



Drawing from my experience in handling various ETL testing projects, I observed that the presence of substandard raw data sources significantly underlies inaccurate data, wrong business rule within the Production Testing environment. This leads to increased expenses related to investigation, rectification, and testing. From my perspective, the primary issue often lies in the inadequate attention given to data quality testing. So, today I would like to share the importance of data quality testing.
What is the importance of Data Quality Testing?
The quality of data determines how well it supports business goals across various areas, such as operations, planning, and decision-making. When data is of low quality, it fails to effectively serve the intended purposes of a business. Decision-makers typically rely on data to inform their decisions, but numerous studies indicate that poor or uncertain data quality can significantly impede effective decision-making in practice. On the other hand, high-quality data empowers models to make more accurate predictions and generate dependable outcomes, thereby cultivating trust and confidence among users.
The figure below illustrates the detrimental impact of inadequate data quality.
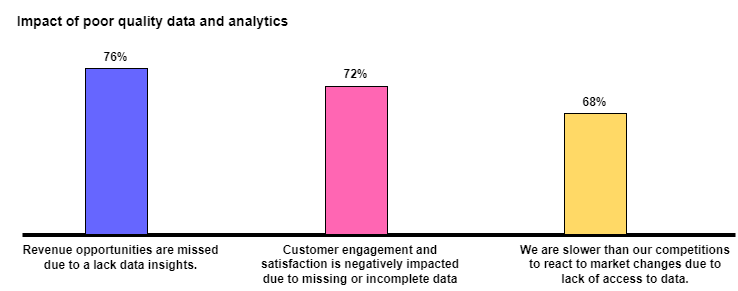
Data Quality Testing Challenges
Many companies face challenges with bad data, often underestimating its severity. Two primary reasons contribute to bad quality data.
Manual data entry
In numerous systems and organizations, it remains common practice for employees to manually input specific types of data. However, this manual data entry approach poses the risk of errors, whether they are deliberate or accidental.
Furthermore, inconsistencies may arise when entering units of measurement, where they are either written out in full or abbreviated. In certain cases, manual data entry can lead to duplicate records if multiple employees are involved in the same project.
Error-Prone Data Migration
When data is transferred from multiple systems, files or databases, there is a risk of encountering errors and duplication of records. Additionally, merging data from diverse databases with varying data schemas can present challenges. Throughout the data format conversion process, errors may occur, potentially resulting in the loss of valuable information.
What are the measures of Data Quality Testing?
Data quality testing can be evaluated using various metrics, including accuracy, consistency, completeness, timeliness, and validity. Among these measures, accuracy holds significant importance as it indicates the proximity of our results to the reality they represent.
Below are 6 key measures during the data quality assessment:
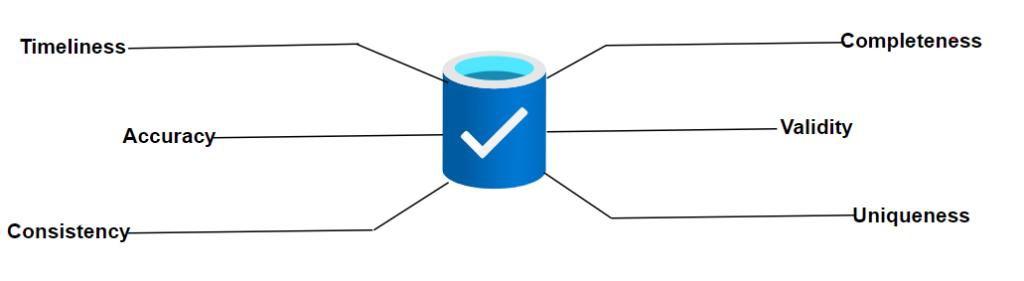
1. Completeness: Completeness refers to the data’s capacity to furnish all necessary values accurately.
2. Timeliness: This dimension refers to data availability, including the need to keep data current. To ensure constant accessibility, data should be updated in real-time.
3. Consistency: Consistency gauges the alignment between individual data points extracted from two or more data sources. When two data points conflict, it indicates potential inaccuracies in one or both records.
4. Uniqueness: Data collection must follow the company’s business rules and parameters. All data must be in the right formats and within the acceptable range.
5. Validity: Validity assesses how well data adheres to established standards. In other words, data entered a specific field must be of the appropriate type; if an incorrect data format is used, the data may become unusable. It’s important to validate that every data piece adheres to the required type and format.
6. Accuracy: The determination of data accuracy hinges on the extent of concurrence between the values presented and the information obtained from reliable sources.
Best Practices for Data Quality Testing
The pursuit of enhanced data quality testing is a common objective for organizations. Here are some steps we can adopt to bolster data quality, leading to increased effectiveness and efficiency in business processes.
- Understand Data
Improving data quality requires a thorough understanding of the data we have. To achieve this, a formal data quality assessment is necessary. The assessment involves determining the following:
– What data do we collect?
– Where is the data located?
– Who has used to the data?
– What is the current format of the data, including structured and unstructured data, etc.?
Those questions provide valuable insights into our data, allowing us to identify areas for potential improvement. With this understanding, we can take targeted actions to enhance data quality, ensuring its accuracy and usability. - Define Strategy and Set data quality standards Establishing a data quality strategy and data quality standards is vital for our organization. While achieving 100% accuracy might be challenging, defining suitable standards is essential to ensure data remains accurate and relevant. Different types of data and varied use cases may necessitate distinct data quality standards. Tailoring these standards enables us to optimize data quality based on its specific purpose and utility.
- Correct Data Errors Up Front
To enhance data quality, we must first proactively address data errors in source systems through effective approaches below.
– Implement Tools (Macro) for Historical Data: In cases where historical data needs to be transferred to standardized formats, the development team can create macro tools. These tools automate the transformation process, ensuring data consistency and accuracy.
– Create New Templates/Tools for Upcoming Data: For new data entries, it is beneficial to develop new templates or tools to assist business users. These tools can provide data validation rules, drop-down menus, or other features that enhance data entry accuracy. Additionally, improving the application used for data processing can ensure that clean and up-to-date data is available for all future monthly data uploads, reducing the chances of human errors during manual data processing.
– Use Automation Tools: The ever-growing volume and complexity of data pose challenges for continuous monitoring and improving data quality. However, employing data quality tools can simplify and enhance the process, making it more efficient to monitor and improve data quality.
+ Data Buck by First Eigen is an automated system that improves data quality. It identifies issues and cleans up or deletes bad data faster and more efficiently than manual methods. This tool automates more than 80% of the data monitoring process.
+ Data Ladder is a well-known brand specializing in end-to-end data quality solutions, encompassing data cleansing, data profiling, and deduplication functionalities.
+ Informatica provides metadata-driven machine learning capabilities that effectively identify data errors and inconsistencies. With this tool, data stewards and other users can automate various data quality tasks and set up reminders for ongoing data maintenance. - Do regular Data Quality reviews: Regularly conducting data quality reviews within organization is crucial to maintaining effectiveness. These reviews provide insights into our progress and areas that require improvement, helping us track and enhance data quality.
Conclusion
Maintaining high data quality levels offers several advantages to our organizations. It helps minimize the costs associated with identifying and rectifying bad data in the systems. By ensuring good data quality testing, companies can prevent operational errors and business process breakdowns, leading to reduced operating expenses and increased revenues. Furthermore, good data quality enhances the accuracy of analytics applications, resulting in improved business decision-making.
Reference
[1] The State of Data Management – The Impact of Data Distrust | SnapLogic
[2] What is Data Quality Assessment? Why it is Important? (theecmconsultant.com)
[3] The Role of ML and AI in Data Quality Management (firsteigen.com)
[4] What is Data Quality ? Dimension, Challenges and Best Practices. (piloggroup.com)