



Introduction
Imagine you’re building a very big application made up of thousands of small, interconnected codebases. Now, think about what would happen if one of those codebases or programs suddenly malfunctioned. In the world of computer programming, where complex systems are built from numerous smaller parts, this scenario is not too far from reality.
In this blog, we’re going to explore a concept called “Fault Tolerance and Resilience” in a framework called Akka. Think of Akka as a powerful toolkit that helps developers build really smart, efficient and distributed systems. But what’s unique about Akka is its ability to handle problems or “faults” that might pop up unexpectedly.
So, what exactly do we mean by fault tolerance and resilience? Well, imagine we’re watching a movie online, and suddenly the internet gets disconnected. We’d expect the movie to pause for a moment and then continue playing once the connection is restored. That’s fault tolerance – the system’s ability to handle errors without crashing entirely.
Resilience is like a superhero’s ability to quickly recover from a fall. If your favourite website goes down because too many people are trying to visit it at once, but then it comes back up without losing any information, that’s resilience in action.
How it Works in Akka
In Akka, supervision and fault tolerance are like the superheroes of the system, keeping everything running smoothly even when things go wrong. Think of supervision as a manager overseeing a team, making sure everyone’s doing their job well. If one team member (or actor) runs into a problem, the manager steps in to help. Fault tolerance is like having backup plans in place so that if something breaks, the system can keep going without crashing. It’s like having repair bots ready to fix any broken parts of a robot, ensuring it can still do its job effectively. So, in Akka, supervision and fault tolerance work together to make sure the system stays strong and reliable, even in tough situations.
Supervision in Akka
In simpler terms, supervision in Akka is like being a manager overseeing a team of workers. When one of our team members encounter a problem, they let us know, and it’s up to us to decide what to do. We have four options:
Resume: We let the team member keep working, without losing any progress.
Restart: We give the team member a fresh start, clearing any mistakes they’ve made.
Stop: We decide it’s best for the team member to stop working permanently.
Escalate: If we can’t handle the problem, we pass it on to someone higher up.
Each manager (or supervisor) has a plan for how to handle these situations, but it’s important to remember that every team member is part of a bigger picture. If one team member fails, it can affect the others. So, the decisions need to be made carefully.
In Akka, this supervision happens automatically, with each actor (or team member) which is being looked after by its parent. This setup ensures that problems are dealt with efficiently and that the whole system runs smoothly.
Akka Actor Hierarchy
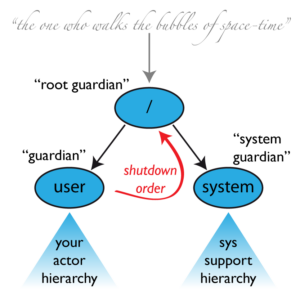
In Akka, there are special guardians that manage different parts of the system:
- /user: This guardian oversees all user-created actors. When it shuts down, all normal actors in the system also shut down. Its supervisor strategy determines how top-level normal actors are managed.
- /system: The System Guardian ensures a smooth shutdown sequence while keeping logging active. It watches over the user guardian and initiates system shutdown when it receives a termination message. System actors are supervised to restart indefinitely upon most exceptions, except for a couple which cause termination.
- /: The Root Guardian is like the top boss, overseeing all other guardians and actors. It supervises top-level actors using a strategy that terminates them upon any exception. If any trouble arises, it takes action to stop the affected actor and ensures the system is terminated properly.
Understanding Fault Tolerance in Akka
In Akka, Fault tolerance is achieved through the Supervision strategies but first let’s understand the Fault tolerance with one more example.
Imagine we’re building a robot, and this robot has different parts that need to work together smoothly. Now, let’s say one of those parts suddenly stops working, like a motor or a sensor. In traditional systems, this might cause the whole robot to shut down or behave abnormally.
But with Akka, it’s like having a team of repair bots constantly watching over our main robot. When one of its parts breaks, instead of the whole robot crashing, these repair bots come in, fix the broken part, and get the robot back in working state. So, even if something goes wrong or down, our robot keeps working fine which minimize downtime and ensuring it can still perform its tasks effectively.
So, fault tolerance in Akka is about building systems that can handle problems gracefully, keeping everything running smoothly even when things don’t go according to plan.
To achieve the Fault tolerance in our system we use the Supervision strategies.
One-for-One Strategy
In this strategy, if one actor encounters a problem or fails, only that specific actor is affected. The supervisor (manager actor) intervenes and address the issue with that particular actor, while the other actors continue their work undisturbed. It’s like fixing a glitch or a problem in one part of a machine without stopping the entire production line.
import akka.actor.OneForOneStrategy
import akka.actor.SupervisorStrategy._
import scala.concurrent.duration._
override val supervisorStrategy =
OneForOneStrategy(maxNrOfRetries = 10, withinTimeRange = 1 minute) {
case _: ArithmeticException => Resume
case _: NullPointerException => Restart
case _: IllegalArgumentException => Stop
case _: Exception => Escalate
} All-for-One Strategy
With this approach, if one actor fails or experiences difficulties, the supervisor applies the strategy to all the actors under its supervision. This means that when one actor encounters a problem, the supervisor may decide to stop, restart, or take other actions that impact all actors. It’s like to resetting the entire system when one component malfunctions to ensure that everything operates smoothly again.
import akka.actor.AllForOneStrategy
import akka.actor.SupervisorStrategy._
import scala.concurrent.duration._
override val supervisorStrategy =
AllForOneStrategy(maxNrOfRetries = 10, withinTimeRange = 1 minute) {
case _: ArithmeticException => Resume
case _: NullPointerException => Restart
case _: IllegalArgumentException => Stop
case _: Exception => Escalate
}Implementing Supervision Strategies in Akka Actors
import SupervisorExample.Supervisor.{DIVIDE, MULTIPLY}
import akka.actor.{Actor, ActorSystem, Props}
import scala.language.postfixOps
object SupervisorExample extends App {
object Supervisor {case object DIVIDE
case object MULTIPLY
}
class Supervisor extends Actor {
import akka.actor.OneForOneStrategy
import akka.actor.SupervisorStrategy._
import scala.concurrent.duration._
// Define supervision strategy
override val supervisorStrategy =
OneForOneStrategy(maxNrOfRetries = 10, withinTimeRange = 1 minute) {
case _: ArithmeticException => Resume
case _: NullPointerException => Restart
case _: IllegalArgumentException => Stop
case _: Exception => Escalate
}
val childActor = context.actorOf(Props[ChildActor], "child")
// Create child actor upon receiving DIVIDE message
override def receive: Receive = {
case DIVIDE => childActor ! DIVIDE
case MULTIPLY => childActor ! MULTIPLY
}
}
class ChildActor extends Actor {
import SupervisorExample.Supervisor
// Handle DIVIDE message and cause division by zero exception
def receive: Receive = {
case DIVIDE => val num = 10 / 0
case MULTIPLY => val mul = 10 * 2
println(mul)
}
}
// Create actor system and supervisor actor
val actorSystem = ActorSystem("MySystem")
val supervisorActor = actorSystem.actorOf(Props[Supervisor], "supervisorActor")
// Send DIVIDE message to trigger exception
supervisorActor ! DIVIDE
Thread.sleep(4000)
supervisorActor ! MULTIPLY
} (Note: Don't use the Thread.sleep() in real scenario as it is a blocking operation)
Code Explanation
We have two types of actors: Supervisor and ChildActor. The Supervisor oversees the ChildActor and defines a supervision strategy to handle different types of exceptions that may occur in the ChildActor.
When the Supervisor receives a message to DIVIDE or MULTIPLY, it forwards that message to the ChildActor.
The ChildActor is responsible for performing the actual calculations. When it receives a DIVIDE message, it tries to divide 10 by 0, which will cause an ArithmeticException. When it receives a MULTIPLY message, it multiplies 10 by 2 and prints the result.
The Supervisor’s supervision strategy specifies how to handle exceptions thrown by the ChildActor. In this example, it’s set to resume execution if an ArithmeticException occurs, restart the ChildActor if a NullPointerException occurs, stop the ChildActor permanently if an IllegalArgumentException occurs, and escalate any other type of exception to its parent for further handling.
Finally, the code creates an ActorSystem and starts a Supervisor actor. It then sends a DIVIDE message to trigger an exception and waits for 4 seconds before sending a MULTIPLY message to demonstrate how the supervision strategy will resume the program even when the ArithmeticException arises.
Conclusion
In simple terms, Akka’s supervision strategies act like watchful managers, ensuring that when something goes wrong in a big system, it doesn’t cause a complete shutdown. Instead, they help fix problems quickly, so everything can keep running smoothly. This way, even if there’s a mishappening, the system can bounce back without causing too much trouble.
References
https://doc.akka.io/docs/akka/current/supervision-classic.html
https://doc.akka.io/docs/akka/current/fault-tolerance.html
Recommended Reads