




Introduction
In the ever-growing world of data, two key storage solutions exist: data lakes and data warehouses. While both serve the purpose of data storage, they differ significantly in their structure, purpose, and use cases. In this blog post, we will explore specifics of data lakes and data warehouses, providing a clear distinction between the two and helping you determine which solution best suits your needs.
Understanding Data Lakes
It’s a central repository designed to store massive amounts of data in its native format. This includes structured data (think rows and columns in spreadsheets), semi-structured data (like log files with some organization), and unstructured data (text documents, images, audio, video etc.). This data repository allows for subsequent processing and analysis of data. The key advantage of a data lake is its flexibility and scalability. Data lakes also ensure consistent data availability across multiple applications.
Benefits
- Flexibility & Scalability: Store anything, everything, forever. No rigid structures to limit future possibilities.
- Cost-Effective: Raw data is cheaper to store than processed data in warehouses.
- Better Decisions: More data means better insights. Drive smarter choices across your organization.
Challenges
- Data Quality: Since data is stored in its original format, issues like duplicates, inconsistencies, and errors can arise. Cleaning and organizing the data require additional processing before it can be effectively analyzed.
- Complexity: Managing and navigating a vast amount of unstructured data can be overwhelming. Specialized skills and tools are needed to sift through the data and extract meaningful insights.
- Performance: Querying raw data can be slower compared to querying structured data in a data warehouse. This can impact response times for data scientists and analysts.
Examples
- Amazon S3: Amazon Simple Storage Service is often used as a data lake due to its scalability and flexibility in handling large volumes of data from various sources.
- Azure Data Lake Storage: Provides a secure data lake functionality built on Azure Blob Storage, optimized for analytics workloads.
Use Cases
1. Machine Learning:
-
- Customer Churn Prediction: Analyzing customer behaviour data from various sources (website clicks, purchase history etc.) can help identify potential customers churn.
- Fraud Detection: Data lakes can process financial transactions, log files etc. to identify patterns for fraudulent activities.
2. Internet of Things (IoT) Data Storage and Analysis:
-
- Connected Cars: Data from sensors in connected vehicles can be used to analyze driving patterns, improve fuel efficiency, and develop new features for autonomous driving.
- Wearable Devices: Fitness trackers generate health data that can be stored in a data lake for personalized health insights.
3. Data Exploration and Research:
-
- Market Research: Companies can use data lakes to analyze customer demographics, social media sentiment to gain insights into customer preferences.
- Product Development: Data lakes can store user feedback, bug reports, and usage data to inform product development strategies and identify areas for improvement.
Understanding Data Warehouse
A data warehouse resembles a well-organized library. It’s a subject-oriented repository that stores historical data specifically formatted for business intelligence (BI) and analytics.
Key Features
- Structured Data: Data in a warehouse goes through a rigorous cleansing and transformation process. It’s organized into a defined schema (structure) with consistent formats and relationships between data points. This structured approach allows for:
- Fast Query Performance: Structured data enables rapid retrieval and analysis of information, making it ideal for generating reports, creating dashboards, and monitoring key performance indicators (KPIs).
- Data Governance: The defined schema ensures data consistency and quality across the warehouse. This leads to reliable insights that can be trusted for critical decision-making.
Limitations
- Limited Data Variety: The focus on structured data can exclude valuable insights hidden within unstructured sources like social media or customer reviews. This can limit the scope of analysis.
- Implementation Costs: Setting up and maintaining a data warehouse can be expensive. The hardware, software, and skilled personnel required for data transformation and ongoing management add to the overall cost.
- Limited Flexibility: The predefined schema might not adapt quickly to evolving business needs or new data sources. Adding new data types or changing the structure can be a complex and time-consuming process.
Examples
- Amazon Redshift: Amazon Redshift is a fully managed, data warehouse service in the cloud. It enables fast query performance and scalability, making it suitable for big data analytics.
- Google BigQuery: Google BigQuery is a serverless, highly scalable, and cost-effective multi-cloud data warehouse designed for business agility. It allows for super-fast SQL queries, making it ideal for interactive querying.
- Snowflake: Snowflake is a cloud-based data warehousing solution that offers data storage, processing, and analytic solutions. Its architecture enables concurrent, secure, and scalable data sharing and analysis across multiple cloud platforms.
- Oracle Autonomous Data Warehouse: Oracle Autonomous Data Warehouse is a cloud data warehouse service that uses machine learning to automate provisioning, securing, tuning and scaling. It helps organizations manage large volumes of data.
- Teradata: Teradata is an enterprise data warehouse solution that provides high scalability and parallel processing capabilities. It supports complex queries and large-scale data analytics.
Use Cases
- Business Intelligence and Reporting: Data warehouses aid business intelligence systems. They aggregate data from various sources, providing a consolidated view that enables detailed reporting and analysis.
- Supply Chain Management: Data warehouses improve supply chain management by providing insights into inventory levels, supplier performance etc.
- Healthcare Analytics: In healthcare, data warehouses integrate patient data from various sources such as electronic health records (EHR), billing systems, and clinical trials.
- Retail and E-commerce: Retailers use data warehouses to analyze customer purchasing patterns, manage inventory, and optimize pricing strategies.

Conclusion
Summarized differences between Data Lake and Data Warehouse:
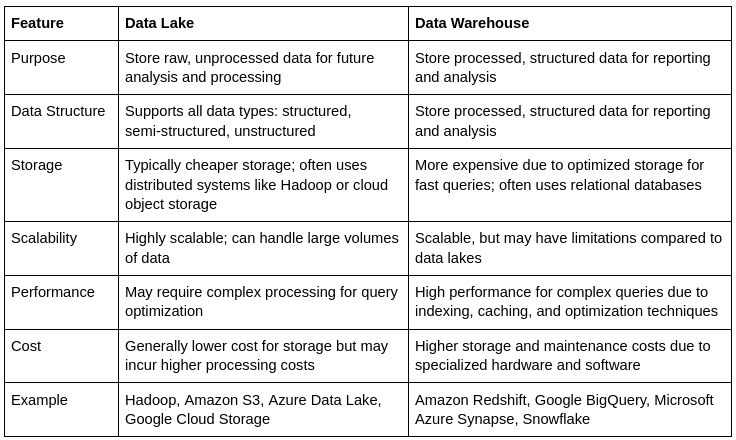
When to use What?
Data lakes are ideal for storing and analyzing a wide variety of data types, including structured, semi-structured, and unstructured data, making them suitable for big data and real-time analytics and cost-effective storage of large datasets. On the other hand, data warehouses are optimized for handling structured data from transactional systems, supporting business intelligence, regular reporting and historical data analysis. Choose a data lake for flexible, large-scale data management and a data warehouse for high-performance querying and consistent, structured data analysis.
References
- Microsoft Post
- SimpliLearn Post – https://www.simplilearn.com/data-lake-vs-data-warehouse-article