



Key takeaways:
Zero ETL is being introduced by AWS, Google, Databricks, and others as a future trend in the field of data engineering. However, current solutions are only available for projects with large budgets and rely on proprietary software. This article aims to share an idea for implementing Zero ETL using the open-source ClickHouse.
I. Introduction
Recently, Amazon Web Services (AWS) has introduced Zero ETL integration between Amazon Aurora and Amazon Redshift, enabling automatic and continuous replication of transactional data from Aurora to Redshift within seconds. This eliminates the need for complex data pipelines, allowing customers to leverage Aurora for transactional databases and Redshift for analysis seamlessly and efficiently [1].

By enabling near real-time access to transactional data, AWS allows you to utilize the analytical features of Amazon Redshift, such as built-in machine learning, materialized views, data sharing, and federated access to multiple data stores and data lakes, to gain valuable insights from both transactional and other data sources. The zero-ETL integration between Amazon Aurora and Amazon Redshift is currently available in a limited preview for Amazon Aurora MySQL 3 with MySQL 8.0 compatibility in the US East (N. Virginia) Region. To request access to the limited preview or to learn more about each service, you can visit the Preview Page [2] or the respective webpages of Amazon Aurora and Amazon Redshift. The buzzword “Zero ETL” are also mentioned by GCP [3], Snowflake [4,5], and Databricks [6], they are driving it and also pursuing what they call “no copy data sharing.”
As what are mentioned, these can affirm that Zero ETL is the future of data engineering [7]. However, Zero ETL solutions for open-source or low-budget projects, or for customers who prefer not to use the cloud, still remain an open question. That’s why would like to share a preliminary idea about zero ETL for such projects that are simple, lightweight, and practical.
II. Understanding ETL
The ETL (Extract, Transform, Load) process has been widely used for integrating data from multiple systems since the 1970s. It involves extracting data from various applications or systems, transforming it to fit the desired format, and loading it into a target system. This process is often complex and time-consuming, requiring manual effort for coding and validation.
There are many tools available in the market, e.g. Azure Data Factory, AWS Glue, Azure Databricks, Informatica, IBM DataStage, Talend, Pentaho, Wherescape , Oracle Data Integrator, …
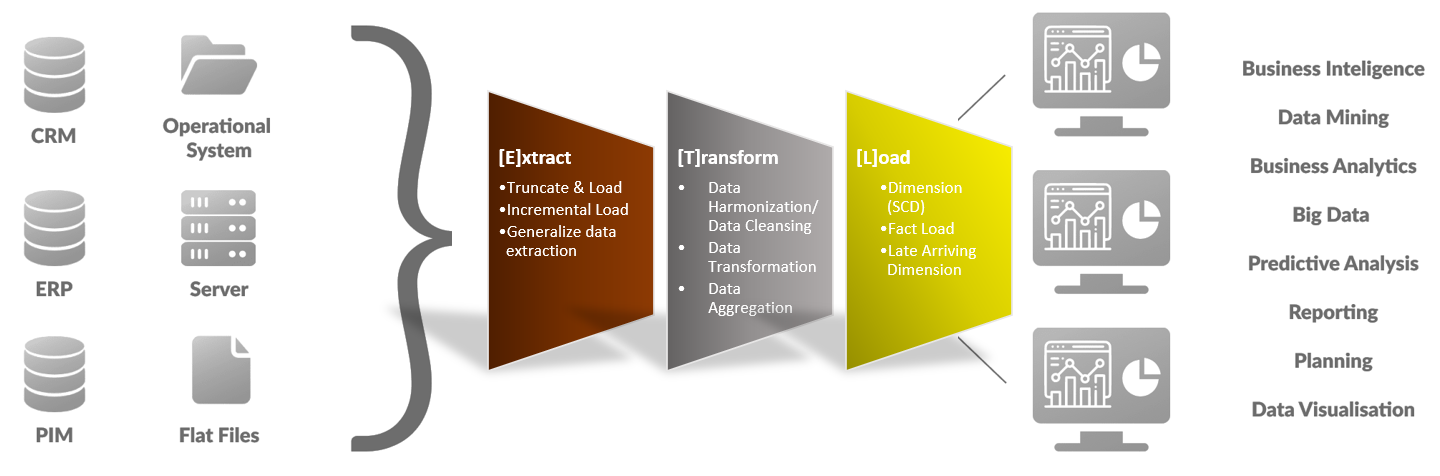
III. Introduction Zero ETL
Zero ETL integration revolutionizes data integration by eliminating the conventional extract, transform, and load (ETL) processes. It allows for the direct transfer of data between systems without the need for intermediary steps of data transformation and cleansing.
By eliminating the complexities of traditional ETL, Zero ETL integration empowers organizations to make faster, data-driven decisions. It enables real-time data synchronization and enables businesses to leverage the most up-to-date information for critical insights and actions. This agile data integration approach contributes to improved productivity, enhanced customer experiences, and increased competitiveness in today’s fast-paced business landscape.
IV. Our idea
1. A high-level approach
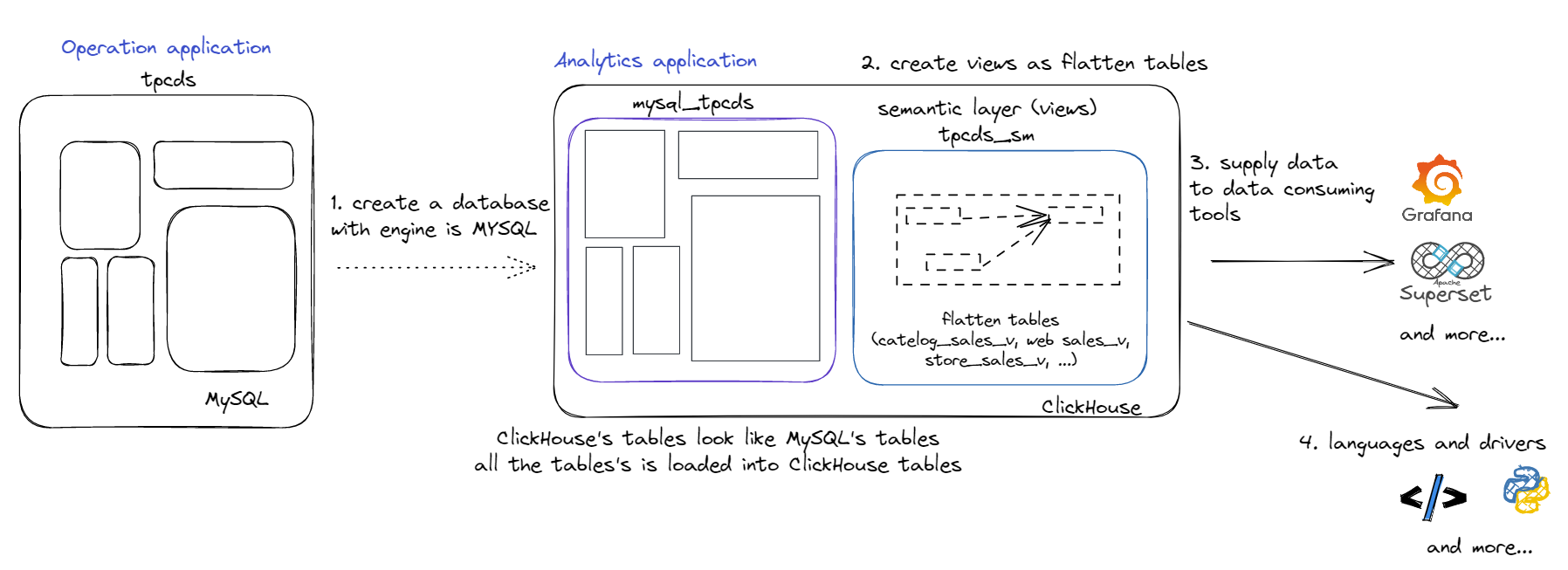
- Create a MySQL engine in ClickHouse (select replicated MySQL tables to ClickHouse*)
- Create flatten queries for BI tools..
- BI tools connect to ClickHouse and visualise data in charts/ graphs/ tables..
- The others app can access ClickHouse via APIs by using common programing languages.
* What is ClickHouse?
The ClickHouse is a column-oriented DBMS. It was initially developed for interactive reporting from non-aggregated user action logs but has since evolved to offer more capabilities. Its main features are column-oriented storage, support for approximate calculations, physical data sorting by primary key, vector calculations, parallelization, linear scalability, compatibility with hard drives, and fault tolerance. It offers client connectivity options, including console client, HTTP API, language-specific wrappers (Python, PHP, Node.js, Perl, Ruby, R), and drivers like JDBC and Golang [8]. And, ClickHouse is supporting replica data from MySQL, Postgres to ClickHouse easily [9].
2. Demonstration
See my next post (coming soon)
V. Conclusions
- Currently, ClickHouse only supports replicating data from MySQL and Postgres, and it will ignore certain DDL commands that it does not support.
- This article presents an initial idea: real-time integration of MySQL data into ClickHouse using a MySQL binlog reading technique. It focuses on small database projects under consideration. For larger databases with multiple clusters and distributed setups, solutions are available from providers like AWS, Google, and others. Another option is utilizing Kafka with the Kafka engine.
- Last but not least, is it ready to drop the “T” in ETL? Let’s see.
VI. References
[1] WS Announces Two New Capabilities to Move Toward a Zero-ETL Future on AWS at https://press.aboutamazon.com/2022/11/aws-announces-two-new-capabilities-to-move-toward-a-zero-etl-future-on-aws
[2] Amazon Aurora zero-ETL integration with Amazon Redshift Preview at https://pages.awscloud.com/AmazonAurora-zeroETL-AmazonRedshift-Preview.html
[3] Zero-ETL approach to analytics on Bigtable data using BigQuery at https://cloud.google.com/blog/products/data-analytics/bigtable-bigquery-federation-brings-hot–cold-data-closer
[4] Introduction to Secure Data Sharing at https://docs.snowflake.com/en/user-guide/data-sharing-intro
[5] Introducing Unistore – A modern approach to working with transactional and analytical data together in a single platform. at https://www.snowflake.com/en/data-cloud/workloads/unistore/
[6] Delta Sharing – An open standard for secure sharing of data assets at https://www.databricks.com/product/delta-sharing
[7] Zero-ETL, ChatGPT, and the future of data engineering at https://www.recognize.com/zero-etl-chatgpt-and-the-future-of-data-engineering/
[8] What Is ClickHouse? at https://clickhouse.com/docs/en/intro
[9] Integrating MySQL with ClickHouse at https://clickhouse.com/docs/en/integrations/mysql