



In this blog we know about Data Warehouse, Data Lakes and Data Lakehouse and Compare there pros and cons of all the Infrastructures
Data Warehouse
A relational database management system (RDBMS) concept called a data warehouse was created to address the needs of transaction processing systems. Any centralised data repository that may be searched for commercial advantages can be broadly characterised as such. It is a database that holds data intended to satiate inquiry-based decision-making.
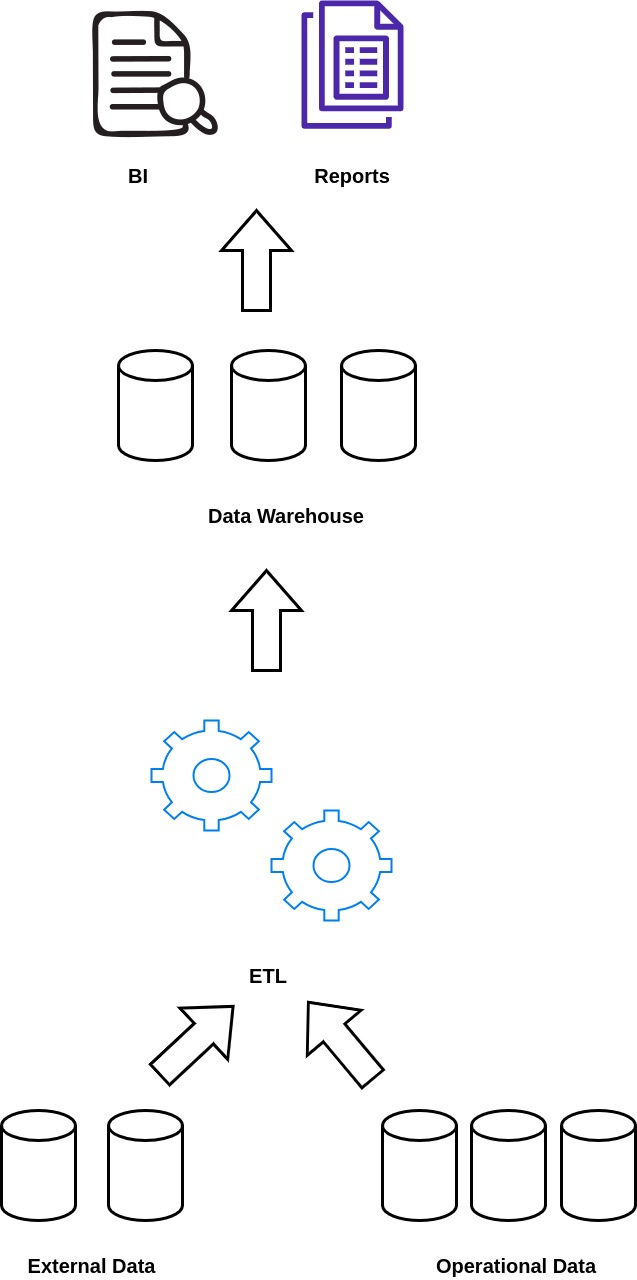
Pros:
- Business Intelligence (BI)
- Analystics
- Structured and clean data
- Predefined Schema
Cons:
- NO Supports for semi or unstructured data
- Inflexible schemas
- Struggled with volume and velocity upticks
- Long processing time
Data Lakes
A data lake is a sort of storage repository create specifically to collect and hold vast amounts of unprocessed data of various kinds. Structured, semi-structured, and unstructured data are all possible. The data can be use in business-related machine learning or artificial intelligence (AI) algorithms and models once it has been place in the data lake. After processing, it can also be move to a data warehouse.
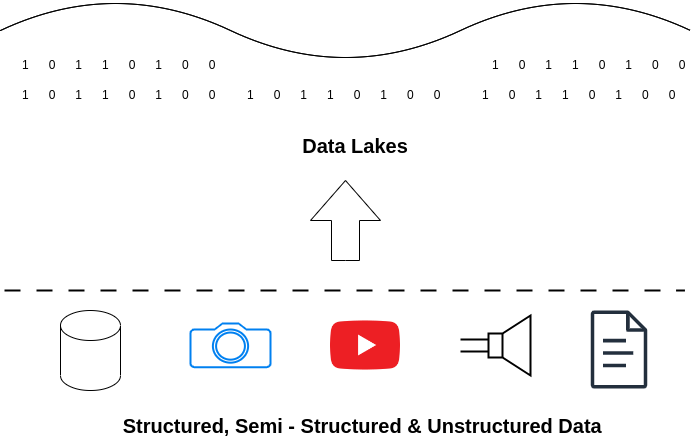
Pros:
- Flexible data storage
- Streaming support
- Cost efficient in the cloud
- Support for AI and machine learning
Cons:
- No transactional support
- Poor data reliability
- Slow analysis performance
- Data governance concerns
- Data warehouses still needed
Data Lakehouse
Data lakehouse is one platform to unify all your data, analytics and AI workloads. The data lakehouse was develop as an open architecture combining the benefits of data lakes with the analytical power and control of a data warehouse. Built on datalakes a data lakehouse can store all data of any type together becoming a single reliable source of truth providing direct access for Artificial Intelligence (AI) and Business Intelligence (BI) together.
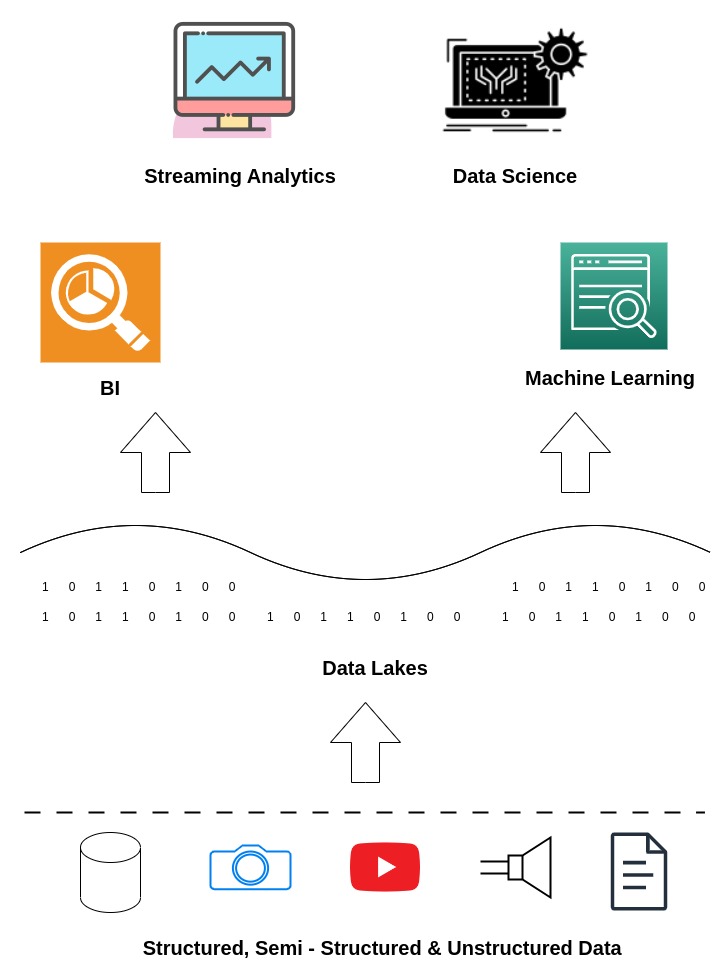
Data Lakehouses like the Databricks Lakehouse platform offer several key features :-
- Transaction Support : includes ACID transactions for concurrent read and write interactions.
- Schema Enforcement & Governance : provides for data integrity and robust and auditing needs.
- Data Governance : to support privacy regulations and data use metrics.
- BI Support : to reduce the latency between obtaining data and drawing insights.
- Decoupled Storage for compute : each operates on their own clusters allowing them to scale independently to supports specific needs.
- Open Storage formats : such as Apache Parquet which are open and standardised so a variety of tools and engines can access the data directly and efficiently.
- Support for diverse data types : so business can stores refine analyse and access semi-structured, structured and unstructured data in one location.
- Support for diverse workloads : such as data science, machine learning and SQL analytics to use the same data repository.
- End-to-End Streaming : for real-time reports removes the need for a separate system dedicated to real-time data applications.
Pros:
- The Lakehouse supports thee work of Data Analysts, Data Engineers and Data Scientists all in one location
- The Lakehouse essentially is the modernised version of a Data Warehouse providing all the benefits and features without compromising the flexibility and depth of a Datalake.