



In the world of software development, we often hear about the shift from monolithic to microservices architecture. If a monolithic application is like a large house where every room and function is under one roof, microservices is like building a neighborhood where each house (service) has its own specific job and communicates with the others. This transition offers many benefits, but it also presents a major challenge: How do these “houses” operate independently while still coordinating seamlessly to create a robust and scalable “neighborhood”?
When we talk about microservices, we’re not dealing with a single application anymore. Instead, we’re orchestrating a distributed system made up of many smaller services – each with its own responsibility, its own database, and its own way of talking to others.
But here’s the catch: as soon as these services start depending on each other, things can get messy. If one service goes down or evolves in the wrong way, it can trigger a domino effect across the entire system.
This article will outline three core principles to help you design and manage service dependencies effectively, ensuring your microservices system remains flexible, resilient, and maintainable.
Principle 1: Design for High Cohesion
Just as in object-oriented programming, the principle of loose coupling, high cohesion is a guiding star for microservice design. A service is considered highly cohesive when it focuses on a single, specific task or business domain. This adheres to the Single Responsibility Principle (SRP) – the idea that each service should be responsible for a single, well-defined task and do it exceptionally well.
Consider an e-commerce system. The Order Service would be solely responsible for managing orders. It would own its own dedicated database containing Orders and OrderItems tables. This is known as the Database per Service pattern. When the Delivery Service needs information about an order, it is not allowed to access the Order Service’s database directly. Instead, it must send a request through a RESTful API provided by the Order Service.
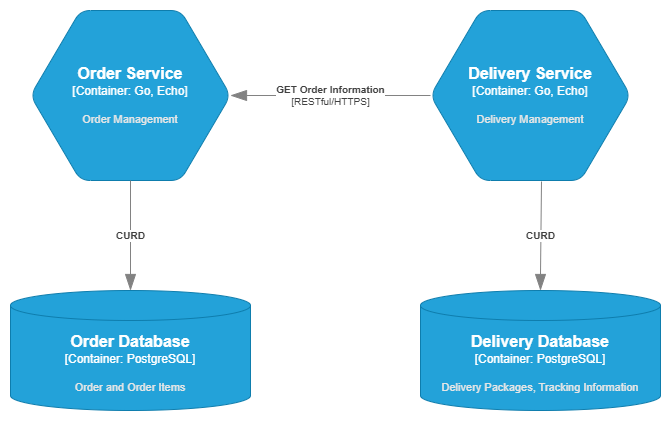
This approach ensures data integrity and service autonomy. All CRUD operations on orders must go through the Order Service, preventing unexpected changes from external services and making the service easier to scale and maintain independently.
Principle 2: Achieve Loose Coupling in Communication
The way services communicate with each other is crucial to the system’s overall flexibility. To achieve loose coupling, we must design interactions so that one service can change without breaking others.
Synchronous Communication
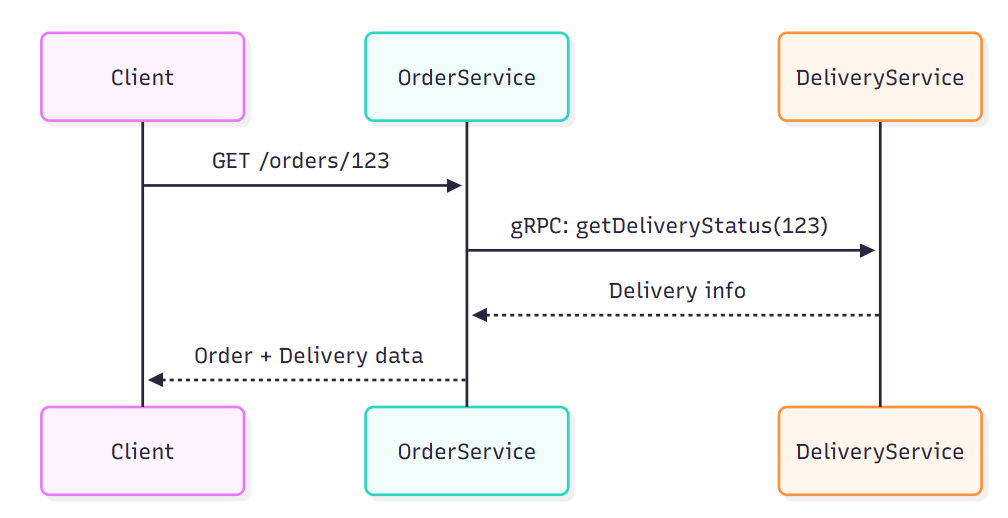
When an immediate response is required, RESTful APIs and gRPC are common choices. To minimize dependencies, services must strictly adhere to interface contracts defined using OpenAPI or Protocol Buffers. This ensures services don’t depend on each other’s internal implementation details, aligning with the Dependency Inversion Principle.
A more advanced solution is to use a Service Mesh (e.g., Istio). Instead of services calling each other directly, they send requests through a Sidecar proxy. This sidecar acts as an “intelligent traffic manager,” handling complex tasks such as:
- Version-based routing:
/v1goes to Order Service version 1, while/v2goes to version 2. - Rate limiting and automatic retries.
- Circuit breakers: Preventing cascading failures when a service is overwhelmed or failing.
With this approach, services don’t need to “know” about each other’s addresses or versions, making them independent and easier to change.
The Interface Segregation Principle is also essential in this context – each service should expose only domain-relevant endpoints and keep its interface concise and focused. For example, an Order Service might expose an API like the following:
# OpenAPI 3.0 snippet with versioned base URL
openapi: 3.0.3
info:
title: Order Service API
version: 1.0.0
servers:
- url: /v1
paths:
/orders:
get:
summary: Get list of orders
responses:
'200':
description: OK
/orders/{order-id}:
get:
summary: Get order by ID
parameters:
- in: path
name: order-id
required: true
schema:
type: string
responses:
'200':
description: OKAsynchronous Communication
Asynchronous communication is a key enabler of loose coupling in microservices architecture. It allows services to communicate without waiting for immediate responses, which improves resilience, scalability, and independence between components.
Point-to-Point Messaging Pattern:
A common asynchronous approach is the point-to-point messaging pattern, where Service A sends messages directly to Service B through a dedicated queue. While this approach decouples services at runtime, it introduces tight coupling at the integration level – both services must share an agreed-upon message schema and communication channel. Any schema change in the producer can directly affect the consumer, making the system harder to evolve.
Event-Driven Architecture with Pub/Sub Pattern:
When an immediate response isn’t needed, asynchronous communication with Event-Driven Architecture is the optimal choice for maximizing independence. The Publish-Subscribe (Pub/Sub) pattern is the heart of this architecture:
- A producer (publisher) emits an event to a topic.
- Consumers (subscribers) independently listen for events from that topic.
- Crucially, the producer has no awareness of how many consumers are listening.
For example, when an order is created, the Order Service simply emits an ORDER_CREATED event to the /orders/v1 topic. The Promotion Service and the Inventory Service listen for this event and automatically perform their tasks (validating promo codes and reserving stock).
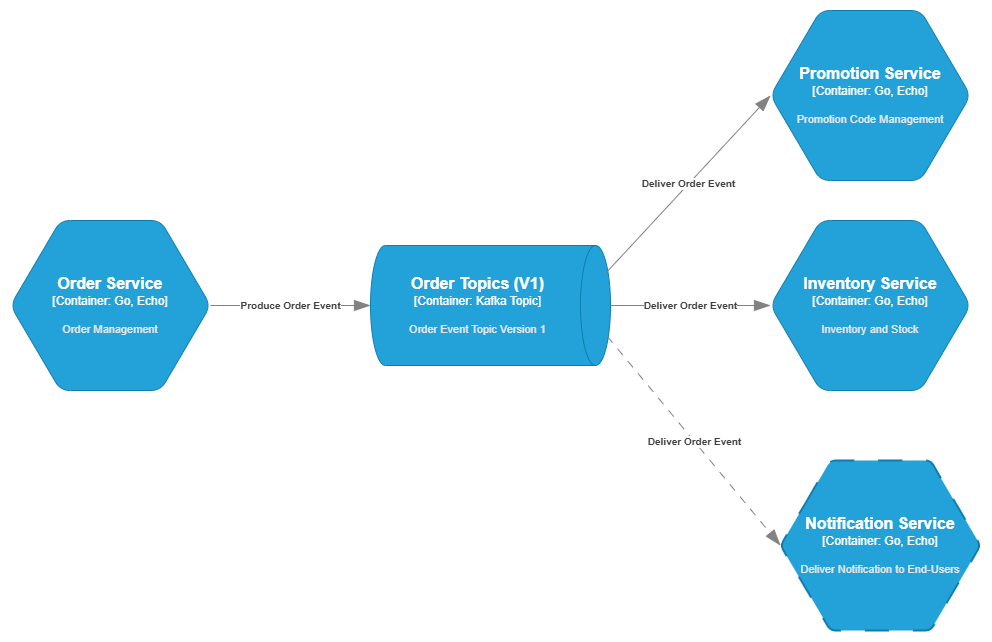
If you later need to add a Notification Service to send confirmation emails to customers, you just add a new consumer that listens for the ORDER_CREATED event without changing a single line of code in the Order Service. This adheres to the Open/Closed Principle – the system is open for extension but closed for modification.
Event Transformation and Consumer-Specific Queues:
To further decouple producers and consumers, it’s beneficial to introduce an event transformation layer:
- Events from a topic are transformed into consumer-friendly messages.
- These transformed messages are pushed into consumer-specific queues.
- Each consumer reads from its own queue, leveraging features such as retry, FIFO ordering, and dead-letter queues as needed.

This architecture separates event schema (producer-owned) from message schema (consumer-owned), reducing dependencies and enabling each service to evolve independently.
Principle 3: Manage and Visualize Dependencies
As microservices systems grow in scale and complexity, managing and understanding the relationships between services becomes increasingly challenging. In particular, for business workflows that span multiple services, tracing the end-to-end execution path – especially when failures or latency occur – is critical for operational awareness and debugging.
Distributed Tracing
To address this, traceability plays a key role. Distributed tracing tools (e.g., OpenTelemetry, Jaeger, Zipkin) allow engineers to follow a business request across multiple services and identify where bottlenecks or failures occur. This level of observability is essential for maintaining service-level objectives (SLOs), debugging production incidents, and understanding how services interact during real-world workflows.
Service Mesh and Dependency Graph
Service Mesh platforms like Istio not only manage traffic but also automatically generate a real-time dependency graph. This graph gives development and operations teams a clear, visual representation of how services are interacting, making it easier to optimize performance and respond to incidents. This includes:
- Centralized routing: Directing traffic to specific service versions, handling request retries, timeouts, and failovers.
- Rate limiting and circuit breaker patterns: Protecting services from overload and failure cascades.
- Versioning and traffic shaping: Enabling progressive delivery strategies like blue-green deployments or canary releases.
Visualizing Service Dependencies
Service Meshes (e.g., Istio, Linkerd) often integrate with observability tools to automatically generate real-time visualizations of service-to-service dependencies. These dependency graphs are built from communication traces, giving technical teams a clear view of which services interact, how often, and under what conditions. This visibility is essential for architecture reviews, performance optimization, and incident response.

Integration with Observability Platforms
Modern service meshes support integration with external observability systems such as Prometheus, Grafana, Datadog, or New Relic. This allows the collection and visualization of metrics, logs, and traces – offering a unified view of system health, performance, and dependencies.
Key Takeaways
Designing microservices is not just about cutting an app into smaller pieces. It’s about:
- Clear responsibilities: one service, one domain.
- Strong boundaries: each service owns its database.
- Loosely coupled communication: APIs or events, never direct DB access.
- Observability and control: service mesh, distributed tracing, monitoring.
When you combine these principles, you get a system that’s not only scalable and flexible, but also resilient – able to handle growth, change, and even failure with grace.
Closing Thought
Building microservices is like running a city. If each building is solid and the infrastructure keeps traffic flowing, the whole city thrives. If not, even the smallest hiccup can turn into gridlock.
So, the next time you’re designing a service, ask yourself:
➡️ Am I making this service independent enough to stand on its own, yet open enough to work well with others?
What challenges have you faced with service dependencies in your projects? Share your experience in the comments below!