OrderPlacedevent).
DurableStateBehavioris a better fit when:- Your state is simple and changes frequently, but the history isn’t important.
- The cost of storing and recovering from a long event stream is inefficient.
- You only need the current state to continue operating.
Code Samples
// EventSourcedBehavior: Coffee Shop Order
object CoffeeShopOrder extends EventSourcedBehavior[Command, Event, State] {
// ...
def commandHandler(state: State, command: Command): ReplyEffect[Event, State] =
command match {
case PlaceOrder(items, replyTo) =>
Effect.persist(OrderPlaced(items)).thenReply(replyTo)(_ => "Order placed successfully")
}
def eventHandler(state: State, event: Event): State =
event match {
case OrderPlaced(items) => state.copy(orders = state.orders :+ items)
}
}
// DurableStateBehavior: Counter
object DurableCounter extends DurableStateBehavior[Command, State] {
// ...
def commandHandler(state: State, command: Command): ReplyEffect[State] =
command match {
case Increment => Effect.persist(state.copy(value = state.value + 1))
case GetValue(replyTo) => Effect.reply(replyTo)(state)
}
}2. The Problem: Recovery Takes Too Long
The coffee shop grew increasingly busy, with thousands of orders placed daily and Akka logging tens of thousands of events. One day, the system went down due to a power outage. When it restarted, Akka Persistence began recovering the state for each actor by reading all the events from the beginning.
Khanh waited. 5 minutes went by, then 10… The recovery time was too long, disrupting business and affecting the customer experience.
Reading the entire event log to recover a state is like re-reading a thick notebook from the very first page. This is fast for a thin notebook but becomes a chore for a thousand-page one.
The Solution: This is when she discovered Snapshots.
She decided to take a “picture” of each order’s state after every 100 events. Now, instead of replaying from the very first event, the system only needs to find the most recent snapshot and replay the few events that occurred after it. This makes the recovery process significantly faster.
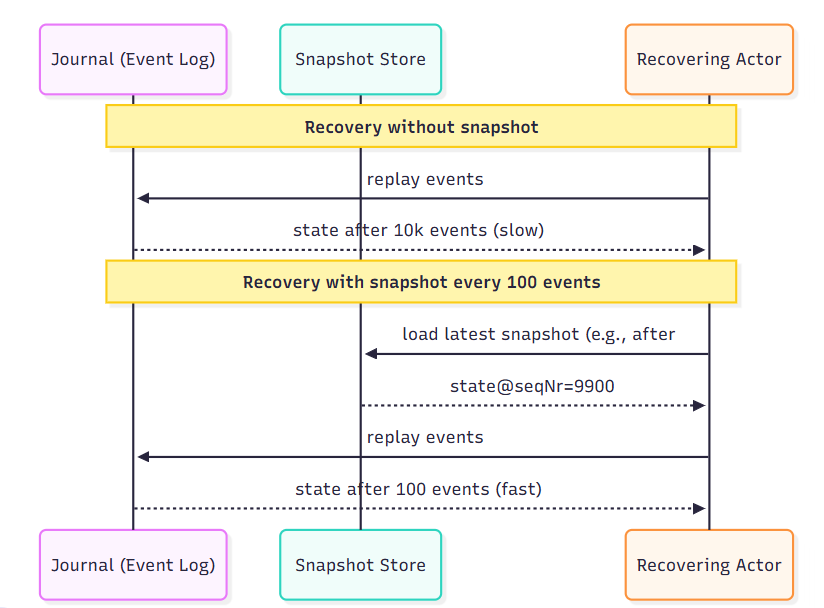
- The system restarts.
- It finds a snapshot saved at 10 a.m.
- Instead of reading 1,000 events from the start, it only needs to read the 50 events that occurred between 10 a.m. and the crash.
- The recovery process takes just a few seconds.
Code Samples
EventSourcedBehavior[Command, Event, State](
persistenceId,
emptyState = State.empty,
commandHandler = ...,
eventHandler = ...
).snapshotWhen {
case (state, event, seqNr) => seqNr % 100 == 0
}
Using snapshots is a trade-off: more frequent snapshots lead to faster recovery but use more storage. Fewer snapshots save space but can slow down recovery if the event log becomes very long.
Snapshotting Strategies
- Based on event count: Save a snapshot after every N events (e.g., every 100 events). This is the most common strategy, balancing performance and storage costs.
- Based on time: Save a snapshot every hour or every day, regardless of how many events occurred.
- When the state changes significantly: Save a snapshot when a major state change happens (e.g., when a large order is completed).
Choosing the right strategy is a trade-off:
- Frequent snapshots: Better recovery performance but higher storage and processing costs.
- Infrequent snapshots: Lower storage costs but potentially slower recovery if the event log gets very long.
3. The Problem: Business Intelligence and Reporting
Back at the coffee shop, Khanh has a full history of events, but now she wanted to know which items were best-sellers during peak hours, or what her most loyal customers typically ordered.
Running complex queries directly on Akka’s event log was inefficient. The log is designed for event-sourcing, not for analytics.
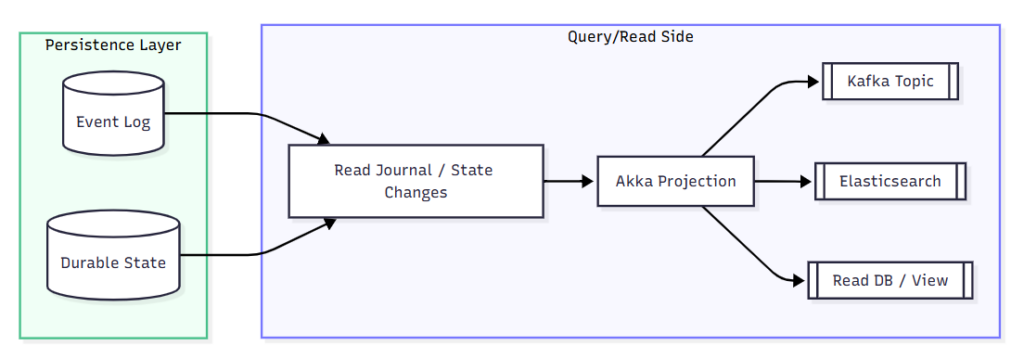
The Solution: She used Akka Projections.
She built a separate “stream” that listened for all new OrderPlaced events from the Akka Persistence event log. Whenever a new event arrived, it would automatically:
- Increment the product count in a “Sales Report” table in a different database (e.g., PostgreSQL).
- Store customer and order details in a search-optimized database (e.g., Elasticsearch) for easy searching.
This is the core idea of Akka Projections: it “projects” events from Akka Persistence into other read models, each optimized for a specific purpose like analytics, reporting, or searching. This decouples core state processing from data analysis, making the system more flexible and powerful.
Conceptual Code Example
// A Projection listening to events and updating a report
val reportProjection =
EventSourcedProjection.eventsByTag[OrderEvent](
projectionId = "item-sales-report",
sourceProvider = EventSourcedProvider.eventsByTag[OrderEvent](
system = system,
tags = Set("orders-tag")
),
handler = () =>
new ProjectionHandler[OrderEvent] {
def process(event: OrderEvent): Future[Done] =
event match {
case OrderPlaced(items) =>
// Update sales count in a database table
db.updateItemSales(items)
Future.successful(Done)
}
}
)4. The Problem: A Double Payment Glitch
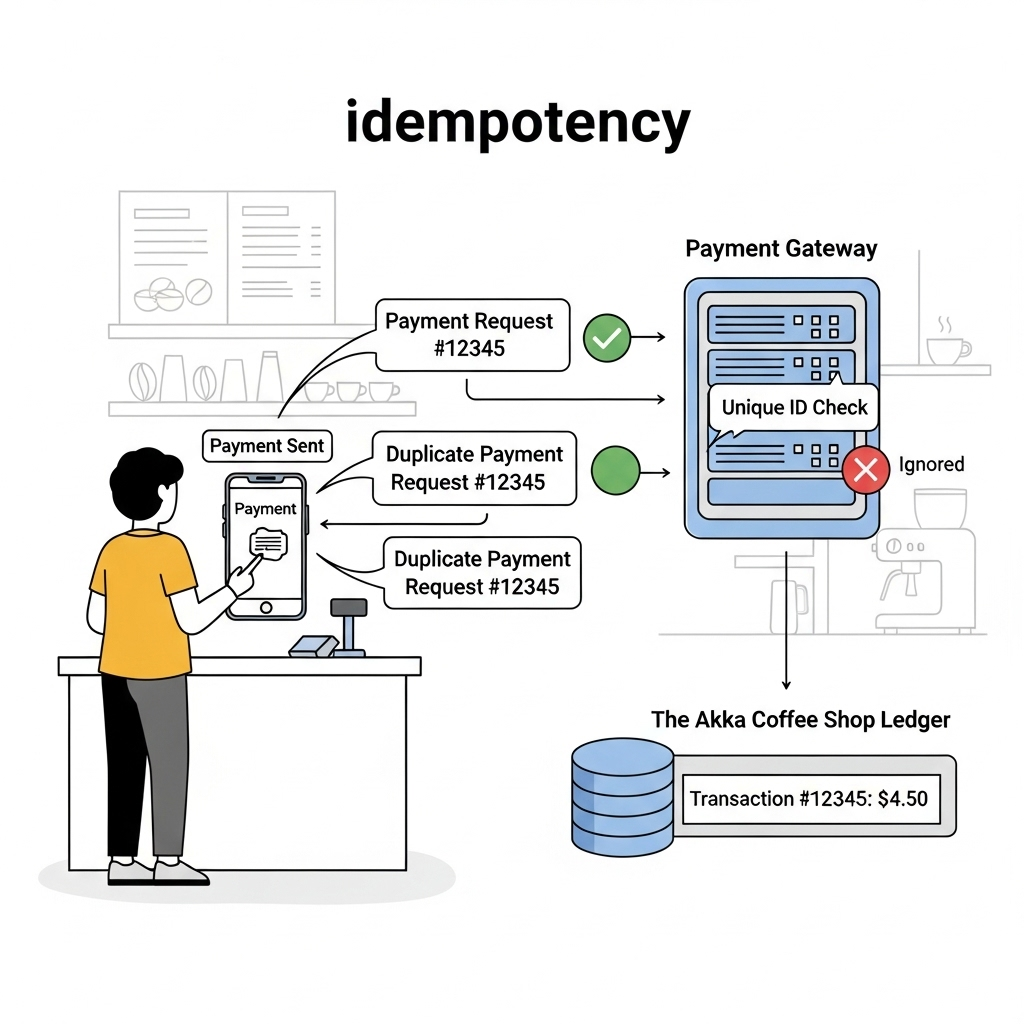
One day, the network flickered, and a customer’s payment was sent twice. Akka logged two PaymentReceived events. The system processed the payment and charged the customer twice!
The Solution: Akka Persistence helps handle idempotency and exactly-once delivery in a distributed environment.
- Idempotency: Akka ensures that each event is processed only once, even if it’s sent to the actor multiple times due to a network error. Each event is stored with a unique sequence number, helping the system recognize and discard duplicates.
- Exactly-once: Akka Projections, when integrated with other systems like Kafka, use transactional mechanisms to ensure that an event is processed and written to its destination only once, without being lost or duplicated.
Thanks to these mechanisms, the owner, Khanh no longer worries about duplicate payments. The system remains reliable, even in the face of failure.
Wrapping Up
We’ve now taken a deeper look into Akka Persistence and seen:
- Event vs State: snapshots vs full history.
- Snapshots: balancing performance and recovery speed.
- Projections: pushing data out into the wider world.
- Idempotency: ensuring correctness despite retries.
🔑 Takeaway: Akka Persistence isn’t just about state machines. It’s a data pipeline:
- Commands → Events/State → Persistence → Projections → External Systems.
In the final part of this series, we’ll look at production pitfalls, schema evolution, and scaling with Akka Cluster Sharding.