



We used to ask each other: “What happen if somebody just went and kicked over a rack or unplugged something or somebody didn’t update assert, how would our application respond?” when we deployed an application on the Internet and could not get a concise answer. We just hoped that everything would be fine, there would be no incidents, no interruption, no failures happening. Things are far more complicated when we deal with scaled-distributed systems nowadays. Let’s discuss about Chaos Engineering and how it helps us gaining confident about resilience of these kinds of systems.
Chaos Testing (Chaos Engineering)
According to Wikipedia, Chaos engineering is the discipline of experimenting on a system in order to build confidence in the system’s capability to withstand turbulent conditions in production.
Chaos engineering can be used to check the resilience of a software system (its ability to tolerate failures while still ensuring adequate quality of service) against infrastructure failures, network failures, and application failures.
How does it work?
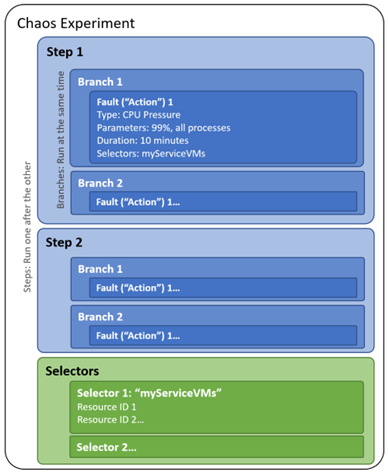
Chaos Engineering use Experiments to test the resilience of the system.
Firstly, start with a steady state (by observing the system and find out.
Secondly, make a hypothesis (assume that the steady state will continue even there’re network/hardware failures).
Thirdly, design a scenario with steps by steps injecting faults to mimic possible failures in real life. Lastly, run the experiments and observe the results to confirm or disprove the hypothesis.
Lastly, run the experiments and observe the results to confirm or disprove the hypothesis.
An example about failure to be injected:
- Scenario: Data center outage Simulation.
- Description: Simulate a full data center outage by shutting down an increasing number of nodes
- Hypothesis: After enacting our disaster recovery plan, we will restore full service within 5 minutes
Design:
- Backhole: 10 minutes – 1 host
- Backhole: 10 minutes – 2 hosts
- Backhole: 10 minutes – 3 hosts
Advantages
- An obvious advantage of Chaos Engineering is that it can help finding the weakness of the system.
- Chaos Engineering help us to reproduce some outages in production environment and take actions to prevent them.
- It builds confident on the resilience of the system, just like the way we inject a vaccine shot to boost up the immune system in our body.
Disadvantages
- Implementing Chaos experiment may take extra cost.
- Injecting faults to a product sure can cause harm, and things may go far more than you expected. Especially when we do in production, we may have no chance to roll back the changes.
Which kinds of systems that can get benefits from Chaos Engineering?
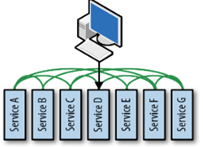
Chaos Engineering is especially needed for scaled-distributed systems, where it’s hard to control the infrastructure as it is constantly changing. The relationships between the services are too complex to predict exactly how the whole system behave after a failure in a single service.
On the other hand, Chaos test should not be performed in small systems or desktop software.
When should we apply this principles?
- New code changes in a deployment.
- New dependencies.
- Observe changes in usage patterns.
- Mitigate problems/ issues.
Chaos Engineering vs Performance test?
One may think that if Chaos Engineering is all about how the system react to the disruption of the servers, handling disk space, why don’t we run performance test and find out the thresholds of the system? Well, we always do performance test in a static environment only, with a specific configuration and the results can be totally different if we change any parameters. Chaos Engineering measure how the system reacts in a random failure, and what we achieve from Chaos experiments is how resilience our system is.
Is it all about breaking stuff?
Not really, we’re not breaking stuff unstructured, we do have plan for that. The most challenge part is to find out which one to break to detect the flaws of the system.
How to get started?
Knowing the benefits of Chaos Engineering, but getting it started is not a piece of cake.
Firstly, there should be a distributed system that we can work on, a system that we have good understanding of its service architecture (ideally to have either visual map or mental model of what the known dependencies are and where these services connect to each other).
Secondly, we should have good practices around understanding blast radius, ensuring that how to control impact of an outage in our environment.
Then, we must understand production environment, which kinds of issues usually happen, then we can focus our experiments on.
Finally, we can start to build the very first experiment, observe the output, analyze the metrics.
Then the team can consider taking actions accordingly.
Tools
- Chaos Monkey
- Chaos Monkey an open-source tool, it is the oldest chaos engineering tool.
- Benefits: It’s a simple tool, mainly focuses on terminating virtual machine instances and replicating unpredictable production incidents.
- Its only drawback is lacking recovery or rollback mechanism.
- Chaos Mesh:
- Another open-source tool
- It can be easy to integrate into Kubernetes infrastructure.
- The API made it easy to version, manage and automate chaos experiments.
- Chaos Mesh also includes a dashboard to keep track of experiments
- Gremlin
- It’s a commercial tool.
- Gremlin includes native integrations for Kubernetes, AWS, Azure, Google Cloud and even bare-metal infrastructure.
- Its benefit is the platform can autodetect infrastructure components and make experiment recommendations to identify common failure modes.
- The tool can also cut off experiments automatically when systems become unstable
- It’s a commercial tool.
- Chaos studio:
- It’s a commercial tool. But it has no upfront costs or fees Pay as you go based on experiment execution—chaos engineering experiments are charged based on the duration that your experiment actions run across each target or resource.
- It can be easily integrated with Azure applications.
Summary
To sum up, chaos engineering is a way to learn how our systems react with failures. It helps us building trusts on the system, identifying potential issues, and handling them to reduce lost and damages to our applications.
Reference: