



Key takeaways:
The deployment stage is vital as it enables efficient releases, faster time to market, continuous delivery, consistency, rollback/roll-forward, infrastructure orchestration, and monitoring. Automating the deployment process enhances software delivery, reduces errors, and improves reliability.
By following best practices in the deployment stage of CI/CD, we improve reliability, scalability, security, and efficiency. It ensures consistency, reduces risks, enhances compliance, and fosters effective collaboration. Ultimately, it leads to successful deployments and satisfied end-users.
This article explores the recommended best practices for the deployment stage in CI/CD pipelines.
Deployments are exclusively conducted through the CD platform.
There exists just one essential deployment path exclusively managed by the CI/CD platform. It is imperative to restrict the deployment of production code from developer workstations at the network, access, and hardware levels.
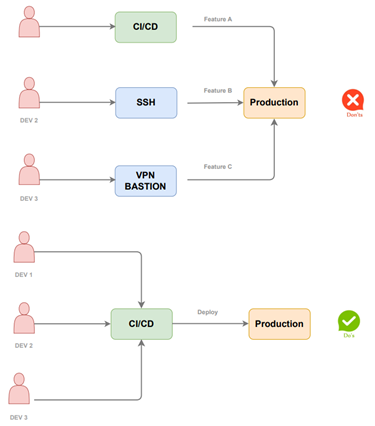
Engaging in such a practice poses significant risks as it undermines the traceability and monitoring capabilities provided by a reliable CI/CD platform. It permits developers to deploy uncommitted features directly to production, which can lead to numerous failed deployments. Many of these failures can be traced back to missing files that existed solely on a developer workstation, without being included in the source control system.
Using progressive deployment patterns.
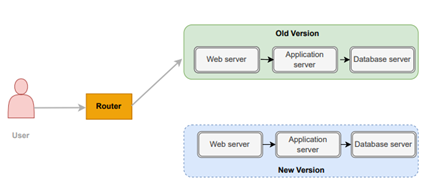
Conventional deployments adhere to an all-or-nothing approach, wherein all instances of an application progress to the subsequent version of the software. While this approach may be straightforward, it complicates the process of rolling back to previous versions.
You should instead look at:
- Blue/Green deployments that deploy a whole new set of instances of the new version but keep the old one for easy rollbacks.
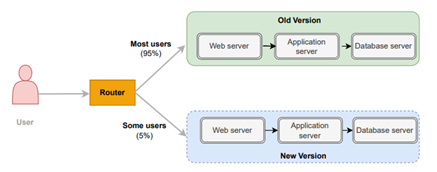
- Canary releases where only a subset of the application instances move to the new version.
Like a Blue/Green deployment, you start by deploying the new version of your software to a subset of your infrastructure, to which no users are routed. When you are happy with the new version, you can start routing a few selected users to it.
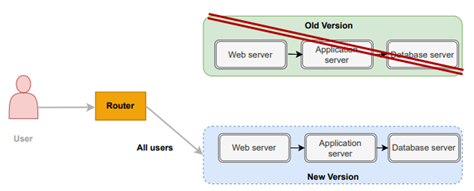
By combining these methods with gradual database deployments, you can significantly reduce downtime during new deployments. Furthermore, performing rollbacks becomes effortless as you only need to modify your load balancer or service mesh configuration to revert to the previous setup, redirecting all users back to the original version of the application.
Using Metrics and logs to detect a bad deployment.
Many development teams rely solely on visual checks or smoke tests as a final step after completing a deployment. However, this approach is insufficient and can easily result in the introduction of unnoticed bugs or performance problems.

The recommended approach involves embracing application (and infrastructure) metrics. This entails the following:
- Detailed logs for application event.
- Metrics that count and monitor key features of the application.
- Tracing information that can provide an in-depth understanding of what a single request is doing.
Once these metrics are established, the impact of deployments should be evaluated by comparing the metrics before and after the deployment. Metrics should not be limited to being a debugging tool for incidents but should serve as an early warning system to detect failed deployments.

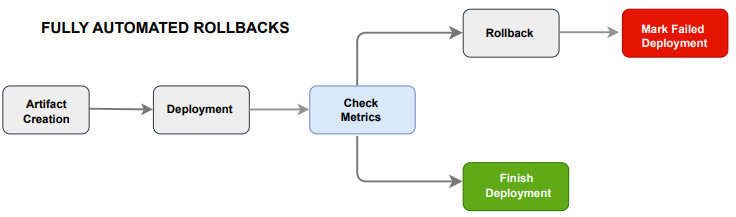
Implementing Automatic Rollbacks mechanisms.
Building upon the previous best practice, once you have established reliable metrics that can validate the success of a deployment, you can further enhance your CI/CD process by implementing automated rollbacks based on these metrics.
Metrics should be integrated into the deployment process seamlessly. After a deployment, the deployment pipeline should automatically reference metrics and compare them to a predefined threshold or their previous values. Subsequently, in a fully automated fashion, the deployment should be marked as completed or potentially rolled back, based on the determined conditions.
Staging mirrors production.
A typical practice is to maintain a single staging environment, also known as pre-production, which serves as the final checkpoint before deploying to the production environment. This staging environment should closely resemble the production environment to facilitate the swift identification of configuration errors and discrepancies before proceeding with the actual deployment in the production environment.
Two effective ways of using a staging environment are the following:
- For small and medium-sized applications, a recommended approach is to create a staging environment dynamically during each deployment by cloning the production environment. This allows for an on-demand staging environment that closely replicates the production setup.
- Utilize a dedicated portion of the production environment, often referred to as “shadow production,” for staging purposes. This approach involves leveraging a specific section within the production setup to perform staging activities.