



Great Expectations (GX) is a powerful open-source tool for data validation and profiling, offering engineers a framework to maintain data quality. Setting expectations or rules helps to spot issues and ensure that your data meets predefined criteria.
With its flexibility and integration capabilities, Great Expectations is a valuable asset for enhancing data reliability and decision-making in analytics. This can prove to be a great asset in machine learning as well.
Installation and Setup
Before moving ahead, there are some criteria that need to be met first.
- Python 3.6 or above
- Basic understanding of Python
- Basic understanding of Jupyter Notebooks.
- And a web browser, of course.
Note: We recommend using a local development environment for Python 3.6 or above
To begin, open the terminal and install the GX (Great Expectations) package using the pip command.
python3 -m pip install great_expectationsOnce done, verify if it has been successfully installed.
great_expectations –version
What are Expectations in GX?
Expectations are the fundamental building blocks that allow you to define specific rules or constraints for your data. These rules serve as a set of criteria against which your data is evaluated. Expectations articulate what you expect your data to look like, and they can encompass a wide range of conditions and constraints.
What is Data Profiling in GX?
Great Expectations automates data profiling by generating descriptive statistics, histograms, and frequency distributions, helping users with insights into data distributions and quality. Moreover, it also allows for the validation of data types and the analysis of null values, ensuring a comprehensive understanding of the dataset’s characteristics. Additionally, custom profiling metrics can be defined to meet specific dataset requirements.
How to test your data using GX?
For this blog, we will be using a CSV file as our data source containing a large dummy data inside it. Once we have the great expectation installed, we can use the following command to initialise the project.
great_expectations initYou’ll see something like this on your terminal.
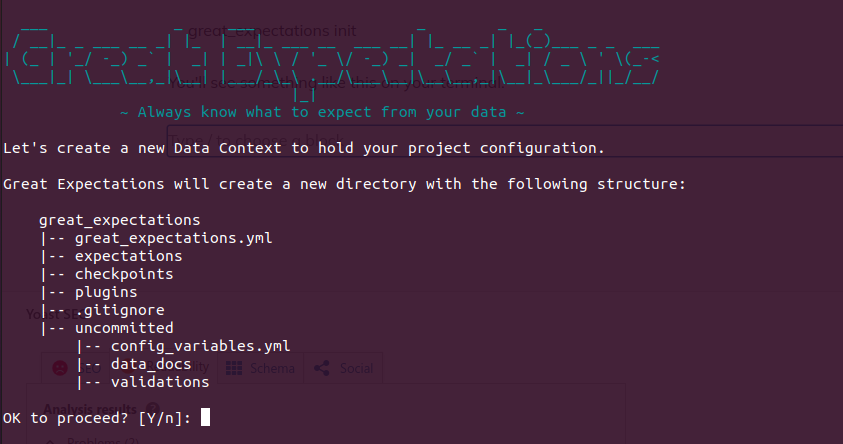
We can proceed with Yes (Y) here.
Adding DataSource in GX
Once done, execute the following command.
great_expectations datasource newYou will be having something like this on your screens.
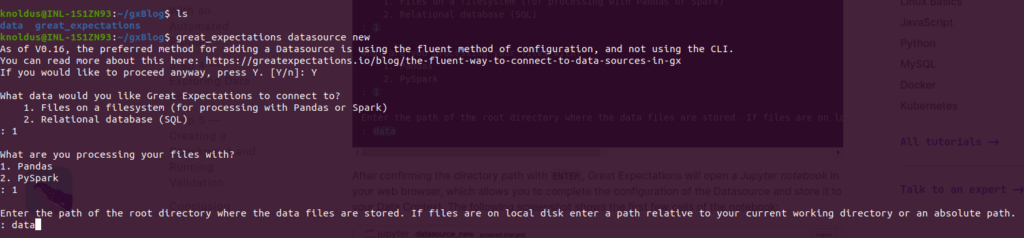
You may follow the same steps that I’ve followed.
At last, you’ll be asked about the directory where your data files are. Since I’ve placed them inside the data folder, I’ve responded with the same.
Afterwards, the system will direct you to your default browser, and a Jupyter Notebook will automatically open.
In the next step, we will use the CSV files in your Datasource to automatically generate Expectations with a profiler after successfully setting up a Datasource that points to the data directory, enabling access to the CSV files in the directory through Great Expectations.
NOTE: Make sure to run all cells in the Jupyter Notebook before you close it. Otherwise, your data source configuration will not be saved.
Creating Expectations Suite with a Profiler
We will use the built-in Profiler to create a set of Expectations based on existing data.
Let’s begin by creating an Expectation Suite, which is a collection of Expectations (data assertions) based on specific properties.
Please execute the following command.
great_expectations suite newOnce done, please follow the steps mentioned in the screenshot below.
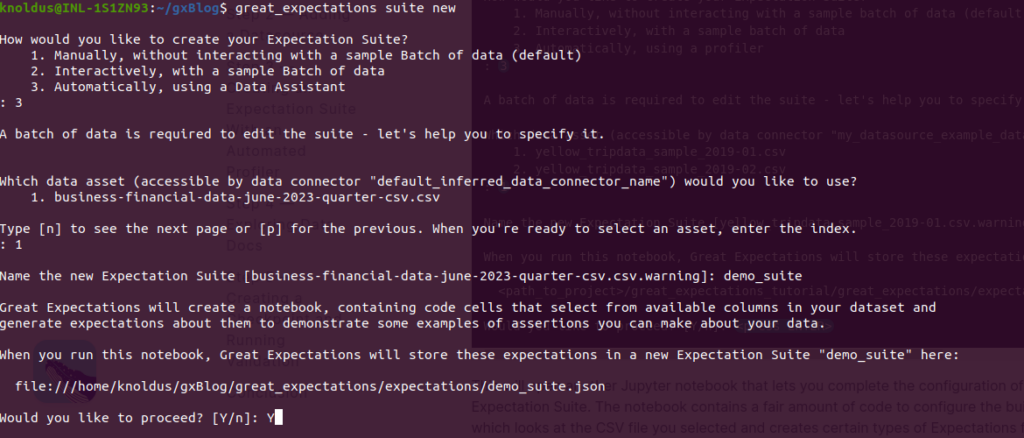
Opening another Jupyter notebook allows you to finalize the configuration of your Expectation Suite. In this notebook, you will encounter a substantial amount of code used to configure the built-in profiler. This profiler analyzes the selected CSV file and automatically generates specific types of Expectations for each column based on the data it discovers.
Navigate to the second code cell in the notebook, where you’ll find a list of ignored_columns. By default, all columns are ignored by the profiler. To ensure the profiler creates Expectations for specific columns, uncomment and modify the code as shown below:
Commenting out the columns Series_reference, Period, Data_value, and Suppressed instructs the profiler to generate Expectations for these specific columns. Furthermore, the profiler will automatically create table-level Expectations, including information about the number and names of columns and the total number of rows in your data. To proceed, execute all cells in the notebook by selecting the “Cell” menu and choosing “Run All.”
For your reference, the CSV file that I’m using looks something like this.

When you execute all cells in this notebook, two significant actions occur:
- The code generates an Expectation Suite by utilizing the automated profiler, and it utilizes the CSV file as you specified.
- Additionally, the final cell in the notebook is set up to perform validation and initiate a new browser window to display Data Docs, a comprehensive data quality report.
Understanding Data Docs
We’ll examine the Data Docs generated by Great Expectations and acquire an understanding of how to interpret the various elements of information. Please navigate to the newly opened browser window and review the page, as illustrated in the screenshot below.
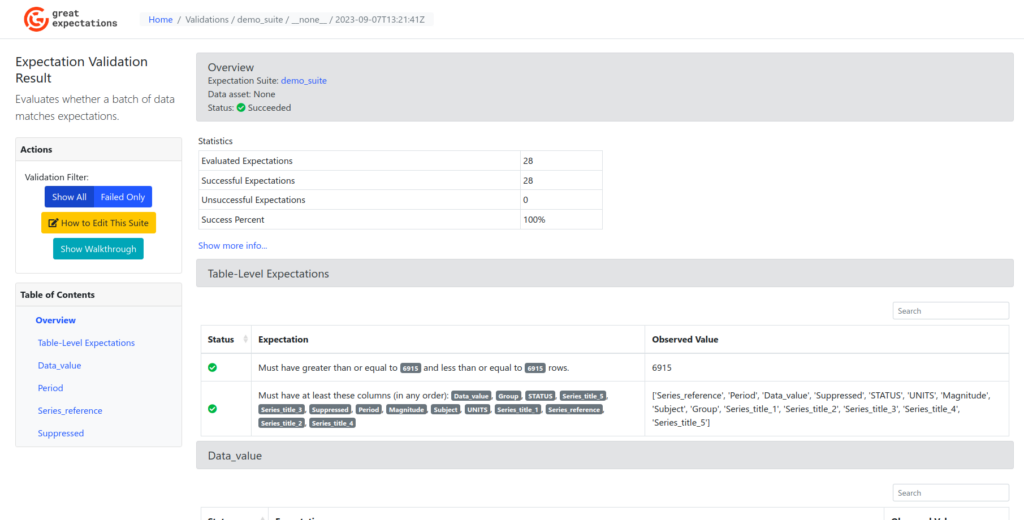
At the top of the page, you’ll find a box labelled “Overview,” providing information about the validation conducted with your newly created Expectation Suite, named “my_suite.” Here, you will observe a “Status: Succeeded” indication along with basic statistics regarding the number of Expectations executed. As you scroll down, a section named “Table-Level Expectations” will become visible, featuring two rows of Expectations. Each row displays the “Status,” “Expectation,” and “Observed Value.” Below the table Expectations, you’ll encounter column-specific Expectations for each of the columns you previously addressed in the notebook.
Conclusion
In practice, we applied Great Expectations to a CSV file, demonstrating the practicality of data profiling and quality checks. This showcased how Great Expectations automatically generated insightful data profiles and identified data quality issues, providing a hands-on illustration of its effectiveness in ensuring data reliability and integrity. For more blogs, on such tech stack, please visit our site.
References
- https://docs.greatexpectations.io/docs/tutorials/quickstart/