



Key Takeaways
The data lakehouse plays a pivotal role in today’s data landscape by addressing the challenges of handling big data, enabling real-time analytics, fostering data exploration, supporting advanced analytics and machine learning, ensuring data governance, promoting agility, and offering cost efficiency. It empowers organizations to harness the full potential of their data and gain valuable insights for improved decision-making and business success. In this post, I will present how to build this Lakehouse solution using AWS Glue Service that you can use to accelerate building a Lakehouse architecture on AWS.
I. Data Lakehouse and its benefits
A data lakehouse is an abstract concept that combines the capabilities of a data lake and a data warehouse, providing a unified and flexible platform for storing, managing, and analyzing vast amounts of data. It represents a modern data architecture approach that aims to address the limitations and challenges of traditional data warehousing and data lake solutions
At its core, a data lakehouse serves as a centralized repository for storing structured, semi-structured, and unstructured data in its raw form. This allows organizations to capture and retain large volumes of diverse data types, including real-time streams, log files, social media data, and more.
It also incorporates features typically associated with data warehouses, such as ACID (Atomicity, Consistency, Isolation, Durability) transactions and support for SQL queries. This enables users to perform complex analytics, reporting, and ad-hoc querying on the data lake house, leveraging familiar SQL-based tools and interfaces
By combining the strengths of data lakes and data warehouses, a data lakehouse offers several advantages such as:
- Unified Data Storage
- Flexibility and Agility
- Scalability
- Cost Efficiency
- Enhanced Data Governance
- Advanced Analytics and Insights
II. Build Lakehouse solution using AWS Glue
1. Delta Lake Architecture
Delta Lake is an open-source storage layer that enables building a data lakehouse on top of existing storage systems over cloud objects with additional features like ACID properties, schema enforcement, and time travel features enabled. The stored data file includes three layers:
- Bronze tables: This table contains the raw data ingested from multiple sources like the Internet of Things (IoT) systems, CRM, RDBMS, and JSON files
- Silver tables: This layer contains a more refined view of our data after undergoing transformation and feature engineering processes.
- Gold tables: This final layer is often made available for end users in BI reporting and analysis or use in machine learning processes
The three layers are referred to as a multi-hop architecture below:
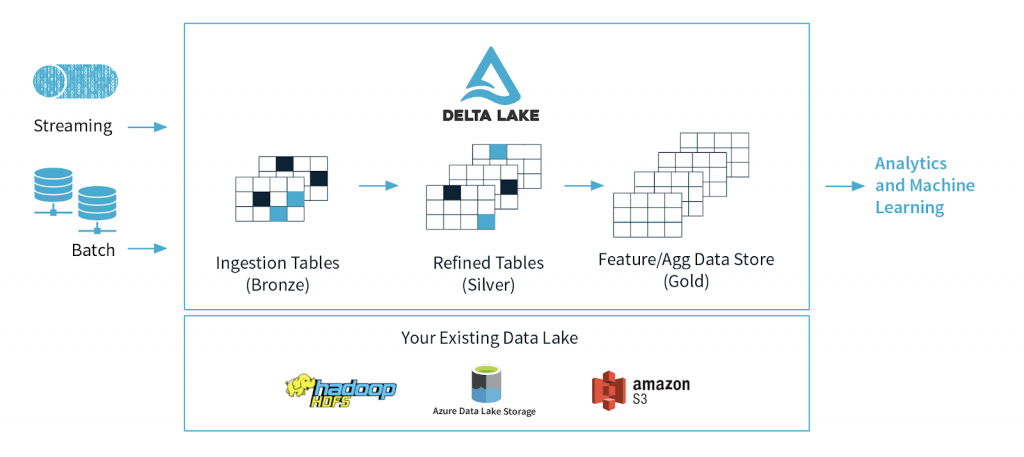
To simplify the process in this post, I assume that we have extracted some raw CSV files (for instance, category.csv) from data sources and put in Bronze layer (raw data formats could be csv, xml, json, parquet, log files, IoT….) and then using AWS Glue to transform and load data into dim_category folder also a table in Gold layer like the architecture below:

Note: Depend on data complexity in real world, we could proceed one more step to refine data (Silver layer) before loading into Gold layer as you see in the diagram above.
2. Preparation
Step 1: On S3, create a nashtechbucket bucket and folder structure as below:

Step 2: Copy Category.csv file to Bronze folder

Step 3: Download Delta.IO library (delta-core_2.12-1.0.1.jar) from link and put into jar folder
Note: Depend on Glue version, we MUST choose a Delta.IO library respectively. In my case, I am using Glue 3.0 so delta-core_2.12-1.0.1.jar is the right one. For more detail, go to the this link
3. Build Glue Job
Step 1: In aws console, search Glue service -> select ETL jobs
Step 2: Select Spark script editor -> Click “Create” button
Step 3: Create script as below
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 | import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job from delta import * from pyspark.sql.session import SparkSession from pyspark.sql.types import StructType,StructField, StringType, IntegerType,BooleanType,TimestampType import uuid import logging from datetime import datetime from pyspark.sql.functions import * from pyspark.sql.functions import sha2, concat_ws from pyspark.sql.functions import lit from dateutil.parser import parse #Create table in lake house(S3) def CreateTable(spark, p_path, p_dbname, p_tablename): db_path = p_path + "/" + p_dbname + "/" spark.sql("CREATE DATABASE IF NOT EXISTS {0} LOCATION '{1}'".format(p_dbname,db_path)) table_path = db_path + p_tablename + "/" spark.sql("CREATE OR REPLACE TABLE {0}.{1} \ ( \ cat_key BIGINT, \ catid INT, \ catgroup STRING, \ catname STRING, \ catdesc STRING, \ update_date TIMESTAMP, \ run_date STRING, \ batch_id INT, \ hash STRING \ ) \ USING delta \ LOCATION '{2}'".format(p_dbname, p_tablename,table_path)) spark.sql("""INSERT INTO {0}.{1} VALUES(-1,-1,'unknown','unknown','unknown','1970-10-01 00:00:00','1970-01-01', 0,'NULL')""".format(p_dbname, p_tablename)) deltaTable = DeltaTable.forPath(spark, table_path) deltaTable.generate("symlink_format_manifest") return True #Using Merge command to update & insert data def UpSertTable(spark, df_Source, p_path, p_dbname, p_tablename): df_Source.createOrReplaceTempView("stg_category") spark.sql(""" MERGE INTO {0}.{1} AS trg USING ( SELECT row_number() OVER (PARTITION BY CASE WHEN dm.catid IS NULL THEN 1 ELSE 0 END ORDER BY stg.catid) as row_num, (SELECT CASE WHEN MAX(cat_key)<0 THEN 0 ELSE MAX(cat_key) END FROM {0}.{1}) AS maxid, stg.catid, stg.catgroup, stg.catname, stg.catdesc, stg.run_date, stg.batch_id, stg.hash_value FROM stg_category stg LEFT JOIN {0}.{1} dm ON stg.catid = dm.catid ) AS scr ON scr.catid = trg.catid --and scr.hash_value <> trg.hash WHEN MATCHED THEN UPDATE SET catid = scr.catid, catgroup = scr.catgroup, catname = scr.catname, catdesc = scr.catdesc, run_date = scr.run_date, batch_id = scr.batch_id, hash = scr.hash_value, update_date = current_date() WHEN NOT MATCHED THEN INSERT(cat_key, catid,catgroup,catname,catdesc,update_date,run_date,batch_id,hash) VALUES(scr.row_num + scr.maxid, scr.catid,scr.catgroup,scr.catname,scr.catdesc,current_date(),scr.run_date,scr.batch_id,scr.hash_value) """.format(p_dbname, p_tablename)) table_path = p_path + "/" + p_dbname + "/" + p_tablename + "/" deltaTable = DeltaTable.forPath(spark, table_path) deltaTable.generate("symlink_format_manifest") return True ## @params: [JOB_NAME] args = getResolvedOptions(sys.argv, ['JOB_NAME']) sc = SparkContext() glueContext = GlueContext(sc) #spark = glueContext.spark_session job = Job(glueContext) job.init(args['JOB_NAME'], args) #Create spark instance spark = SparkSession \ .builder \ .config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \ .config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \ .getOrCreate() #Declare variable here, you can pass them as parameters var_path ='s3a://nashtechbucket/lake/gold' var_target_database = 'data_warehouse' var_target_table ='dim_category' var_run_date = datetime.now().strftime("%Y-%m-%d") var_batch_id = 1 try: table_path = var_path +"/" + var_target_database + "/" + var_target_table + "/" if DeltaTable.isDeltaTable(spark,table_path)==False: CreateTable(spark, var_path, var_target_database, var_target_table) ###Read data source dfBronzeCategory = glueContext.create_dynamic_frame.from_options( format_options={"quoteChar": '"', "withHeader": True, "separator": ","}, connection_type="s3", format="csv", connection_options={"paths": ["s3://nashtechbucket/lake/bronze/"], "recurse": True}, transformation_ctx="S3bucket_node1", ) src_count = dfBronzeCategory.count() #Convet dynamic dataframe to dataframe dfBronzeCategory = dfBronzeCategory.toDF() #Do some transformations df_Category_NotNull = dfBronzeCategory.filter("catid is not NULL") #Create hash column df_Category_NotNull = df_Category_NotNull.withColumn("hash_value", sha2(concat_ws("||", *df_Category_NotNull.columns[1:]), 256)) #Remove duplicated data df_Category_NotNull.createOrReplaceTempView("stg_category") sqlCategory = spark.sql("SELECT *, ROW_NUMBER() OVER (PARTITION BY hash_value ORDER BY catid DESC) as row_num FROM stg_category") new_sqlCategory = sqlCategory.filter("row_num == 1") #Add more 2 columns batch id and run_date new_sqlCategory = new_sqlCategory.withColumn('batch_id', lit(var_batch_id)) df_Source = new_sqlCategory.withColumn('run_date', lit(var_run_date)) trg_count = df_Source.count() UpSertTable(spark, df_Source, var_path, var_target_database, var_target_table) process_status = "SUCCEEDED" end_run = datetime.now().strftime("%d/%m/%Y %H:%M:%S") except Exception as e: error_msg = getattr(e, 'message', repr(e)) process_status = "FAILED" end_run = datetime.now().strftime("%d/%m/%Y %H:%M:%S") sys.exit(0) job.commit() |
Step 4: Select “Job details” tab, set configuration as below:



- Note: Job parameters:
- Key: — conf
- Value: spark.delta.logStore.class=org.apache.spark.sql.delta.storage.S3SingleDriverLogStore –conf spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension –conf spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog
Step 5: Save job
4. Run Glue Job
Step 1: To run job, select job and then click “Run” button. If running successfully, you can see the screenshot below:

Step 2: Go to S3 to check data
As you can see here, data is already loaded in to dim_category folder (also a table in lake house). In this folder, along with data files (parquet files), it also has a _delta_log/ folder which keeps the last checkpoint when we insert, update or delete data.
5. Query table in lakehouse
We can use another services such as Athena or Redshift Spectrum to query table in lakehouse. Here, I use Athena service to demonstrate how to play on it
In AWS console, select Athena and create the table as below:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | CREATE EXTERNAL TABLE `dim_category`( `cat_key` bigint, `catid` int, `catgroup` string, `catname` string, `catdesc` string, `update_date` timestamp, `run_date` string, `batch_id` int, `hash` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.SymlinkTextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 's3://nashtechbucket/lake/gold/data_warehouse/dim_category/_symlink_format_manifest' TBLPROPERTIES ( 'CrawlerSchemaDeserializerVersion'='1.0', 'CrawlerSchemaSerializerVersion'='1.0', 'classification'='parquet') |
If run successfully, you can see the screenshot as below:

Query created table by using T-SQL
Continue modifying category.csv file in S3 by adding one more record and modify old data to new one and then rerun the Glue job.

Although just a few records in data source were updated but old data in table is still not duplicated (quite different from data lake mechanism). In addition, new records were updated and inserted. We gain this benefit because _delta_log/ folder keeps the last checkpoint. This is quite similar to what the relational database engines work.
III. Final thoughts
In this post, I illustrate how to build an ETL job that ingests data from data sources to data lakehouse using AWS Glue Service. There are still some rooms for improvement such as passing parameters, writing log, count number of records from sources and destination. But overall, it provided a general picture how to build a job from scratch. By taking advantage the lake house solution properly, not only does it help organizations to save significant cost but still adapt to their needs such as decision-making, advanced analytics, machine learning and AI.
NashTech have recently built modern data solutions using different tech stacks like AWS Redshift, Azure Synapse, and Databricks. If you are interested in this topic and would like to have a deep dive session on how to apply these solutions to accelerator your data journey, please access to Nashtech Accelerator (nashtechglobal.com) for more information and don’t hesitate to book a demo to discuss with our Data experts.