



Database Strategies for Microservices
In the domain of microservices architecture, one of the critical decisions developers face is how to manage data effectively. Unlike monolithic applications, where a single database often suffices, microservices demand a more nuanced approach to data management. In this blog, we’ll explore various database strategies tailored for microservices, examining their advantages, challenges, and real-world examples.
Understanding Microservices Data Management
Microservices architecture decomposes applications into smaller, independent services, each responsible for specific business capabilities. Consequently, each microservice often has its database, enabling autonomy, scalability, and agility. However, this decentralization introduces challenges, such as data consistency, service coupling, and managing cross-service transactions.
Database Strategies
1. Database per Service
In this strategy, each microservice has its dedicated database, tailored to its specific data needs. This approach fosters service autonomy, simplifies schema changes, and minimizes the risk of affecting other services. For instance, a customer microservice may use a relational database to manage customer data, while a product microservice might opt for a NoSQL database to handle product catalogues.
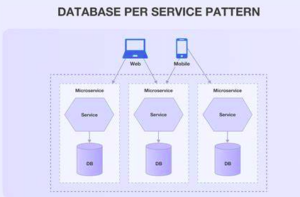
Example: Amazon follows this strategy in its e-commerce platform. Each service, such as ordering, inventory, and user management, has its dedicated database, allowing teams to iterate and scale independently.
2. Shared Database
Contrary to the database per service approach, shared databases entail multiple services accessing the same database instance. While this simplifies data access and ensures consistency, it can lead to tight coupling between services and hinder independent scaling.
Example: A blogging platform may adopt a shared database approach, where multiple services, such as articles, comments, and users, share a common database instance to maintain data consistency across various components.
Challenges and Considerations
While these strategies offer flexibility and scalability, they come with their set of challenges:
– Data Consistency: Maintaining data consistency across distributed databases requires careful orchestration and synchronization mechanisms.
– Service Coupling: Shared databases can lead to tight coupling between services, making it challenging to evolve and scale independently.
– Operational Complexity: Managing multiple databases adds operational overhead, including provisioning, monitoring, and backups.
– Transactional Boundaries: Ensuring transactional consistency across multiple databases necessitates adopting distributed transaction patterns or employing compensating transactions.
Summary
Choosing the right database strategy is crucial for building resilient and scalable microservices architectures. Whether opting for a database per service, shared databases, or polyglot persistence, each approach comes with trade-offs that must be carefully considered based on specific project requirements and constraints.
By understanding these database strategies and their implications, developers can design robust microservices architectures capable of handling the complexities of modern distributed systems effectively.
In conclusion, embracing a thoughtful database strategy is essential for unlocking the full potential of microservices, enabling teams to build scalable, resilient, and agile systems that can evolve and adapt to changing business needs.