


Introduction
In the realm of modern data processing and real-time analytics, event streaming has emerged as a powerful paradigm. Apache Kafka stands out as a robust, distributed streaming platform capable of handling large volumes of data in real-time. Here, we will delve into the consumer side of implementing Kafka for event streaming, exploring its key concepts, setup, and practical considerations.
Understanding Kafka Consumers
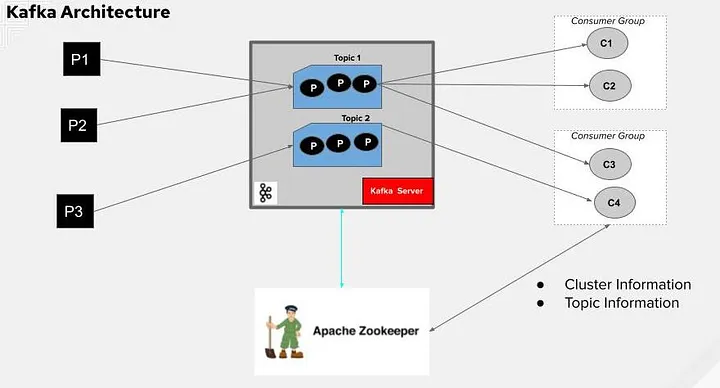
In Kafka, consumers are applications that read data from Kafka topics. They play a crucial role in the event-driven architecture by processing and reacting to events published by producers. Here’s a breakdown of essential concepts related to Kafka consumers:
- Consumer Groups: Consumers are organized into groups to parallelize processing and scale horizontally. Each group can have multiple consumers, and each consumer within a group processes a subset of partitions for the topics it subscribes to.
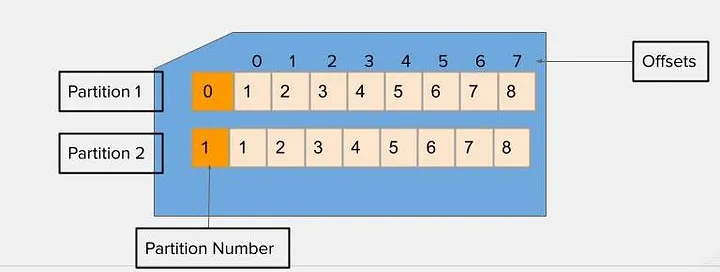
- Offsets: Kafka maintains a committed offset for each consumer group, which represents the position of the consumer in each partition. This allows consumers to resume from where they left off in case of failures or restarts.
- Polling Model: Consumers use a polling model to fetch records from Kafka brokers. They periodically poll for new messages, and the rate of polling can be adjusted based on the processing capacity of the consumer application.
Setting up Kafka consumer
Implementing a Kafka consumer involves several steps, from setting up the environment to writing the actual consumer application code. Here’s a high-level overview:
Environment setup
- Kafka Broker: Ensure you have Kafka installed and running. This includes ZooKeeper, which Kafka uses for cluster coordination.
- Consumer Configuration: Define properties such as Kafka broker addresses, consumer group ID, and serialization settings (e.g., for JSON or Avro data formats).
Writing the Consumer application
Consumer API: Use the Kafka Consumer API (available in various programming languages like C#, Java, Python, and others) to subscribe to topics and process messages.
using Confluent.Kafka;
using System;
using System.Threading;
class Program
{
static void Main(string[] args)
{
var config = new ConsumerConfig
{
BootstrapServers = "localhost:9092", // Replace with your Kafka broker(s)
GroupId = "test-consumer-group",
AutoOffsetReset = AutoOffsetReset.Earliest, // Start consuming from the beginning of the topic
};
using (var consumer = new ConsumerBuilder<Ignore, string>(config).Build())
{
consumer.Subscribe("test-topic");
CancellationTokenSource cts = new CancellationTokenSource();
Console.CancelKeyPress += (_, e) => {
e.Cancel = true; // Prevent the process from terminating.
cts.Cancel();
};
try
{
while (true)
{
var consumeResult = consumer.Consume(cts.Token);
Console.WriteLine($"Consumed message: {consumeResult.Message.Value}");
}
}
catch (OperationCanceledException)
{
// Ensure the consumer leaves the group cleanly and final offsets are committed.
consumer.Close();
}
}
}
}
Processing Logic : Inside the while loop, call Consume() to fetch messages from Kafka.Process the message (consumeResult.Message.Value in this example) as per application’s logic.
Handling Consumer Scaling and Fault Tolerance
- Partition Assignment: Kafka ensures that each consumer in a group gets a fair share of partitions for the subscribed topics. Scaling out involves adding more consumers to handle higher message throughput.
- Fault Tolerance: Consumers should be resilient to failures by committing offsets periodically and handling exceptions gracefully. Kafka ensures that failed consumers can be replaced without losing data.
Conclusion
Implementing Kafka for event streaming on the consumer side involves understanding Kafka’s core concepts, setting up the environment, and developing robust consumer applications. By leveraging Kafka’s scalability, fault tolerance, and real-time capabilities, organizations can build resilient and responsive systems for processing streaming data.
In upcoming posts, we will explore advanced topics such as stream processing with Kafka Streams and integrating Kafka with other data systems. Stay tuned for more insights into harnessing the power of Kafka for modern data architectures.